This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Python Ray is a dynamic framework revolutionizing distributed computing. Developed by UC Berkeley’s RISELab, it simplifies parallel and distributed Python applications. Ray streamlines complex tasks for MLengineers, data scientists, and developers. appeared first on Analytics Vidhya.
Amazon SageMaker has redesigned its Python SDK to provide a unified object-oriented interface that makes it straightforward to interact with SageMaker services. We show you how to use the ModelTrainer class to train your ML models, which includes executing distributed training using a custom script or container.
How much machine learning really is in MLEngineering? But what actually are the differences between a Data Engineer, Data Scientist, MLEngineer, Research Engineer, Research Scientist, or an Applied Scientist?! Data engineering is the foundation of all ML pipelines. It’s so confusing!
What are the most important skills for an MLEngineer? Well, I asked MLengineers at all these companies to share what they consider the top skills… And I’m telling you, there were a lot of answers I received and I bet you didn’t even think of many of them! And the answer here quite often is… Not so much, really.
With access to a wide range of generative AI foundation models (FM) and the ability to build and train their own machine learning (ML) models in Amazon SageMaker , users want a seamless and secure way to experiment with and select the models that deliver the most value for their business.
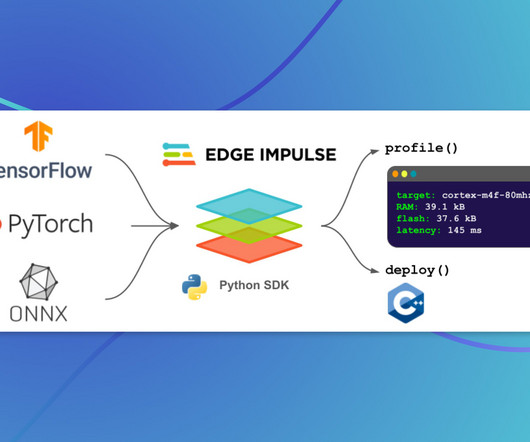
Last Updated on April 4, 2023 by Editorial Team Introducing a Python SDK that allows enterprises to effortlessly optimize their ML models for edge devices. With their groundbreaking web-based Studio platform, engineers have been able to collect data, develop and tune ML models, and deploy them to devices.
This article was published as a part of the Data Science Blogathon Introduction Working as an MLengineer, it is common to be in situations where you spend hours to build a great model with desired metrics after carrying out multiple iterations and hyperparameter tuning but cannot get back to the same results with the […].
Image designed by the author – Shanthababu Introduction Every MLEngineer and Data Scientist must understand the significance of “Hyperparameter Tuning (HPs-T)” while selecting your right machine/deep learning model and improving the performance of the model(s). This article was published as a part of the Data Science Blogathon.
A sensible proxy sub-question might then be: Can ChatGPT function as a competent machine learning engineer? The Set Up If ChatGPT is to function as an MLengineer, it is best to run an inventory of the tasks that the role entails. ChatGPT’s job as our MLengineer […]
Amazon SageMaker is a cloud-based machine learning (ML) platform within the AWS ecosystem that offers developers a seamless and convenient way to build, train, and deploy ML models. He focuses on architecting and implementing large-scale generative AI and classic ML pipeline solutions.
It includes three self-paced courses covering generative AI basics, prompt engineering, and tools like GitHub Co-pilot and ChatGPT, with hands-on projects to apply skills in real-world scenarios. AI Prompt Engineering for Beginners This course focuses on prompt engineering for AI language tools like ChatGPT.
From Solo Notebooks to Collaborative Powerhouse: VS Code Extensions for Data Science and ML Teams Photo by Parabol | The Agile Meeting Toolbox on Unsplash In this article, we will explore the essential VS Code extensions that enhance productivity and collaboration for data scientists and machine learning (ML) engineers.
With that, the need for data scientists and machine learning (ML) engineers has grown significantly. Data scientists and MLengineers require capable tooling and sufficient compute for their work. Data scientists and MLengineers require capable tooling and sufficient compute for their work.
In these scenarios, as you start to embrace generative AI, large language models (LLMs) and machine learning (ML) technologies as a core part of your business, you may be looking for options to take advantage of AWS AI and ML capabilities outside of AWS in a multicloud environment.
Get started with SageMaker JumpStart SageMaker JumpStart is a machine learning (ML) hub that can help accelerate your ML journey. Deploying a Falcon 3 model through SageMaker JumpStart offers two convenient approaches: using the intuitive SageMaker JumpStart UI or implementing programmatically through the SageMaker Python SDK.
In world of Artificial Intelligence (AI) and Machine Learning (ML), a new professionals has emerged, bridging the gap between cutting-edge algorithms and real-world deployment. Meet the MLOps Engineer: the orchestrating the seamless integration of ML models into production environments, ensuring scalability, reliability, and efficiency.
Data scientists and MLengineers often need help to build full-stack applications. It is a Python-based framework for data scientists and machine learning engineers. These professionals typically have a firm grasp of data and AI algorithms. This is where Taipy comes into play.
Real-world applications vary in inference requirements for their artificial intelligence and machine learning (AI/ML) solutions to optimize performance and reduce costs. SageMaker Model Monitor monitors the quality of SageMaker ML models in production. Your client applications invoke this endpoint to get inferences from the model.
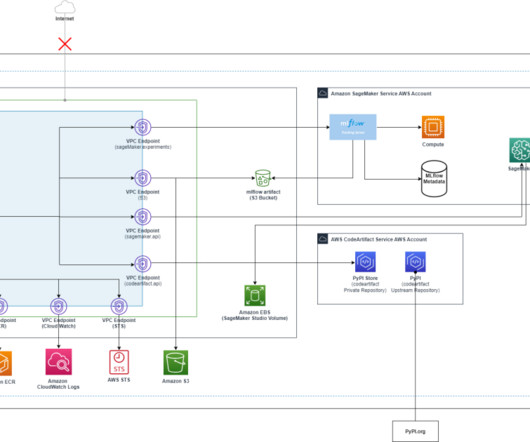
The solution described in this post is geared towards machine learning (ML) engineers and platform teams who are often responsible for managing and standardizing custom environments at scale across an organization. This approach helps you achieve machine learning (ML) governance, scalability, and standardization.
Hence for an individual who wants to excel as a data scientist, learning Python is a must. The role of Python is not just limited to Data Science. In fact, Python finds multiple applications. It’s a universal programming language that finds application in different technologies like AI, ML, Big Data and others.
When working on real-world machine learning (ML) use cases, finding the best algorithm/model is not the end of your responsibilities. Reusability & reproducibility: Building ML models is time-consuming by nature. Save vs package vs store ML models Although all these terms look similar, they are not the same.
This post presents and compares options and recommended practices on how to manage Python packages and virtual environments in Amazon SageMaker Studio notebooks. Amazon SageMaker Studio is a web-based, integrated development environment (IDE) for machine learning (ML) that lets you build, train, debug, deploy, and monitor your ML models.
Machine learning (ML), a subset of artificial intelligence (AI), is an important piece of data-driven innovation. Machine learning engineers take massive datasets and use statistical methods to create algorithms that are trained to find patterns and uncover key insights in data mining projects. What is MLOps?
FMEval is an open source LLM evaluation library, designed to provide data scientists and machine learning (ML) engineers with a code-first experience to evaluate LLMs for various aspects, including accuracy, toxicity, fairness, robustness, and efficiency. This allows you to keep track of your ML experiments.
As industries begin adopting processes dependent on machine learning (ML) technologies, it is critical to establish machine learning operations (MLOps) that scale to support growth and utilization of this technology. There were noticeable challenges when running ML workflows in the cloud.
For data scientists, moving machine learning (ML) models from proof of concept to production often presents a significant challenge. Additionally, you can use AWS Lambda directly to expose your models and deploy your ML applications using your preferred open-source framework, which can prove to be more flexible and cost-effective.
This is where Stacklock ‘s newly released Python library, Promptwright , aims to bridge the gap. Additionally, Promptwright includes a command line interface (CLI), making it convenient to execute dataset generation tasks directly from the terminal without writing additional Python scripts.
Training Sessions Bayesian Analysis of Survey Data: Practical Modeling withPyMC Allen Downey, PhD, Principal Data Scientist at PyMCLabs Alexander Fengler, Postdoctoral Researcher at Brown University Bayesian methods offer a flexible and powerful approach to regression modeling, and PyMC is the go-to library for Bayesian inference in Python.
Machine learning (ML) projects are inherently complex, involving multiple intricate steps—from data collection and preprocessing to model building, deployment, and maintenance. To start our ML project predicting the probability of readmission for diabetes patients, you need to download the Diabetes 130-US hospitals dataset.
By taking care of the undifferentiated heavy lifting, SageMaker allows you to focus on working on your machine learning (ML) models, and not worry about things such as infrastructure. Prior to working at Amazon Music, Siddharth was working at companies like Meta, Walmart Labs, Rakuten on E-Commerce centric ML Problems.
Artificial intelligence (AI) and machine learning (ML) are becoming an integral part of systems and processes, enabling decisions in real time, thereby driving top and bottom-line improvements across organizations. However, putting an ML model into production at scale is challenging and requires a set of best practices.
You can try this model with SageMaker JumpStart, a machine learning (ML) hub that provides access to algorithms and models that can be deployed with one click for running inference. Discover Pixtral 12B in SageMaker JumpStart You can access Pixtral 12B through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK.
As an MLEngineer, we are generally tasked with solving some business problem with technology. Generally, unless it is a very simple problem, there would be more than one ML model involved, maybe different types of models depending on the sub-task, maybe other supporting tools such as a Search Index
Machine learning (ML) is a subset of artificial intelligence (AI) that builds algorithms capable of learning from data. Unlike traditional programming, where rules are explicitly defined, ML models learn patterns from data and make predictions or decisions autonomously. What is Machine Learning? fraud detection).
In this post, we show you how to convert Python code that fine-tunes a generative AI model in Amazon Bedrock from local files to a reusable workflow using Amazon SageMaker Pipelines decorators. You can use Amazon SageMaker Model Building Pipelines to collaborate between multiple AI/ML teams. Create and run the SageMaker pipeline.
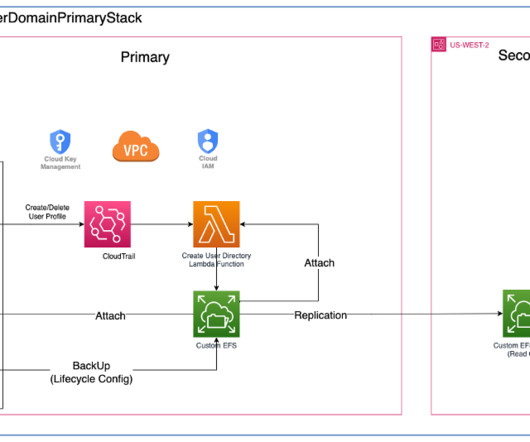
This post, part of the Governing the ML lifecycle at scale series ( Part 1 , Part 2 , Part 3 ), explains how to set up and govern a multi-account ML platform that addresses these challenges. An enterprise might have the following roles involved in the ML lifecycles. This ML platform provides several key benefits.
Its scalability and load-balancing capabilities make it ideal for handling the variable workloads typical of machine learning (ML) applications. Amazon SageMaker provides capabilities to remove the undifferentiated heavy lifting of building and deploying ML models. They often work with DevOps engineers to operate those pipelines.
in SageMaker JumpStart SageMaker JumpStart provides FMs through two primary interfaces: SageMaker Studio and the SageMaker Python SDK. SageMaker Studio is a comprehensive IDE that offers a unified, web-based interface for performing all aspects of the machine learning (ML) development lifecycle. Discover Meta SAM 2.1 Deploy Meta SAM 2.1
Creating scalable and efficient machine learning (ML) pipelines is crucial for streamlining the development, deployment, and management of ML models. Configuration files (YAML and JSON) allow ML practitioners to specify undifferentiated code for orchestrating training pipelines using declarative syntax.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + PythonML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + PythonML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
This is both frustrating for companies that would prefer making ML an ordinary, fuss-free value-generating function like software engineering, as well as exciting for vendors who see the opportunity to create buzz around a new category of enterprise software. What does a modern technology stack for streamlined ML processes look like?
Envision yourself as an MLEngineer at one of the world’s largest companies. You make a Machine Learning (ML) pipeline that does everything, from gathering and preparing data to making predictions. This is suitable for making a variety of Python applications with other dependencies being added to it at the user’s convenience.
Bringing AI into a company means you have new roles to fill (data scientist, MLengineer) as well as new knowledge to backfill in existing roles (product, ops). We know Python. All this AI stuff is Python. Their code may pass the Python interpreter, but it’s all Java constructs. How hard could it be?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









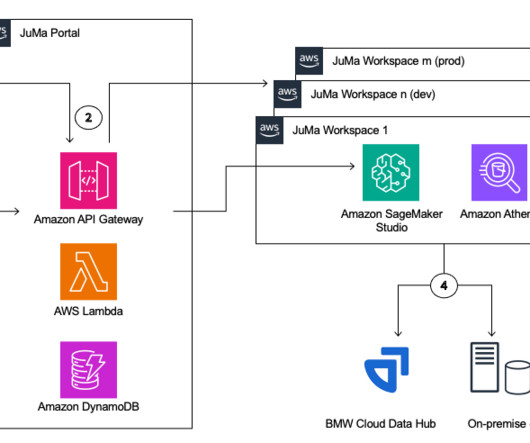
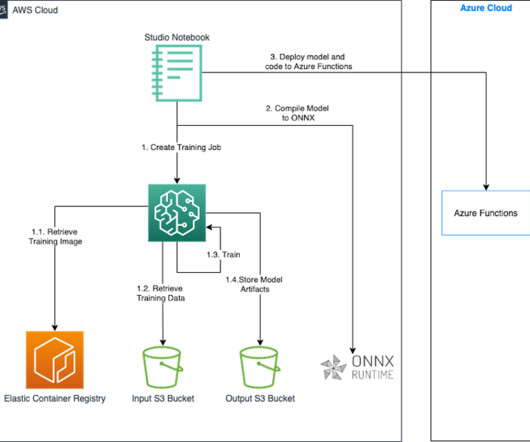







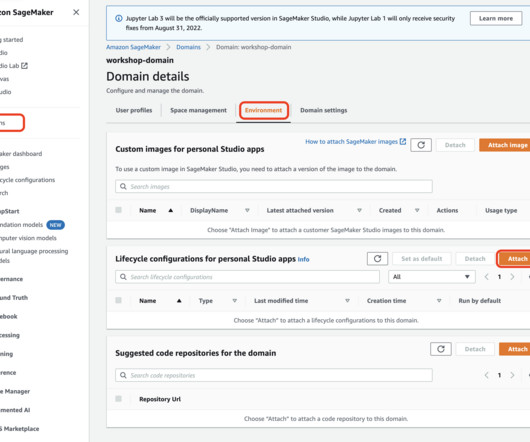






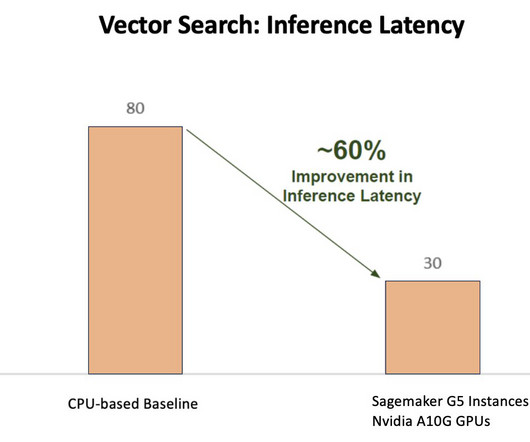







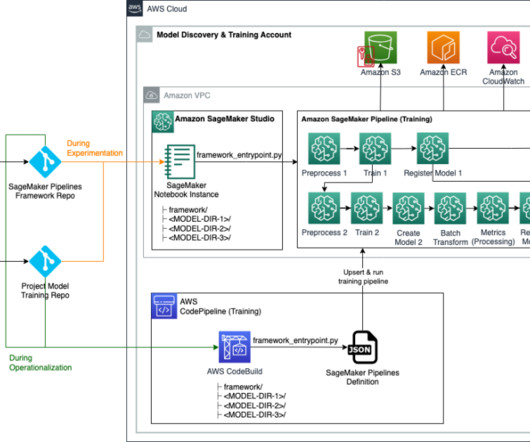











Let's personalize your content