This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In many generative AI applications, a large language model (LLM) like Amazon Nova is used to respond to a user query based on the models own knowledge or context that it is provided. Instead of relying on promptengineering, tool choice forces the model to adhere to the settings in place.
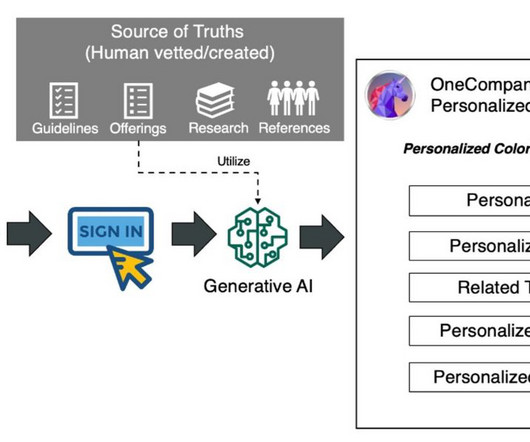
The Truth Is Out There So, how to reduce hallucinations in LLMs? What are the techniques for minimizing LLM hallucinations? Design systems that support accurate LLM performance – use grounding to anchor outputs of a language model to a trusted source. Here are a few approaches.
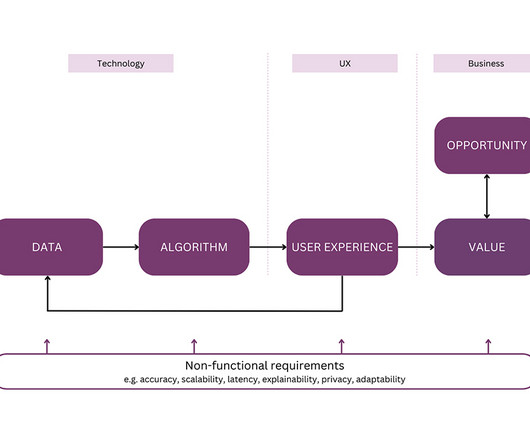
It aims to bring together the perspectives of product managers, UXdesigners, data scientists, engineers, and other team members. For example, if you are working on a virtual assistant, your UXdesigners will have to understand promptengineering to create a natural user flow.
We employ task decomposition, using domain / task adopted LLMs for content personalization (UXdesigner/personalizer), image generation (artist), and building (builder/front end developer) for the final delivery of HTML, CSS, and JavaScript files. The first part moves to the frontend developer LLM.
The article is written for product managers, UXdesigners and those data scientists and engineers who are at the beginning of their Text2SQL journey. For any reasonable business database, including the full information in the prompt will be extremely inefficient and most probably impossible due to prompt length limitations.
Not only are large language models (LLMs) capable of answering a users question based on the transcript of the file, they are also capable of identifying the timestamp (or timestamps) of the transcript during which the answer was discussed. The file is sent to Amazon Transcribe and the resulting transcript is stored in Amazon S3.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











Let's personalize your content