This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It is crucial to align these different, well-meaning standards, while enabling our developers to cross silos and organizational boundaries to gain efficiencies. A developer portal like Backstage can help. Visibility and g overnance into the softwaredevelopment lifecycle through insight to project status, dependencies and more.
In the course of developing our Conformer and Universal speech recognition models , we've had to navigate the complexities of handling massive amounts of audio data and metadata. Regarding metadata storage, we chose Bigtable for several key reasons. That's where our AI Lakehouse comes in.
This enables the efficient processing of content, including scientific formulas and data visualizations, and the population of Amazon Bedrock Knowledge Bases with appropriate metadata. Generate metadata for the page. Generate metadata for the full document. Upload the content and metadata to Amazon S3.
To refine the search results, you can filter based on document metadata to improve retrieval accuracy, which in turn leads to more relevant FM generations aligned with your interests. With this feature, you can now supply a custom metadata file (each up to 10 KB) for each document in the knowledge base. Virginia) and US West (Oregon).
This solution is also deployed by using the AWS Cloud Development Kit (AWS CDK), which is an open-source softwaredevelopment framework that defines cloud infrastructure in modern programming languages and provisions it through AWS CloudFormation.
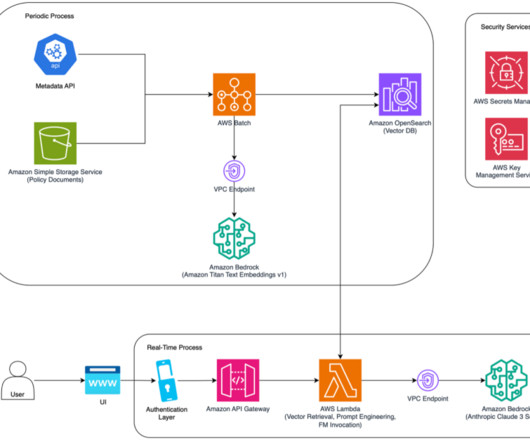
Along with each document slice, we store the metadata associated with it using an internal Metadata API, which provides document characteristics like document type, jurisdiction, version number, and effective dates. Reusability Good softwaredevelopment practices apply to the development of generative AI solutions too.
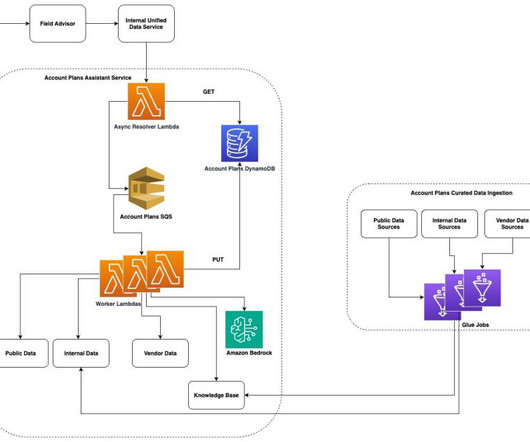
The assistant then orchestrates a multi-source data collection process, performing web searches while also pulling account metadata from OpenSearch, Amazon DynamoDB , and Amazon Simple Storage Service (Amazon S3) storage.
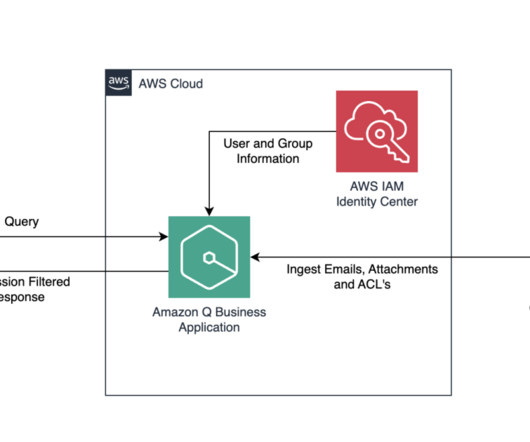
When you initiate a sync, Amazon Q will crawl the data source to extract relevant documents, then sync them to the Amazon Q index, making them searchable After syncing data sources, you can configure the metadata controls in Amazon Q Business. An Amazon Q Business index has fields that you can map your document attributes to.
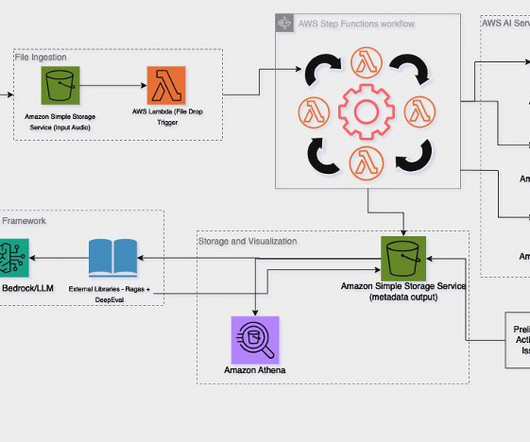
The evaluation framework, call metadata generation, and Amazon Q in QuickSight were new components introduced from the original PCA solution. Ragas and a human-in-the-loop UI (as described in the customer blogpost with Tealium) were used to evaluate the metadata generation and individual call Q&A portions.
When using the FAISS adapter, translation units are stored into a local FAISS index along with the metadata. You can enhance this technique by using metadata-driven filtering to collect the relevant pairs according to the source text. The request is sent to the prompt generator. Cohere Embed supports 108 languages.
For this demo, weve implemented metadata filtering to retrieve only the appropriate level of documents based on the users access level, further enhancing efficiency and security. The role information is also used to configure metadata filtering in the knowledge bases to generate relevant responses.
The connector supports the crawling of the following entities in Gmail: Email – Each email is considered a single document Attachment – Each email attachment is considered a single document Additionally, supported custom metadata and custom objects are also crawled during the sync process.
You can also supply a custom metadata file (each up to 10 KB) for each document in the knowledge base. You can apply filters to your retrievals, instructing the vector store to pre-filter based on document metadata and then search for relevant documents. Reranking allows GraphRAG to refine and optimize search results.
of the SageMaker ACK Operators adds support for inference components , which until now were only available through the SageMaker API and the AWS SoftwareDevelopment Kits (SDKs). These controllers allow Kubernetes users to provision AWS resources like buckets, databases, or message queues simply by using the Kubernetes API.
Monitoring and optimizing application performance is important for softwaredevelopers and enterprises at large. SDKs: Softwaredevelopment kits are tools for building software. They include the framework, code libraries and debuggers that are the building blocks of softwaredevelopment.
It stores models, organizes model versions, captures essential metadata and artifacts such as container images, and governs the approval status of each model. About the Authors Alston Chan is a SoftwareDevelopment Engineer at Amazon Ads. Outside of work, he enjoys game development and rock climbing.
Additionally, they want access to metadata, timestamps, and access control lists (ACLs) for the indexed documents. Crawling stage The first stage is the crawling stage, where the connector crawls all documents and their metadata from the data source. The following diagram shows a flowchart of a sync run job.
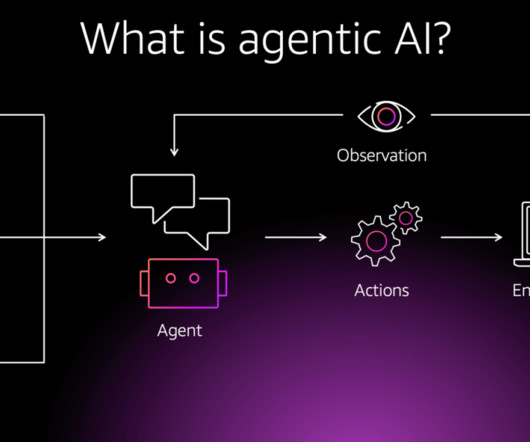
Consider a softwaredevelopment use case AI agents can generate, evaluate, and improve code, shifting software engineers focus from routine coding to more complex design challenges. Agentic systems, on the other hand, are designed to bridge this gap by combining the flexibility of context-aware systems with domain knowledge.
It also enables economies of scale with development velocity given that over 75 engineers at Octus already use AWS services for application development. This includes file type verification, size validation, and metadata extraction before routing to Amazon Textract.
In AWS, these model lifecycle activities can be performed over multiple AWS accounts (for example, development, test, and production accounts) at the use case or business unit level. It also helps achieve data, project, and team isolation while supporting softwaredevelopment lifecycle best practices. Madhubalasri B.
A document is a collection of information that consists of a title, the content (or the body), metadata (data about the document) and access control list (ACL) information to make sure answers are provided from documents that the user has access to. Amazon Q supports the crawling and indexing of these custom objects and custom metadata.
It automatically keeps track of model artifacts, hyperparameters, and metadata, helping you to reproduce and audit model versions. Ashish has extensive experience in Enterprise IT architecture and softwaredevelopment including AI/ML and generative AI. SageMaker Pipelines can handle model versioning and lineage tracking.
Developers would rely on it to define project metadata, dependencies, and installation instructions. ', py_modules=['my_module'], # Other metadata.) ', packages=['my_package'], install_requires=[ 'requests', 'numpy', ], # Other metadata.) Traditionally, setup.py
OpsLevel OpsLevel takes a unique approach to internal developer platforms by focusing on creating a comprehensive service catalog and enhancing the efficiency of high-performing engineering teams. What distinguishes Coherence is its holistic approach to the development process.
Additionally, you might need access to metadata, timestamps, and access control lists (ACLs) for the indexed documents. Crawling stage The first stage is the crawling stage, where the connector crawls all documents and their metadata from the data source. The following diagram shows a flowchart of a sync run job.
Sovereign Cloud, Generative AI Complying with regulations governing how data and metadata can be stored in cloud computing is critical. As a regional CSP, Scaleway also provides sovereign infrastructure that ensures access and compliance with EU data protection laws — critical to businesses with a European footprint.
We use HuggingFaces Optimum-Neuron softwaredevelopment kit (SDK) to apply LoRA to fine-tuning jobs, and use SageMaker HyperPod as the primary compute cluster to perform distributed training on Trainium. First, create the Python file, touch consolidation.py and shell file, touch consolidation.sh using the following code.
Omniverse is a platform of application programming interfaces, softwaredevelopment kits and services that enable developers to easily integrate OpenUSD and NVIDIA RTX rendering technologies into existing software tools and simulation workflows.
Any.metadata.json file and access control list (ACL) file is considered metadata for the object it’s associated with and not treated as a separate document. In this example, metadata files including the ACLs are in a folder named Meta. To learn more about ACLs using metadata files, see Amazon S3 document metadata.
You then format these pairs as individual text files with corresponding metadata JSON files , upload them to an S3 bucket, and ingest them into your cache knowledge base. Chaithanya Maisagoni is a Senior SoftwareDevelopment Engineer (AI/ML) in Amazons Worldwide Returns and ReCommerce organization.
The core work of developing a news story revolves around researching, writing, and editing the article. However, when the article is complete, supporting information and metadata must be defined, such as an article summary, categories, tags, and related articles. Storm CMS also gives journalists suggestions for article metadata.
Solution overview The LMA sample solution captures speaker audio and metadata from your browser-based meeting app (as of this writing, Zoom and Chime are supported), or audio only from any other browser-based meeting app, softphone, or audio source. Inventory list of meetings – LMA keeps track of all your meetings in a searchable list.
Model lineage and provenance – To track the lineage and provenance of each model version, including information about the training data, hyperparameters, model architecture, and other relevant metadata that describes the model’s origin and characteristics. The following example describes usage and cost per model per tenant in Athena.
Companies can use LLM-MA systems for several use cases, including softwaredevelopment, hardware simulation, game development (specifically, world development), scientific and pharmaceutical discoveries, capital management processes, financial and trading economy, etc.
To learn about these possibilities and more, refer to the Amazon Kendra Developer Guide. Solutions Architect with over 20 years of experience in the software industry. Gunwant Walbe is a SoftwareDevelopment Engineer at Amazon Web Services. About the Authors Jiten Dedhia is a Sr.
With Amazon Q Business Insights, administrators can diagnose potential issues such as unclear user prompts, misconfigured topics and guardrails, insufficient metadata boosters, or inadequate data source configurations. Guillermo has developed a keen interest in serverless architectures and generative AI applications.
Sean Azlin is a Principal SoftwareDevelopment Engineer at OfferUp, focused on leveraging technology to accelerate innovation, decrease time-to-market, and empower others to succeed and thrive. He has a specialization in machine learning and generative AI.
Among those algorithms, deep/neural networks are more suitable for e-commerce forecasting problems as they accept item metadata features, forward-looking features for campaign and marketing activities, and – most importantly – related time series features. She has 12 years of softwaredevelopment and architecture experience.
Each of these Lambda functions receives an input event containing relevant metadata and populated fields from the Amazon Bedrock agents API operation or function parameters. With a passion for softwaredevelopment, he guides energy customers through AWS service adoption.
Softwaredevelopers and engineers, for instance, use several AI-powered tools to code more quickly, increasing productivity and reducing costs as AI takes over menial tasks. Pate’s team uses IBM watsonx to fill out metadata and tags for thousands of content pages that need to be migrated. It went viral nearly immediately.
Repository Information**: Not shown in the provided excerpt, but likely contains metadata about the repository. Malav Shastri is a SoftwareDevelopment Engineer at AWS, where he works on the Amazon SageMaker JumpStart and Amazon Bedrock teams.
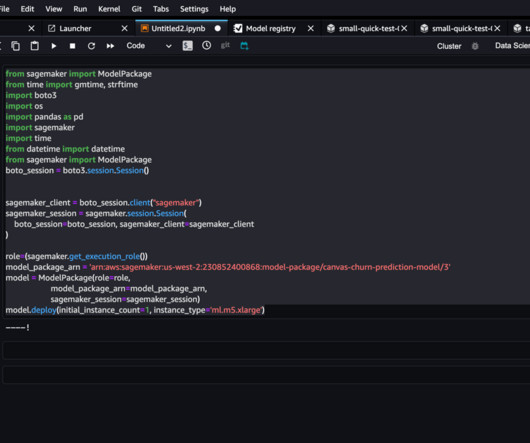
Now with the integration with the model registry, you can store all model artifacts, including metadata and performance metrics baselines, to a central repository and plug them into your existing model deployment CI/CD processes. Huayuan(Alice) Wu is a SoftwareDevelopment Engineer at Amazon SageMaker.
By using accelerated data processing, autonomous vehicle softwaredevelopers ensure they can reach a high-performance standard to avoid traffic accidents, lower transportation costs and improve mobility for users. However, the value of this imagery can be limited if it lacks specific location metadata.
A document is a collection of information that consists of a title, the content (or the body), metadata (data about the document), and access control list (ACL) information to make sure answers are provided from documents that the user has access to. Amazon Q supports the crawling and indexing of these custom objects and custom metadata.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content