This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.
The solution proposed in this post relies on LLMs context learning capabilities and promptengineering. When using the FAISS adapter, translation units are stored into a local FAISS index along with the metadata. The request is sent to the prompt generator.
Artifacts: Track intermediate outputs, memory states, and prompt templates to aid debugging. Prompt Management Promptengineering plays an important role in forming agent behavior. Key features include: Versioning: Track iterations of prompts for performance comparison.
But the drawback for this is its reliance on the skill and expertise of the user in promptengineering. On the other hand, a Node is a snippet or “chunk” from a Document, enriched with metadata and relationships to other nodes, ensuring a robust foundation for precise data retrieval later on.
makes it easy for RAG developers to track evaluation metrics and metadata, enabling them to analyze and compare different system configurations. Further, LangChain offers features for promptengineering, like templates and example selectors. Overview of the categories of building blocks provided by LangChain. ragas== 0.2.8
Promptengineering best practices for Meta Llama 3 The following are best practices for promptengineering for Meta Llama 3: Base model usage – Base models offer the following: Prompt-less flexibility – Base models in Meta Llama 3 excel in continuing sequences and handling zero-shot or few-shot tasks without requiring specific prompt formats.
Introduction to Large Language Models Difficulty Level: Beginner This course covers large language models (LLMs), their use cases, and how to enhance their performance with prompt tuning. Students will learn to write precise prompts, edit system messages, and incorporate prompt-response history to create AI assistant and chatbot behavior.
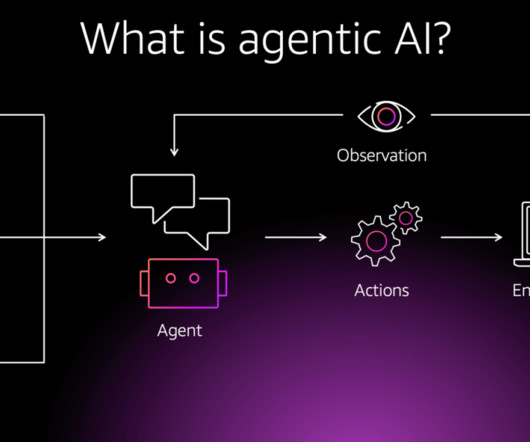
The following illustration describes the components of an agentic AI system: Overview of CrewAI CrewAI is an enterprise suite that includes a Python-based open source framework. Amazon Bedrock manages promptengineering, memory, monitoring, encryption, user permissions, and API invocation.
Traditional security methods, such as model training and promptengineering, have shown limited effectiveness, underscoring the urgent need for robust defenses. A custom Python interpreter enforces these fine-grained security policies, monitoring data provenance and ensuring compliance through explicit control-flow constraints.
By documenting the specific model versions, fine-tuning parameters, and promptengineering techniques employed, teams can better understand the factors contributing to their AI systems performance. This record-keeping allows developers and researchers to maintain consistency, reproduce results, and iterate on their work effectively.
Try metadata filtering in your OpenSearch index. Try using query rewriting to get the right metadata filtering. The retriever isn’t at fault, the problem is with FM generation (evaluated by a human or LLM): Try promptengineering to mitigate hallucinations. If none of the above help: Consider training a custom embedding.
offers a Prompt Lab, where users can interact with different prompts using promptengineering on generative AI models for both zero-shot prompting and few-shot prompting. These Slate models are fine-tuned via Jupyter notebooks and APIs. To bridge the tuning gap, watsonx.ai
This post walks through examples of building information extraction use cases by combining LLMs with promptengineering and frameworks such as LangChain. PromptengineeringPromptengineering enables you to instruct LLMs to generate suggestions, explanations, or completions of text in an interactive way.
Operational efficiency Uses promptengineering, reducing the need for extensive fine-tuning when new categories are introduced. Prerequisites This post is intended for developers with a basic understanding of LLM and promptengineering. A prompt is natural language text describing the task that an AI should perform.
The workflow for NLQ consists of the following steps: A Lambda function writes schema JSON and table metadata CSV to an S3 bucket. The wrapper function reads the table metadata from the S3 bucket. The wrapper function creates a dynamic prompt template and gets relevant tables using Amazon Bedrock and LangChain.
Additionally, VitechIQ includes metadata from the vector database (for example, document URLs) in the model’s output, providing users with source attribution and enhancing trust in the generated answers. PromptengineeringPromptengineering is crucial for the knowledge retrieval system. langsmith==0.0.43
Prompting Rather than inputs and outputs, LLMs are controlled via prompts – contextual instructions that frame a task. Promptengineering is crucial to steering LLMs effectively. Hybrid retrieval combines dense embeddings and sparse keyword metadata for improved recall.
This use case highlights how large language models (LLMs) are able to become a translator between human languages (English, Spanish, Arabic, and more) and machine interpretable languages (Python, Java, Scala, SQL, and so on) along with sophisticated internal reasoning.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., The platform also offers features for hyperparameter optimization, automating model training workflows, model management, promptengineering, and no-code ML app development.
Tools can take a variety of forms, such as API calls, Python functions, or webhook-based plugins. Often, these LLMs require some metadata about available tools (descriptions, yaml, or JSON schema for their input parameters) in order to output tool invocations. We use promptengineering only and Flan-UL2 model as-is without fine-tuning.
Refer to our GitHub repository for detailed Python notebooks and a step-by-step walkthrough. For example, we can follow promptengineering best practices to fine-tune an LLM to format dates into MM/DD/YYYY format, which may be compatible with a database DATE column.
You can change the response for the models in the following way: ==baseline You can reverse a list in Python using the built-in `reverse()` method or slicing. You can reverse a list in Python using the built-in reverse() method or slicing. You can use the reverse method to reverse a list in Python. Here's how you can do it [.]
As promptengineering is fundamentally different from training machine learning models, Comet has released a new SDK tailored for this use case comet-llm. In this article you will learn how to log the YOLOPandas prompts with comet-llm, keep track of the number of tokens used in USD($), and log your metadata.
You can customize the model using promptengineering, Retrieval Augmented Generation (RAG), or fine-tuning. You can create workflows with SageMaker Pipelines that enable you to prepare data, fine-tune models, and evaluate model performance with simple Python code for each step.
In this article, we will delve deeper into these issues, exploring the advanced techniques of promptengineering with Langchain, offering clear explanations, practical examples, and step-by-step instructions on how to implement them. Prompts play a crucial role in steering the behavior of a model.
Be sure to check out his talk, “ Prompt Optimization with GPT-4 and Langchain ,” there! The difference between the average person using AI and a PromptEngineer is testing. Most people run a prompt 2–3 times and find something that works well enough.
You’ll also be introduced to promptengineering, a crucial skill for optimizing AI interactions. You’ll explore data ingestion from multiple sources, preprocessing unstructured data into a normalized format that facilitates uniform chunking across various file types, and metadata extraction.
Comet’s LLMOps tool provides an intuitive and responsive view of our prompt history. Prompt Playground: With the LLMOps tool comes the new Prompt Playground, which allows PromptEngineers to iterate quickly with different Prompt Templates and understand the impact on different contexts.
LangChain is an open-source framework, available in Python and Javascript libraries, that enables users to build applications using LLMs. Think of LangChain as a toolbox for Python and Javascript that provides ready-to-use building blocks for working with language models. The rest are optional like prompt template, metadata, tags, etc.
In this experiment, I’ll use Comet LLM to record prompts, responses, and metadata for each memory type for performance optimization purposes. Make sure you’ve installed the necessary Python packages in requirements.txt and have your OpenAI API and Comet API keys ready. It seems to be a problem with the zipper.
Jupyter notebooks can differentiate between SQL and Python code using the %%sm_sql magic command, which must be placed at the top of any cell that contains SQL code. This command signals to JupyterLab that the following instructions are SQL commands rather than Python code.
You essentially divide things up into large tasks and chunks, but the software engineering that goes within that task is the thing that you’re generally gonna be updating and adding to over time as your machine learning grows within your company or you have new data sources, you want to create new models, right? To figure it out.
OneTwo is a Python library designed to simplify interactions with large (language and multimodal) foundation models, primarily aimed at researchers in prompting and prompting strategies. Define prompts as python functions with type hints and docstrings. Metadata, callbacks, and data format conversions.
This is where BeautifulSoup, a Python library, comes into play. Using the newspaper library, a Python package tailored for news extraction, performs a more refined retrieval. This method returns a list of separators appropriate for programming languages like Python, Java, C++, etc.
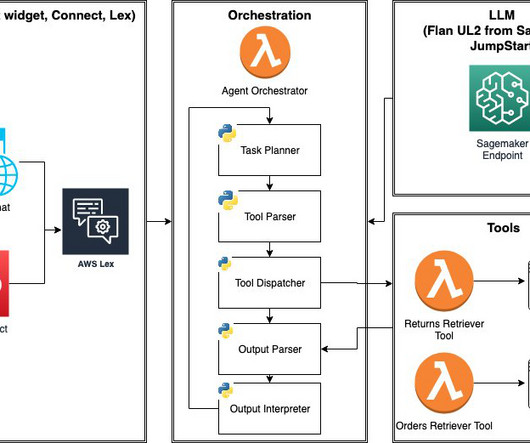
After the selection of the model(s), promptengineers are responsible for preparing the necessary input data and expected output for evaluation (e.g. input prompts comprising input data and query) and define metrics like similarity and toxicity. The following diagram illustrates this architecture. name: "llama2-7b-finetuned".
The enhanced metadata supports the matching categories to internal controls and other relevant policy and governance datasets. The platform incorporates the innovative Prompt Lab tool, specifically engineered to streamline promptengineering processes. Furthermore, watsonx.ai
By using a combination of transcript preprocessing, promptengineering, and structured LLM output, we enable the user experience shown in the following screenshot, which demonstrates the conversion of LLM-generated timestamp citations into clickable buttons (shown underlined in red) that navigate to the correct portion of the source video.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content