This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
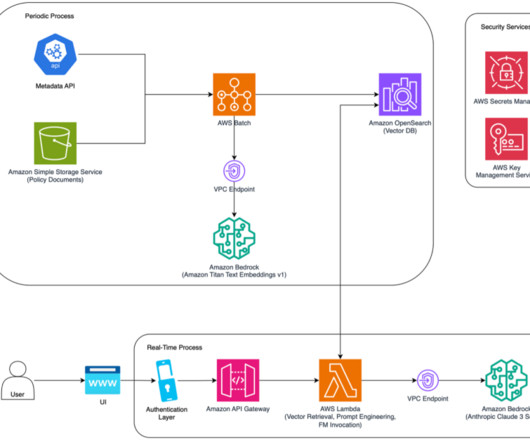
Efficient metadata storage with Amazon DynamoDB – To support quick and efficient data retrieval, document metadata is stored in Amazon DynamoDB. This extracted text is then available for further analysis and the creation of metadata, adding layout-based structure and meaning to the raw data.
Along with each document slice, we store the metadata associated with it using an internal Metadata API, which provides document characteristics like document type, jurisdiction, version number, and effective dates. This process has been implemented as a periodic job to keep the vector database updated with new documents.
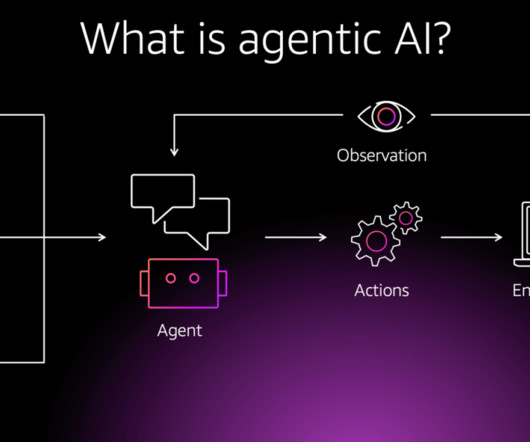
Consider a software development use case AI agents can generate, evaluate, and improve code, shifting softwareengineers focus from routine coding to more complex design challenges. Agentic systems, on the other hand, are designed to bridge this gap by combining the flexibility of context-aware systems with domain knowledge.
It also enables economies of scale with development velocity given that over 75 engineers at Octus already use AWS services for application development. Lambda functions process the event payload containing document location, perform format validation, and prepare content for extraction.
You can use metadata filtering to narrow down search results by specifying inclusion and exclusion criteria. Enterprise Solutions Architect at AWS, experienced in SoftwareEngineering, Enterprise Architecture, and AI/ML. However, in many situations, you might need to retrieve documents with specific attributes or content.
Posted by Yang Li, Research Scientist, and Gang Li, SoftwareEngineer, Google Research The computational understanding of user interfaces (UI) is a key step towards achieving intelligent UI behaviors. This metadata has given previous models advantages over their vision-only counterparts. their types, text content and positions).
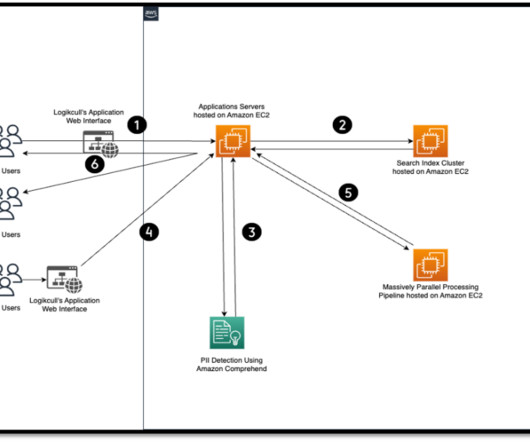
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption. Outside of work, he enjoys playing lawn tennis and reading books.
Overview of RAG RAG solutions are inspired by representation learning and semantic search ideas that have been gradually adopted in ranking problems (for example, recommendation and search) and naturallanguageprocessing (NLP) tasks since 2010. The search precision can also be improved with metadata filtering.
The emergence of generative AI agents in recent years has contributed to the transformation of the AI landscape, driven by advances in large language models (LLMs) and naturallanguageprocessing (NLP).
Here are some features which we will cover: AWS CloudFormation support Private network policies for Amazon OpenSearch Serverless Multiple S3 buckets as data sources Service Quotas support Hybrid search, metadata filters, custom prompts for the RetreiveAndGenerate API, and maximum number of retrievals. Nitin Eusebius is a Sr.
For example, if your team works on recommender systems or naturallanguageprocessing applications, you may want an MLOps tool that has built-in algorithms or templates for these use cases. Flexibility, speed, and accessibility : can you customize the metadata structure? Is it fast and reliable enough for your workflow?
Retailers can deliver more frictionless experiences on the go with naturallanguageprocessing (NLP), real-time recommendation systems, and fraud detection. In our example, we use the Bidirectional Encoder Representations from Transformers (BERT) model, commonly used for naturallanguageprocessing.
PyTorch is a machine learning (ML) framework based on the Torch library, used for applications such as computer vision and naturallanguageprocessing. Each model deployed with Triton requires a configuration file ( config.pbtxt ) that specifies model metadata, such as input and output tensors, model name, and platform.
To make that possible, your data scientists would need to store enough details about the environment the model was created in and the related metadata so that the model could be recreated with the same or similar outcomes. Version control for code is common in software development, and the problem is mostly solved.
Text to SQL: Using naturallanguage to enhance query authoring SQL is a complex language that requires an understanding of databases, tables, syntaxes, and metadata. Varun Shah is a SoftwareEngineer working on Amazon SageMaker Studio at Amazon Web Services. You can find Pranav on LinkedIn.
PyTorch is a machine learning (ML) framework that is widely used by AWS customers for a variety of applications, such as computer vision, naturallanguageprocessing, content creation, and more. Lai Wei is a Senior SoftwareEngineer at Amazon Web Services. With the recent PyTorch 2.0
Each response includes the annotator’s input and metadata such as acceptance time, submission time, and worker ID. This means that all annotations for a given data object are collected in one place, allowing you to process or analyze them later according to your specific requirements, without needing a post-annotation Lambda function.
Common patterns for filtering data include: Filtering on metadata such as the document name or URL. join(full_text) Deduplication After the preprocessing step, it is important to process the data further to remove duplicates (deduplication) and filter out low-quality content. Vinayak Arannil is a Sr. David Ping is a Sr.
Amazon DynamoDB : Used for storing metadata and other necessary information for quick retrieval during search operations. By using naturallanguageprocessing (NLP) and machine learning algorithms, Amazon Kendra can interpret the nuances of a query, ensuring that the retrieved documents and data align closely with the user’s actual intent.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








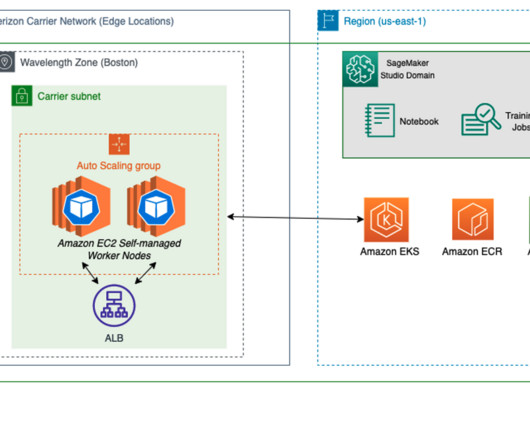



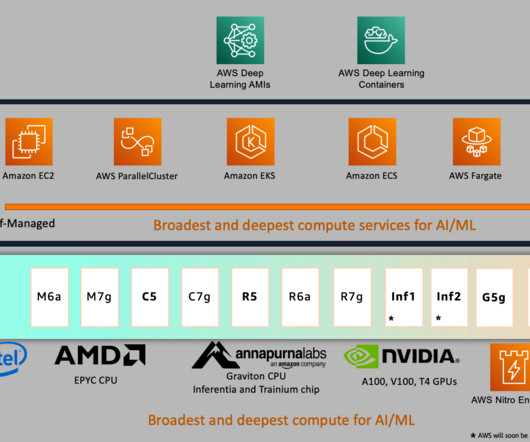









Let's personalize your content