

Enrich your AWS Glue Data Catalog with generative AI metadata using Amazon Bedrock
NOVEMBER 15, 2024
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.

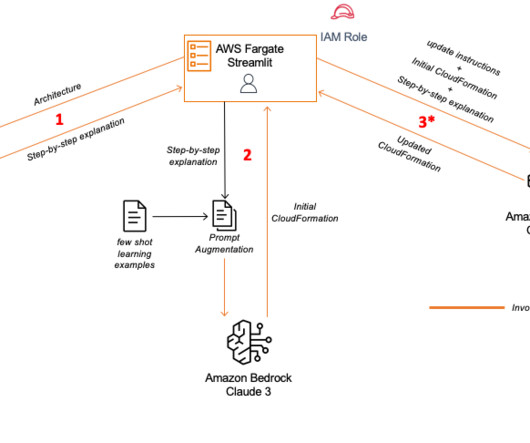


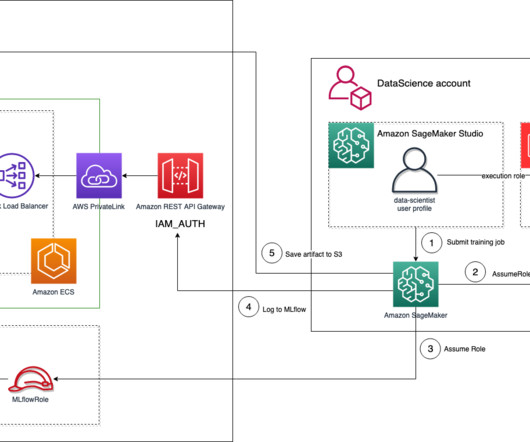



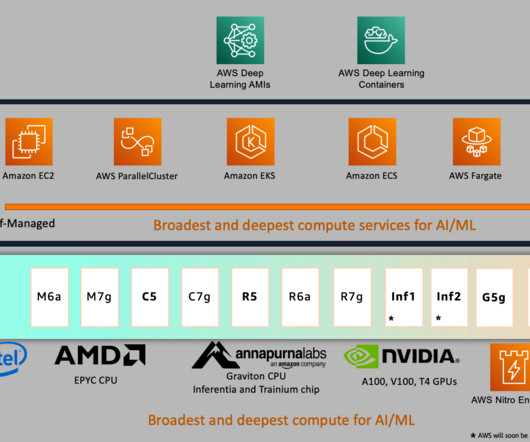










Let's personalize your content