

Making Sense of the Mess: LLMs Role in Unstructured Data Extraction
Unite.AI
MAY 29, 2024
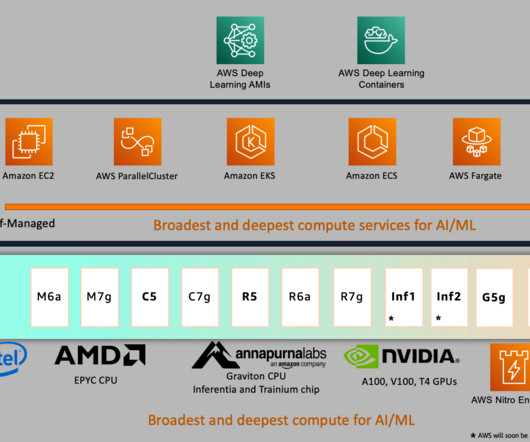
With nine times the speed of the Nvidia A100, these GPUs excel in handling deep learning workloads. Source: A pipeline on Generative AI This figure of a generative AI pipeline illustrates the applicability of models such as BERT, GPT, and OPT in data extraction.












Let's personalize your content