This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A neuralnetwork (NN) is a machine learning algorithm that imitates the human brain's structure and operational capabilities to recognize patterns from training data. Despite being a powerful AI tool, neuralnetworks have certain limitations, such as: They require a substantial amount of labeled training data.
The ecosystem has rapidly evolved to support everything from large language models (LLMs) to neuralnetworks, making it easier than ever for developers to integrate AI capabilities into their applications. is its intuitive approach to neuralnetwork training and implementation. environments. TensorFlow.js
Two notable research papers contribute to this development: “Bayesian vs. PAC-Bayesian Deep NeuralNetwork Ensembles” by University of Copenhagen researchers and “Deep Bayesian Active Learning for Preference Modeling in Large Language Models” by University of Oxford researchers.
This issue is resource-heavy but quite fun, with real-world AI concepts, tutorials, and some LLM essentials. We are diving into Mechanistic interpretability, an emerging area of research in AI focused on understanding the inner workings of neuralnetworks. Jjj8405 is seeking an NLP/LLM expert to join the team for a project.
This issue is resource-heavy but quite fun, with real-world AI concepts, tutorials, and some LLM essentials. We are diving into Mechanistic interpretability, an emerging area of research in AI focused on understanding the inner workings of neuralnetworks. Jjj8405 is seeking an NLP/LLM expert to join the team for a project.
This issue is resource-heavy but quite fun, with real-world AI concepts, tutorials, and some LLM essentials. We are diving into Mechanistic interpretability, an emerging area of research in AI focused on understanding the inner workings of neuralnetworks. Jjj8405 is seeking an NLP/LLM expert to join the team for a project.
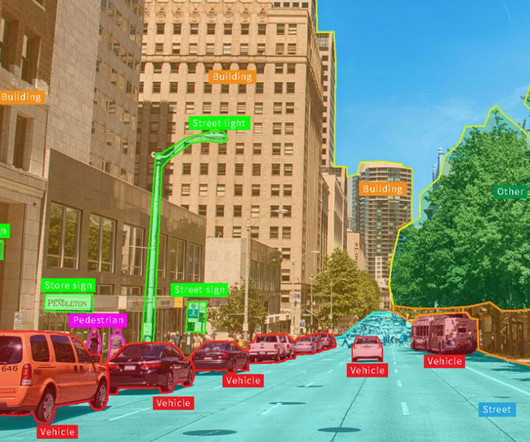
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent data extraction. Named Entity Recognition ( NER) Named entity recognition (NER), an NLP technique, identifies and categorizes key information in text.
These architectures are based on artificial neuralnetworks , which are computational models loosely inspired by the structure and functioning of biological neuralnetworks, such as those in the human brain. A simple artificial neuralnetwork consisting of three layers.
link] The paper investigates LLM robustness to prompt perturbations, measuring how much task performance drops for different models with different attacks. link] The paper proposes query rewriting as the solution to the problem of LLMs being overly affected by irrelevant information in the prompts. ArXiv 2023. Oliveira, Lei Li.
But more than MLOps is needed for a new type of ML model called Large Language Models (LLMs). LLMs are deep neuralnetworks that can generate natural language texts for various purposes, such as answering questions, summarizing documents, or writing code.
If you havent already checked it out, weve also launched an extremely in-depth course to help you land a 6-figure job as an LLM developer. But, all the rules of learning that apply to AI, machine learning, and NLP dont always apply to LLMs, especially if you are building something or looking for a high-paying job.
DeepSeek AI is an advanced AI genomics platform that allows experts to solve complex problems using cutting-edge deep learning, neuralnetworks, and natural language processing (NLP). What is DeepSeek AI? DeepSeek AI, on the other hand, isnt just another fancy AI gadget, its a revolutionary breakthrough.
Prompt 1 : “Tell me about Convolutional NeuralNetworks.” ” Response 1 : “Convolutional NeuralNetworks (CNNs) are multi-layer perceptron networks that consist of fully connected layers and pooling layers. They are commonly used in image recognition tasks. .”
In the meanwhile, an LLM training paradigm known as instruction tuning—in which data is arranged as pairs of user instruction and reference response—has evolved that enables LLMs to comply with unrestricted user commands. These tasks need multilingual and high-quality alignments between voice and text tokens.
Transformers have transformed the field of NLP over the last few years, with LLMs like OpenAI’s GPT series, BERT, and Claude Series, etc. Let’s delve into the role of transformers in NLP and elucidate the process of training LLMs using this innovative architecture. appeared first on MarkTechPost.
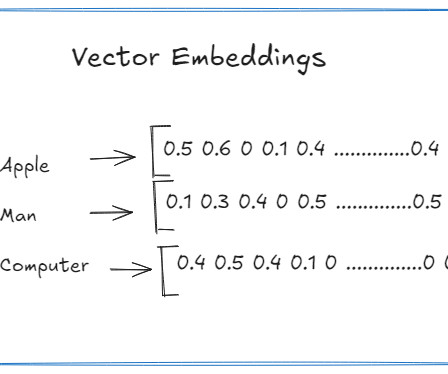
Many neuralnetwork approaches have been developed to convert the data into numerical representation. The main theme is that it can contain semantic and meaningful contextual information about the objects so that ML algorithms can efficiently analyze and understand the data. Different data types are embedded in different ways.
The Scale and Complexity of LLMs The scale of these models adds to their complexity. Each parameter interacts in intricate ways within the neuralnetwork, contributing to emergent capabilities that aren’t predictable by examining individual components alone. Impact of the LLM Black Box Problem 1.
Transformers have taken over from recurrent neuralnetworks (RNNs) as the preferred architecture for natural language processing (NLP). The study also reports a significant reduction in LLM cache size, up to 88%, leading to reduced memory consumption during inference. Check out the Paper.
Also, in place of expensive retraining or fine-tuning for an LLM, this approach allows for quick data updates at low cost. at Google, and “ Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks ” by Patrick Lewis, et al., Convert an incoming prompt to a graph query, then use the result set to select chunks for the LLM.
Large Language Models (LLMs) have revolutionized the field of natural language processing (NLP) by demonstrating remarkable capabilities in generating human-like text, answering questions, and assisting with a wide range of language-related tasks. While effective in various NLP tasks, few LLMs, such as Flan-T5, adopt this architecture.
Setting the Stage: Why Augmentation Matters Imagine youre chatting with an LLM about complex topics like medical research or historical events. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Despite its vast training, it occasionally hallucinates producing incorrect or fabricated information. Citations: Lewis, P.,
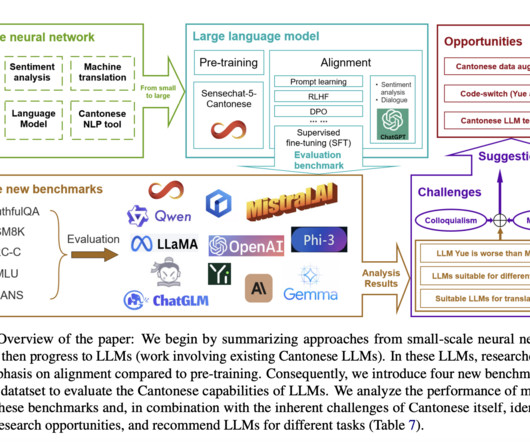
Large language models (LLMs) have revolutionized natural language processing (NLP), particularly for English and other data-rich languages. The development of Cantonese-specific LLMs faces significant challenges due to limited research and resources.
A 2-for-1 ODSC East Black Friday Deal, Multi-Agent Systems, Financial Data Engineering, and LLM Evaluation ODSC East 2025 Black Friday Deal Take advantage of our 2-for-1 Black Friday sale and join the leading conference for data scientists and AI builders. Learn, innovate, and connect as we shape the future of AI — together!
As the demand for large language models (LLMs) continues to rise, ensuring fast, efficient, and scalable inference has become more crucial than ever. NVIDIA's TensorRT-LLM steps in to address this challenge by providing a set of powerful tools and optimizations specifically designed for LLM inference.
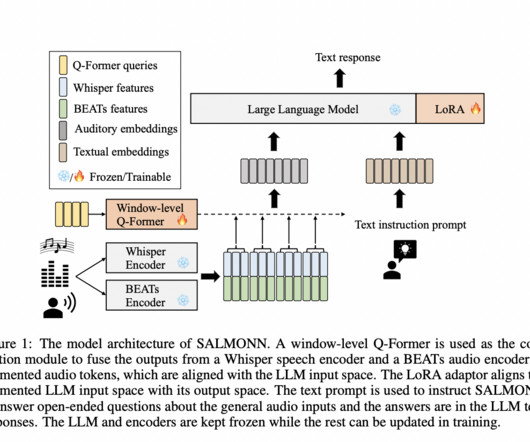
Recently, text-based Large Language Model (LLM) frameworks have shown remarkable abilities, achieving human-level performance in a wide range of Natural Language Processing (NLP) tasks. We will be taking a deeper dive into the SALMONN framework, and explore its working, architecture, and results across a wide array of NLP tasks.
With advancements in deep learning, natural language processing (NLP), and AI, we are in a time period where AI agents could form a significant portion of the global workforce. NeuralNetworks & Deep Learning : Neuralnetworks marked a turning point, mimicking human brain functions and evolving through experience.
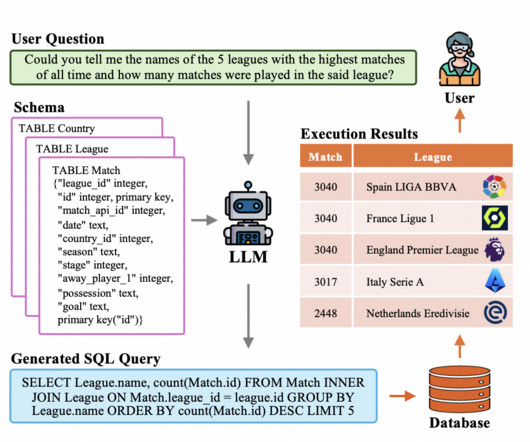
Traditional text-to-SQL systems using deep neuralnetworks and human engineering have succeeded. The LLMs have demonstrated the ability to execute a solid vanilla implementation thanks to the improved semantic parsing capabilities made possible by the larger training corpus. Join our Telegram Channel and LinkedIn Gr oup.
Generative AI for coding is possible because of recent breakthroughs in large language model (LLM) technologies and natural language processing (NLP). It uses deep learning algorithms and large neuralnetworks trained on vast datasets of diverse existing source code. How does generative AI code generation work?
LLMs or Large Language Models have enjoyed tremendous success in the NLP industry, and they are now being explored for their applications in visual tasks. These approaches indicate that LLM frameworks might have some applications for visual tasks. Finally, the model feeds the embeddings and original image information to the LLM.
Furthermore, empirically enumerating all the possible designs for training LLMs over 100B parameters is computationally unaffordable which makes it even more critical to come up with a pre-training method for large scale LLM frameworks. With that being said, let’s have a look at GLM-130B’s architecture.
The announcement of Google Gemini, nestled closely after the debut of Bard, Duet AI, and the PaLM 2 LLM, marks a clear intention from Google to not only compete but lead in the AI revolution. Power of Multimodality: At its core, Gemini utilizes a transformer-based architecture, similar to those employed in successful NLP models like GPT-3.
The natural language processing (NLP) field has witnessed significant advancements with the emergence of Large Language Models (LLMs) like GPT and LLaMA. These models have become essential tools for various tasks, prompting a growing need for proprietary LLMs among individuals and organizations.
In this world of complex terminologies, someone who wants to explain Large Language Models (LLMs) to some non-tech guy is a difficult task. So that’s why I tried in this article to explain LLM in simple or to say general language. No training examples are needed in LLM Development but it’s needed in Traditional Development.
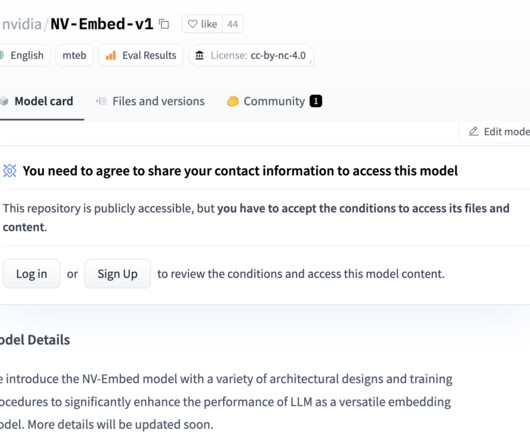
NVIDIA has recently introduced NV-Embed on Hugging Face , a revolutionary embedding model poised to redefine the landscape of NLP. and built on a large language model (LLM) architecture, NV-Embed showcases various architectural designs and training procedures that significantly enhance its performance as an embedding model.
When it comes to AI, there are a number of subfields, like Natural Language Processing (NLP). One of the models used for NLP is the Large Language Model (LLMs). As a result, LLMs have become a key tool for a wide range of NLP applications. ChatGPT , a chatbot developed by the OpenAI team, is an example of an LLM.
LLMs have become increasingly popular in the NLP (natural language processing) community in recent years. Scaling neuralnetwork-based machine learning models has led to recent advances, resulting in models that can generate natural language nearly indistinguishable from that produced by humans. Check out the Paper.
GPT 3 and similar Large Language Models (LLM) , such as BERT , famous for its bidirectional context understanding, T-5 with its text-to-text approach, and XLNet , which combines autoregressive and autoencoding models, have all played pivotal roles in transforming the Natural Language Processing (NLP) paradigm.
Many companies have experience with natural language processing (NLP) and low-level chatbots, but GenAI is accelerating how data can be integrated, interpreted, and converted into business outcomes. The Journey from NLP to Large Language Model (LLM) Technology has been trying to make sense of natural languages for decades now.
A foundation model is built on a neuralnetwork model architecture to process information much like the human brain does. A specific kind of foundation model known as a large language model (LLM) is trained on vast amounts of text data for NLP tasks. An open-source model, Google created BERT in 2018. All watsonx.ai
While these large language model (LLM) technologies might seem like it sometimes, it’s important to understand that they are not the thinking machines promised by science fiction. Achieving these feats is accomplished through a combination of sophisticated algorithms, natural language processing (NLP) and computer science principles.
Graphs are important in representing complex relationships in various domains like social networks, knowledge graphs, and molecular discovery. Foundation Models (FMs) have revolutionized NLP and vision domains in the broader AI spectrum. Alongside topological structure, nodes often possess textual features providing context.
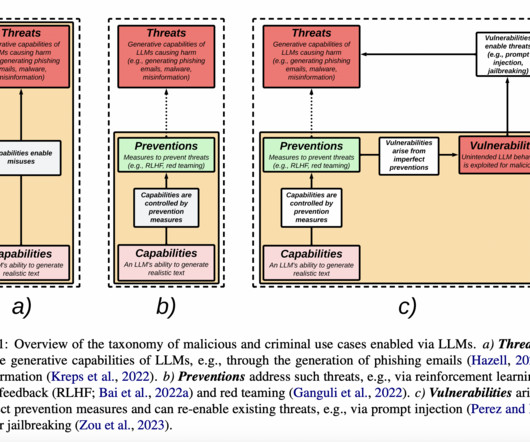
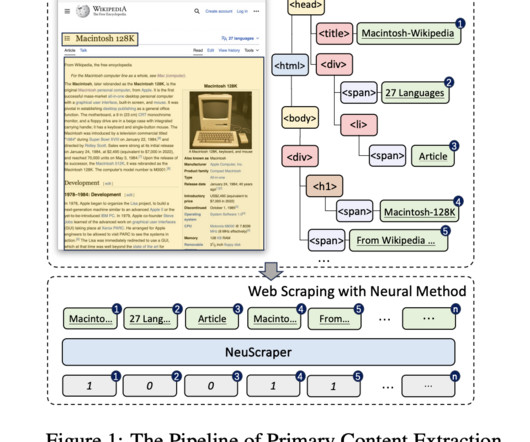
They need help to differentiate between the core content and the myriad of distractions like advertisements, pop-ups, and irrelevant hyperlinks, leading to the collection of noisy data that can dilute the quality of LLM training sets.
This article lists the top AI courses NVIDIA provides, offering comprehensive training on advanced topics like generative AI, graph neuralnetworks, and diffusion models, equipping learners with essential skills to excel in the field. It also covers how to set up deep learning workflows for various computer vision tasks.
What’s AI Weekly Keeping up with LLMs is getting tougher; there’s so much happening every week. I have compiled a guide to help you start and improve your LLM skills in 2024 without an advanced background in the field and stay up-to-date with the latest news and state-of-the-art techniques! Read the complete LLM guide here!
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content