This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
On complementary side wrt to the softwarearchitect side; to enable faster deployment of LLMs researchers have proposed serverless inference systems. In serverless architectures, LLMs are hosted on shared GPU clusters and allocated dynamically based on demand. This transfers orders of magnitude less data than snapshots.
So, when the softwarearchitect designed an AI inference platform to serve predictions for Oracle Cloud Infrastructure’s (OCI) Vision AI service, he picked NVIDIA Triton Inference Server. An avid cyclist, Thomas Park knows the value of having lots of gears to maintain a smooth, fast ride.
The following are some of the experiments that were conducted by the team, along with the challenges identified and lessons learned: Pre-training – Q4 understood the complexity and challenges that come with pre-training an LLM using its own dataset. In addition to the effort involved, it would be cost prohibitive.
Data Wrangling with Python Sheamus McGovern | CEO at ODSC | SoftwareArchitect, Data Engineer, and AI Expert Data wrangling is the cornerstone of any data-driven project, and Python stands as one of the most powerful tools in this domain. This session gave attendees a hands-on experience to master the essential techniques.
Troubleshooting Search and Retrieval with LLMs Xander Song | Machine Learning Engineer and Developer Advocate | Arize AI Some of the major challenges in deploying LLM applications are the accuracy of results and hallucinations. Finally, you’ll explore how to handle missing values and training and validating your models using PySpark.
Maciej Mensfeld is a principal product architect at Mend, focusing on data acquisition, aggregation, and AI/LLM security research. As a SoftwareArchitect, Security Researcher, and conference speaker, he teaches Ruby, Rails, and Kafka. In his spare time Gili enjoys family time and Calisthenics.
The tools provide the agent with access to data and functionality beyond what is available in the underlying LLM. This allows the agent to go beyond the knowledge contained in the LLM and incorporate up-to-date information or perform domain-specific operations.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



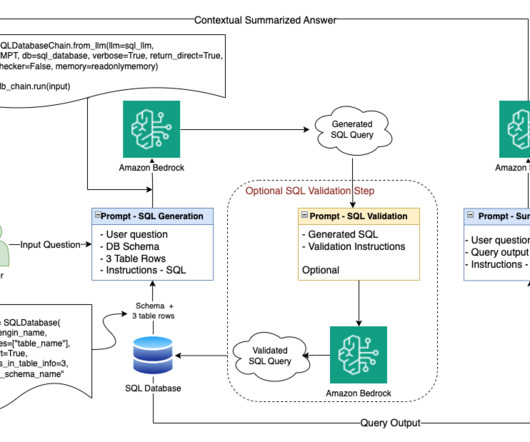



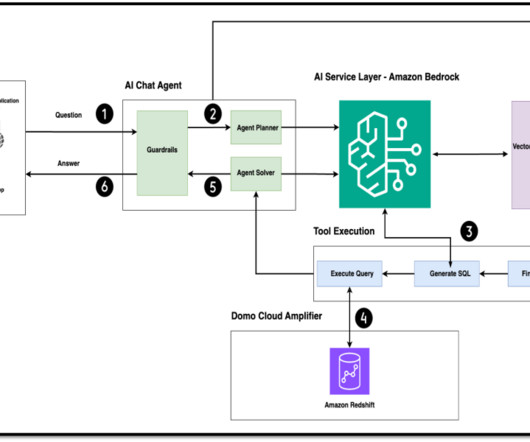






Let's personalize your content