This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Foundations of PromptEngineering Offered by AWS, this course delves into crafting effective prompts for AI agents, ensuring optimal performance and accuracy. LLM Agents Learning Platform A unique course focusing on leveraging large language models (LLMs) to create advanced AI agents for diverse applications.
It teaches the LLM to recognise the kinds of things that Wolfram|Alpha might know – our knowledge engine,” McLoone explains. As the LLM revolution started, we started doing a bunch of analysis on what they were really capable of,” explains McLoone. But the LLM is not just about chat,” says McLoone.
Indeed, as Anthropic promptengineer Alex Albert pointed out, during the testing phase of Claude 3 Opus, the most potent LLM (large language model) variant, the model exhibited signs of awareness that it was being evaluated. Explore other upcoming enterprise technology events and webinars powered by TechForge here.
You can't talk about LLMs without talking about promptengineering – and at first glance, prompting may appear intuitive and straightforward, but well, it ain't. And if you can't make it, don't worry - register anyway to get the recording!
Misaligned LLMs can generate harmful, unhelpful, or downright nonsensical responsesposing risks to both users and organizations. This is where LLM alignment techniques come in. LLM alignment techniques come in three major varieties: Promptengineering that explicitly tells the model how to behave.
LLMs, like GPT-4 and Llama 3, have shown promise in handling such tasks due to their advanced language comprehension. Current LLM-based methods for anomaly detection include promptengineering, which uses LLMs in zero/few-shot setups, and fine-tuning, which adapts models to specific datasets.
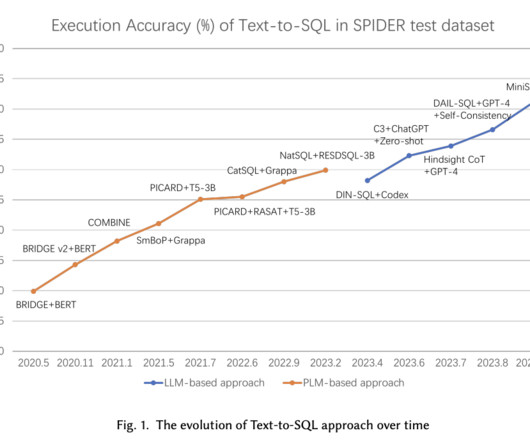
The proposed method in this paper leverages LLMs for Text-to-SQL tasks through two main strategies: promptengineering and fine-tuning. Promptengineering involves techniques such as Retrieval-Augmented Generation (RAG), few-shot learning, and reasoning, which require less data but may only sometimes yield optimal results.
Led by thought leaders like Sheamus McGovern, Founder of ODSC and Head of AI at Cortical Ventures, alongside Ali Hesham, a skilled Data Engineer from Ralabs, this bootcamp isnt just another courseits a launchpad for technical teams ready to take AI adoption seriously. Watch the full webinar of this topic on-demand here on Ai+ Training!
Foundation Models for TimesSeries Here, we explain how this model adapts the standard LLM architecture to time series, and one of the most important components, large time series data sets, and how they are assembled. Register by Friday for 30%off!
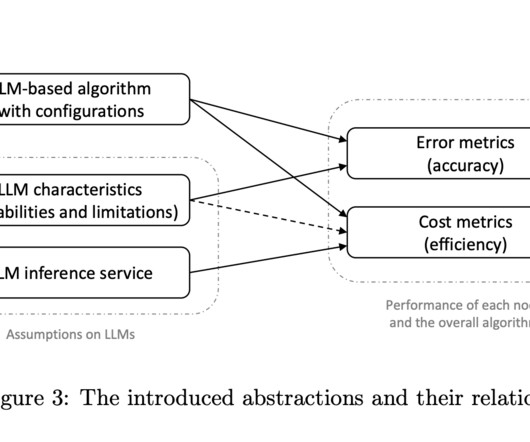
The primary issue addressed in the paper is the need for formal analysis and structured design principles for LLM-based algorithms. This approach is inefficient and lacks a theoretical foundation, making it difficult to optimize and accurately predict the performance of LLM-based algorithms.
” Generative AI patterns: “Supports promptengineering, retrieval augmented generation (RAG), fine-tuning, and pre-training, offering flexibility as business needs evolve.” Explore other upcoming enterprise technology events and webinars powered by TechForge here.
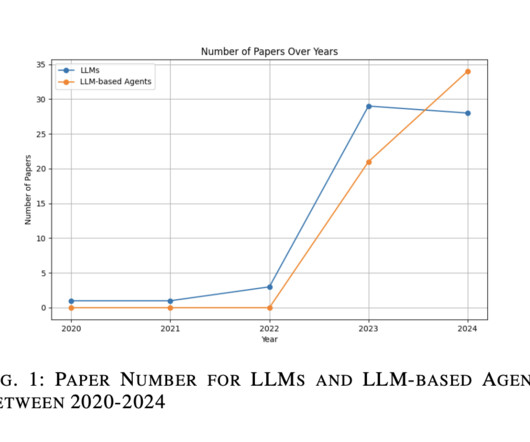
Despite this, LLMs’ use in requirement engineering has gradually increased, driven by advancements in contextual analysis and reasoning through promptengineering and Chain-of-Thought techniques. The field of LLM-based agents lacks standardized benchmarks, impeding effective performance evaluation.
Your Guide to Starting With RAG for LLM-Powered Applications In this post, we take a closer look at how RAG has emerged as the ideal starting point when it comes to designing enterprise LLM-powered applications. RAG vs Finetuning — Which Is the Best Tool to Boost Your LLM Application? Grab your tickets for 70% off by Friday!
Traditional test case generation approaches rely on rule-based systems or manual engineering of prompts for Large Language Models (LLMs). Most researchers use manual methods to optimize promptengineering for test case generation, which requires significant time investment.
The Best Lightweight LLMs of 2025: Efficiency Meets Performance Together in this blog, were going to explore what makes an LLM lightweight, the top models in 2025, and how to choose the right one for yourneeds. Register ASAP for 30%off!
Additionally, large language model (LLM)-based analysis is applied to derive further insights, such as video summaries and classifications. These analytics are implemented with either Amazon Comprehend , or separate promptengineering with FMs. Finally, the data is stored in a database for downstream applications to consume.
5 Must-Have Skills to Get Into PromptEngineering From having a profound understanding of AI models to creative problem-solving, here are 5 must-have skills for any aspiring promptengineer. The Implications of Scaling Airflow Wondering why you’re spending days just deploying code and ML models?
Researchers from the Department of Excellence in Robotics and AI at Scuola Superiore Sant’Anna and Mediavoice Srl analyzed how output length affects LLM inference time. They introduced a refined promptengineering strategy, Constrained-Chain-of-Thought (CCoT), which limits output length to improve accuracy and response time.
Is promptengineering alone sufficient to achieve the desired accuracy? Under what circumstances does training your own LLM lead to more stable outputs? Join us on July 11th at 2:00 PM ET for a live webinar where we'll showcase when to train and when to use an LLM out-of-the-box. SAVE YOUR SEAT
The following are some of the experiments that were conducted by the team, along with the challenges identified and lessons learned: Pre-training – Q4 understood the complexity and challenges that come with pre-training an LLM using its own dataset. The context is finally used to augment the input prompt for a summarization step.
This method utilizes capable LLMs, like the GPT family, to produce high-quality synthetic data. Recent research has highlighted LLMs’ ability to rephrase and boost synthetic data for effective SFT, suggesting continued growth in synthetic data use for improving LLM performance and alignment.
Current approaches to leveraging LLMs in VLN tasks include zero-shot methods, where LLMs are prompted with textual descriptions of the navigation environment, and fine-tuning methods, where LLMs are trained on instruction-trajectory pairs. If you like our work, you will love our newsletter.
Below are six ways discussed to prevent hallucinations in LLMs: Use High-Quality Data The use of high-quality data is one simple-to-do thing. The data that trains an LLM serves as its primary knowledge base, and any shortcomings in this dataset can directly lead to flawed outputs. If you like our work, you will love our newsletter.
has taken a significant leap in the field of PromptEngineering, recognizing its critical role in their operations. This level of detail is necessitated by the sheer volume of prompts they generate daily—billions—and the need to maximize the potential of expanding LLM context windows. Character.AI
This approach aims to balance latency and interpretability by combining a small classification model, specifically a small language model (SLM), with a downstream LLM module called a “constrained reasoner.” ” The SLM performs initial hallucination detection, while the LLM module explains the detected hallucinations.
This limits the accessibility of LLMs to smaller organizations, degrades the user experience in real-time applications, and risks misinformation or errors in critical domains like healthcare and finance. Addressing these obstacles is essential for broader adoption and trust in LLM-powered solutions.
Accelerating Decisions with Third-Party Data in Financial Services On-Demand Webinar Your ability to make confident decisions based on relevant factors relies on accurate data filled with context. In addition, we’ll discuss a variety of tools that form the modern LLM application development stack.
Datasets for Fine-Tuning Large Language Models, PromptEngineering Use Cases, and How to Ace the Data Science Interview 10 Datasets for Fine-Tuning Large Language Models In this blog post, we will explore ten valuable datasets that can assist you in fine-tuning or training your LLM. It’s entirely up to you!
However, a significant challenge persists in developing open-source code LLMs, as their performance consistently lags behind state-of-the-art models. This performance gap primarily stems from the proprietary training datasets used by leading LLM providers, who maintain strict control over these crucial resources.
Large language models (LLMs) have revolutionized the field of artificial intelligence, enabling the creation of language agents capable of autonomously solving complex tasks. The current approach involves manually decomposing tasks into LLM pipelines, with prompts and tools stacked together. Researchers from AIWaves Inc.
Adam Ross Nelson on Confident Data Science In this interview, we talk about what confident data science is, how data scientists can confidently and ethically use AI, and emerging fields like promptengineering. This webinar will equip you with the knowledge and strategies to make Generative AI a success within your organization.
Best Practices for PromptEngineering in Claude, Mistral, and Llama Every LLM is a bit different, so the best practices for each may differ from one another. Got an LLM That Needs Some Work? Here’s a guide on how to use three popular ones: Llama, Mistral AI, and Claude.
In this guest post, Vikram Chatterji, CEO and co-founder of Galileo, introduces us to their LLM Studio. You can learn more about Galileo LLM Studio through their webinar on Oct 4. With large language models (LLMs) increasing in size and popularity we, as a data science community, have seen new needs emerge.
For a demonstration on how you can use a RAG evaluation framework in Amazon Bedrock to compute RAG quality metrics, refer to New RAG evaluation and LLM-as-a-judge capabilities in Amazon Bedrock. For more information on application security, refer to Safeguard a generative AI travel agent with promptengineering and Amazon Bedrock Guardrails.
In contrast, the emerging technique focuses on optimizing input prompts for LLMs in a discrete natural language space. This shift raises a compelling question: Can a pretrained LLM function as a system parameterized by its natural language prompt, analogous to how neural networks are parameterized by numerical weights?
Instruction-tuned LLMs can handle various tasks using natural language instructions, but their performance is sensitive to how instructions are phrased. This issue is critical in healthcare, where clinicians, who may need to be more skilled, promptengineers, need reliable outputs. Check out the Paper.
Misaligned LLMs can generate harmful, unhelpful, or downright nonsensical responsesposing risks to both users and organizations. This is where LLM alignment techniques come in. LLM alignment techniques come in three major varieties: Promptengineering that explicitly tells the model how to behave.
The analysis also clarifies how LLM performance can be optimized through promptengineering. The team has also studied how the model’s dependence on these two processes can change depending on the task configuration, including the problem’s difficulty and the quantity of in-context instances.
The Rise of Deepfakes and Automated PromptEngineering: Navigating the Future of AI In this podcast recap with Dr. Julie Wall of the University of West London, we discuss two big topics in generative AI: deepfakes and automated promptedengineering.
Our incredible lineup of speakers includes world-class experts in AI engineering, AI for robotics, LLMs, machine learning, and much more. LLM Distillation — Build Enterprise-Grade Applications Like Apple In this article we will talk through the steps required to distill a large, state of the art model to a smaller sibling model.
But theres a catch: LLMs, particularly the largest and most advanced ones, are resource-intensive. Enter LLM distillation, a powerful technique that helps enterprises balance performance, cost efficiency, and task-specific optimization. By distilling large frontier LLMs like Llama 3.1 What is LLM distillation?
But theres a catch: LLMs, particularly the largest and most advanced ones, are resource-intensive. Enter LLM distillation, a powerful technique that helps enterprises balance performance, cost efficiency, and task-specific optimization. By distilling large frontier LLMs like Llama 3.1 What is LLM distillation?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















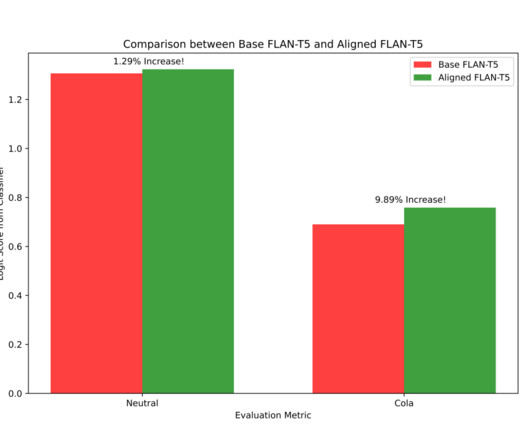


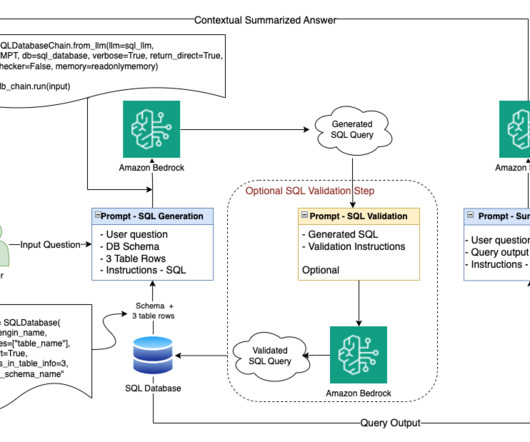




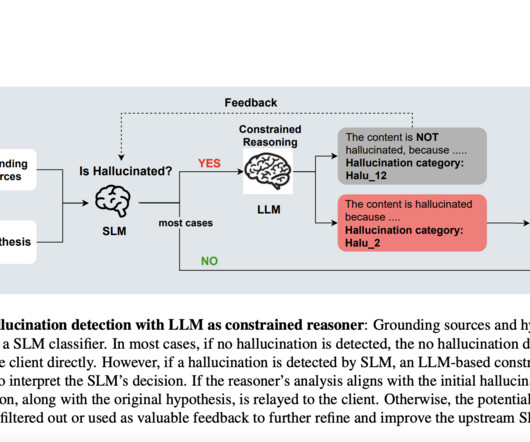




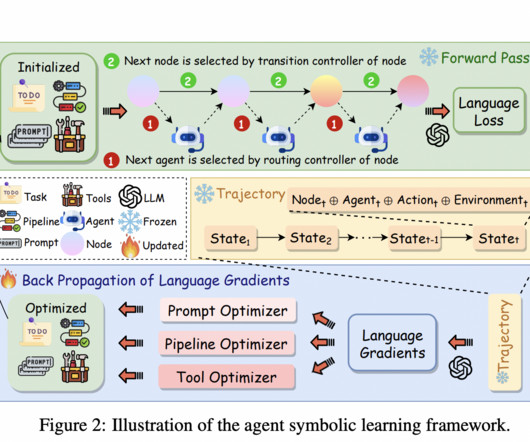
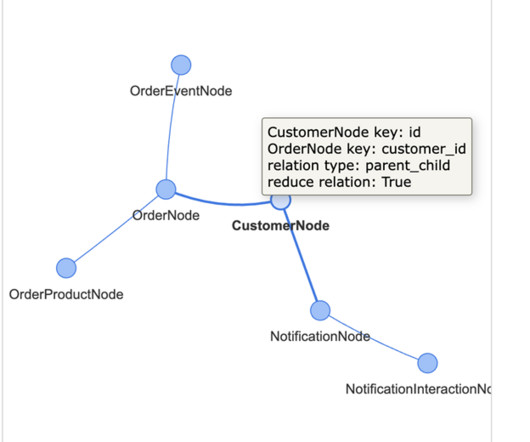

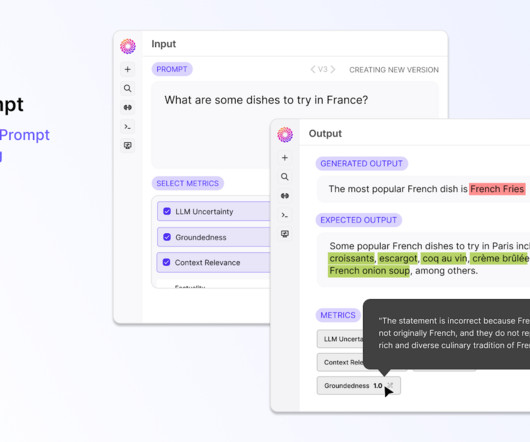


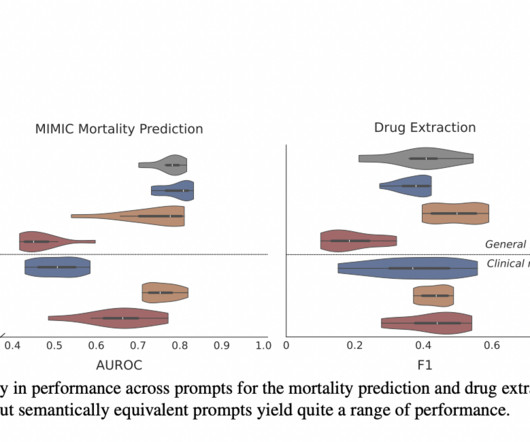












Let's personalize your content