This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary: DeepLearning models revolutionise data processing, solving complex image recognition, NLP, and analytics tasks. Introduction DeepLearning models transform how we approach complex problems, offering powerful tools to analyse and interpret vast amounts of data. With a projected market growth from USD 6.4
Be sure to check out his talk, “ Bagging to BERT — A Tour of Applied NLP ,” there! In this post, I’ll be demonstrating two deeplearning approaches to sentiment analysis. Deeplearning refers to the use of neural network architectures, characterized by their multi-layer design (i.e. deep” architecture).
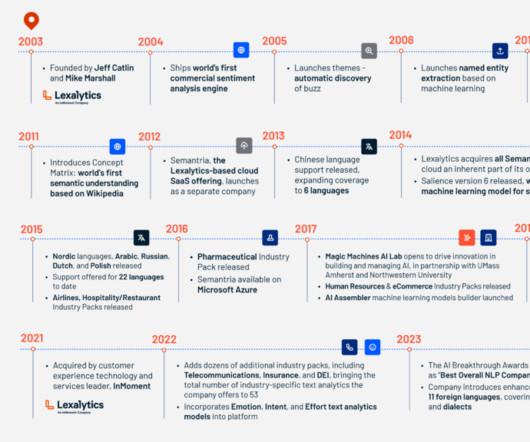
We’ve pioneered a number of industry firsts, including the first commercial sentiment analysis engine, the first Twitter/microblog-specific text analytics in 2010, the first semantic understanding based on Wikipedia in 2011, and the first unsupervised machine learning model for syntax analysis in 2014.
of nodes with text-features MAG 484,511,504 7,520,311,838 4/4 28,679,392 1,313,781,772 240,955,156 We benchmark two main LM-GNN methods in GraphStorm: pre-trained BERT+GNN, a baseline method that is widely adopted, and fine-tuned BERT+GNN, introduced by GraphStorm developers in 2022. Dataset Num. of nodes Num. of edges Num.
Uysal and Gunal, 2014). binary_classifier_interlocutor.ipynb” file stores our binary classifier which uses ensemble learning to classify if a text was uttered by the therapist or the client while “binary_classifier_quality.ipynb” determines if the overall conversation between a therapist and client is of high quality or low quality.
DeepLearning (Late 2000s — early 2010s) With the evolution of needing to solve more complex and non-linear tasks, The human understanding of how to model for machine learning evolved. 2014) Significant people : Geoffrey Hinton Yoshua Bengio Ilya Sutskever 5. 2018) “ Language models are few-shot learners ” by Brown et al.
They were not wrong: the results they found about the limitations of perceptrons still apply even to the more sophisticated deep-learning networks of today. And indeed we can see other machine learning topics arising to take their place, like “optimization” in the mid-’00s, with “deeplearning” springing out of nowhere in 2012.
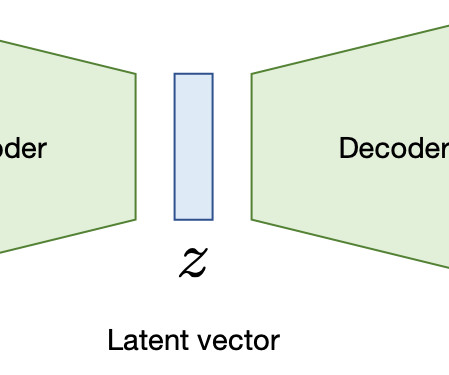
A few embeddings for different data type For text data, models such as Word2Vec , GLoVE , and BERT transform words, sentences, or paragraphs into vector embeddings. However, it was not designed for transfer learning and needs to be trained for specific tasks using a separate model. What are Vector Embeddings?
GANs, introduced in 2014 paved the way for GenAI with models like Pix2pix and DiscoGAN. Prompt Engineering Platforms LLM Platforms: ChatGpt, GPT-4, LLama 2, Stable Diffusion, and BERT ChatGPT OpenAI’s ChatGPT was one of the most popular apps in history, so it’s no surprise that the suite of API models including GPT-3.5
See in app Full screen preview Check the documentation Play with an interactive example project Get in touch to go through a custom demo with our engineering team Cyclical cosine schedule Returning to a high learning rate after decaying to a minimum is not a new idea in machine learning. validation loss).
Research models such as BERT and T5 have become much more accessible while the latest generation of language and multi-modal models are demonstrating increasingly powerful capabilities. This post is partially based on a keynote I gave at the DeepLearning Indaba 2022. The DeepLearning Indaba 2022 in Tunesia.
Articles Quantization in deeplearning refers to the process of reducing the precision of the numbers used to represent the model's parameters and activations. Typically, deeplearning models use 32-bit floating-point numbers (float32) for computations. million per year in 2014 currency) in Shanghai.
The rise of NLP in the past decades is backed by a couple of global developments – the universal hype around AI, exponential advances in the field of DeepLearning and an ever-increasing quantity of available text data. This is especially relevant for the advanced, complex algorithms of the DeepLearning family.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content