This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A neuralnetwork (NN) is a machine learning algorithm that imitates the human brain's structure and operational capabilities to recognize patterns from training data. Despite being a powerful AI tool, neuralnetworks have certain limitations, such as: They require a substantial amount of labeled training data.
Now, new research from Anthropic is exposing at least some of the inner neuralnetwork "circuitry" that helps an LLM decide when to take a stab at a (perhaps hallucinated) response versus when to refuse an answer in the first place.
The ability to effectively represent and reason about these intricate relational structures is crucial for enabling advancements in fields like network science, cheminformatics, and recommender systems. Graph NeuralNetworks (GNNs) have emerged as a powerful deep learning framework for graph machine learning tasks.
Their outputs are formed from billions of mathematical signals bouncing through layers of neuralnetworks powered by computers of unprecedented power and speed, and most of that activity remains invisible or inscrutable to AI researchers. The truth is, we dont fully know. Large language models think in ways that dont look very human.
The ecosystem has rapidly evolved to support everything from large language models (LLMs) to neuralnetworks, making it easier than ever for developers to integrate AI capabilities into their applications. is its intuitive approach to neuralnetwork training and implementation. environments. TensorFlow.js
LSTM, the brainchild of Dr. Sepp Hochreiter and Juergen Schmidhuber, revolutionized neuralnetworks. But now, Hochreiter reveals a hidden successor to LSTM called “XLSTM,” aiming to take down […] The post The Challenger Aiming to Dethrone OpenAI’s LLM Supremacy: XLSTM appeared first on Analytics Vidhya.
MosaicML’s machine learning and neuralnetworks experts are at the forefront of AI research, striving to enhance model training efficiency. The post Databricks acquires LLM pioneer MosaicML for $1.3B Check out AI & Big Data Expo taking place in Amsterdam, California, and London. appeared first on AI News.
Departing from the strategies of most Language Models (LLMs), Mixtral 8x7B is a fascinating […] The post Discover the Groundbreaking LLM Development of Mixtral 8x7B appeared first on Analytics Vidhya.
“While a traditional Transformer functions as one large neuralnetwork, MoE models are divided into smaller ‘expert’ neuralnetworks,” explained Demis Hassabis, CEO of Google DeepMind. This specialisation massively enhances the model’s efficiency.” Developers interested in testing Gemini 1.5 Pro can sign up in AI Studio.
Two notable research papers contribute to this development: “Bayesian vs. PAC-Bayesian Deep NeuralNetwork Ensembles” by University of Copenhagen researchers and “Deep Bayesian Active Learning for Preference Modeling in Large Language Models” by University of Oxford researchers.
However, the unpredictable nature of real-world data, coupled with the sheer diversity of tasks, has led to a shift toward more flexible and robust frameworks, particularly reinforcement learning and neuralnetwork-based approaches. LLM-Based Reasoning (GPT-4 Chain-of-Thought) A recent development in AI reasoning leverages LLMs.
Technologies such as Recurrent NeuralNetworks (RNNs) and transformers introduced the ability to process sequences of data and paved the way for more adaptive AI. On the technical side, implementing persistent memory in LLMs often involves combining advanced storage solutions with efficient retrieval mechanisms.
Hey 👋, this weekly update contains the latest info on our new product features, tutorials, and our community LeMUR Cookbooks: Build Audio LLM Apps LeMUR is the easiest way to code applications that apply LLMs to speech.
A typical LLM using CoT prompting might solve it like this: Determine the regular price: 7 * $2 = $14. A human can infer such a rule immediately, but an LLM cannot as it simply follows a structured sequence of calculations. LLMs, however, lack a genuine symbolic reasoning mechanism. Compute the discount: 7 * $1 = $7.
This issue is resource-heavy but quite fun, with real-world AI concepts, tutorials, and some LLM essentials. We are diving into Mechanistic interpretability, an emerging area of research in AI focused on understanding the inner workings of neuralnetworks. Jjj8405 is seeking an NLP/LLM expert to join the team for a project.
This issue is resource-heavy but quite fun, with real-world AI concepts, tutorials, and some LLM essentials. We are diving into Mechanistic interpretability, an emerging area of research in AI focused on understanding the inner workings of neuralnetworks. Jjj8405 is seeking an NLP/LLM expert to join the team for a project.
This issue is resource-heavy but quite fun, with real-world AI concepts, tutorials, and some LLM essentials. We are diving into Mechanistic interpretability, an emerging area of research in AI focused on understanding the inner workings of neuralnetworks. Jjj8405 is seeking an NLP/LLM expert to join the team for a project.
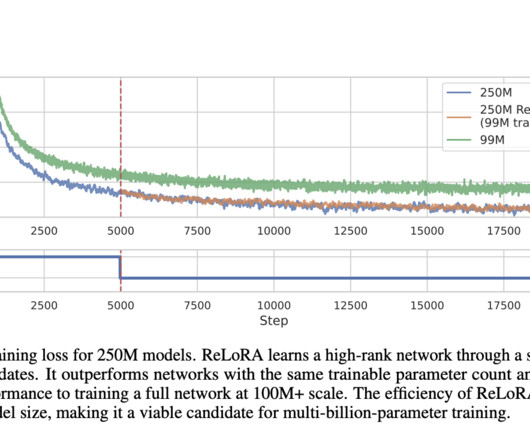
ReLoRA accomplishes a high-rank update, delivering a performance akin to conventional neuralnetwork training. link] Scaling laws have been identified, demonstrating a strong power-law dependence between network size and performance across different modalities, supporting overparameterization and resource-intensive neuralnetworks.
He outlined key attributes of neuralnetworks, embeddings, and transformers, focusing on large language models as a shared foundation. Neuralnetworks — described as probabilistic and adaptable — form the backbone of AI, mimicking human learning processes.
These architectures are based on artificial neuralnetworks , which are computational models loosely inspired by the structure and functioning of biological neuralnetworks, such as those in the human brain. A simple artificial neuralnetwork consisting of three layers. Et voilà !
This training data exposes the LLM to the intricate patterns and nuances of human language. At the heart of these LLMs lies a sophisticated neuralnetwork architecture called a transformer. This allows the LLM to understand each word's context and predict the most likely word to follow in the sequence.
During training, each row of data as it passes through the network–called a neuralnetwork–modifies the equations at each layer of the network so that the predicted output matches the actual output. As the data in a training set is processed, the neuralnetwork learns how to predict the outcome.
The ever-growing presence of artificial intelligence also made itself known in the computing world, by introducing an LLM-powered Internet search tool, finding ways around AIs voracious data appetite in scientific applications, and shifting from coding copilots to fully autonomous coderssomething thats still a work in progress. Perplexity.ai
This innovation enables the first formal model and verification of the new IEEE P3109 standard for small (<16 bit) binary floating-point formats, essential for neuralnetwork quantization and distillation. For industries reliant on neuralnetworks, ensuring robustness and safety is critical.
DeepL has recently launched its first in-house LLM. Our next-generation translation models are powered by proprietary LLM technology designed specifically for translation and editing, which sets it apart from other models on the market and sets a new industry standard for translation quality and performance.
🔎 Decoding LLM Pipeline Step 1: Input Processing & Tokenization 🔹 From Raw Text to Model-Ready Input In my previous post, I laid out the 8-step LLM pipeline, decoding how large language models (LLMs) process language behind the scenes. Tokens: Fundamental unit that neuralnetworks process.
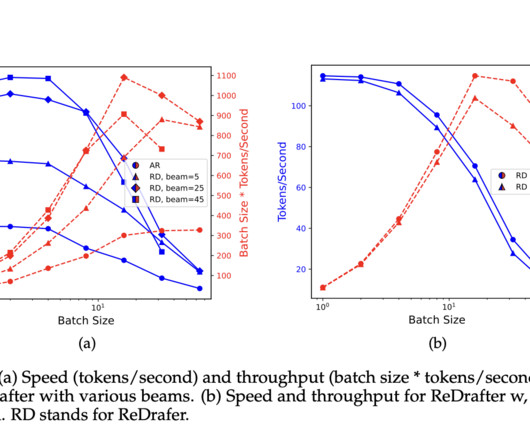
A team of researchers from Apple introduced ReDrafter , a method that ingeniously combines the strengths of speculative decoding with the adaptive capabilities of recurrent neuralnetworks (RNNs). In conclusion, the advent of ReDrafter by the Apple research team represents a paradigm shift in the pursuit of efficient LLM processing.
This is essentially a neuro-symbolic approach, where the neuralnetwork, Gemini, translates natural language instructions into the symbolic formal language Lean to prove or disprove the statement. The LLM in AlphaGeometry predicts new geometric constructs, while the symbolic AI applies formal logic to generate proofs.
This is your third AI book, the first two being: “Practical Deep Learning: A Python-Base Introduction,” and “Math for Deep Learning: What You Need to Know to Understand NeuralNetworks” What was your initial intention when you set out to write this book? AI as neuralnetworks is merely (!)
Unlike sequential models, LLMs optimize resource distribution, resulting in accelerated data extraction tasks. This architecture, leveraging neuralnetworks like RNNs and Transformers, finds applications in diverse domains, including machine translation, image generation, speech synthesis, and data entity extraction.
The neuralnetwork architecture of large language models makes them black boxes. They use a process called LLM alignment. Below, we will explain multiple facets of how alignment builds better large language model (LLM) experiences. Aligning an LLM works similarly. Lets dive in. Then, the employee adjusts.
LLM-as-Judge has emerged as a powerful tool for evaluating and validating the outputs of generative models. LLMs (and, therefore, LLM judges) inherit biases from their training data. In this article, well explore how enterprises can leverage LLM-as-Judge effectively , overcome its limitations, and implement best practices.
Unlike older AI systems that use just one AI model like the Transformer based LLM, CAS emphasizes integration of multiple tools. The goal is to merge the intuitive data processing abilities of neuralnetworks with the structured, logical reasoning of symbolic AI.
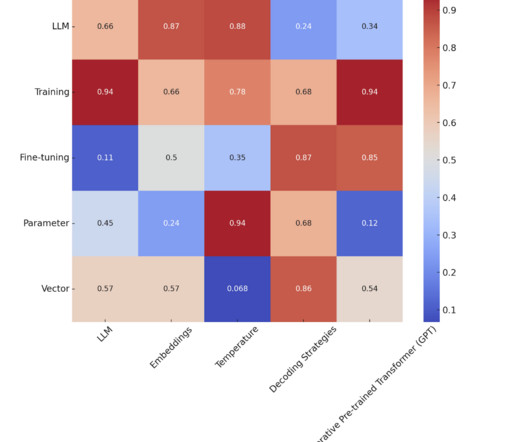
In this article, we delve into 25 essential terms to enhance your technical vocabulary and provide insights into the mechanisms that make LLMs so transformative. Heatmap representing the relative importance of terms in the context of LLMs Source: marktechpost.com 1.
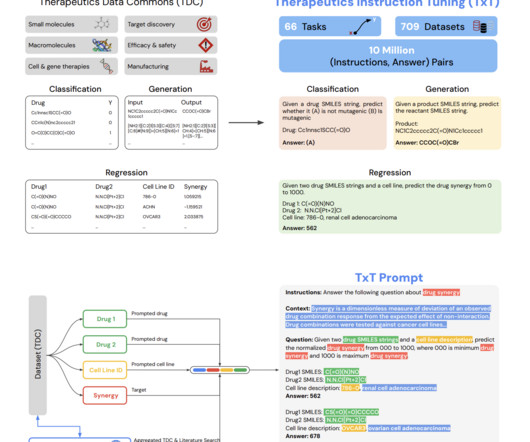
LLMs, particularly transformer-based models, have advanced natural language processing, excelling in tasks through self-supervised learning on large datasets. Recent studies show LLMs can handle diverse tasks, including regression, using textual representations of parameters. Tx-LLM was fine-tuned from PaLM-2 using this data.
The framework then trains the entire parameters of the LLM to pre-empower the Large Vision Language Model with a general multi-modal understanding capabilities. Finally, in the third stage, the framework replicates the FFN or Feed Forward Network as the initialization weights for the experts, and trains only the Mixture of Expert layers.
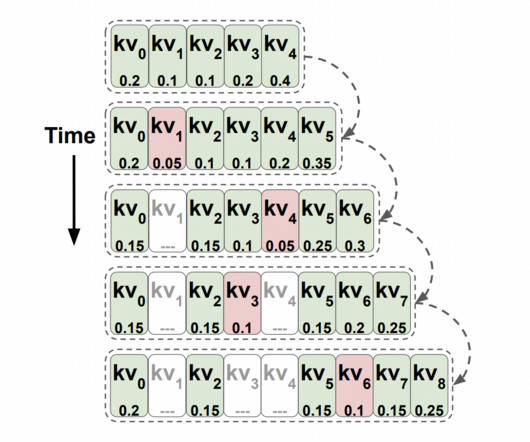
Transformers have taken over from recurrent neuralnetworks (RNNs) as the preferred architecture for natural language processing (NLP). The study also reports a significant reduction in LLM cache size, up to 88%, leading to reduced memory consumption during inference. Check out the Paper.
But more than MLOps is needed for a new type of ML model called Large Language Models (LLMs). LLMs are deep neuralnetworks that can generate natural language texts for various purposes, such as answering questions, summarizing documents, or writing code.
The traditional approach to the automation of radiology reporting is based on convolutional neuralnetworks (CNNs) or visual transformers to extract features from images. Such image-processing techniques often combine with transformers or recurrent neuralnetworks (RNNs) to generate textual outputs.
Image credits Cartoon Movement LLM pre-training and post-training The training of an LLM can be separated into a pre-training and post-training phase: Pre-training: Here the LLM is taught to predict the next word/token. But first, lets understand how these models employ Reinforcement Learning.
These include fourth-generation Tensor Cores, a new Transformer Engine for enhanced LLM acceleration, and NVLink technology that propels inter-GPU communication to unprecedented speeds of 900GB/sec. The newly introduced ND H100 v5 VMs hold immense potential for training and inferring increasingly intricate LLMs and computer vision models.
Fresh From Our Blog Extract phone call insights with LLMs in Python : Learn how to automatically extract insights from customer calls with Large Language Models (LLMs) and Python. Read more>> How to do Speech-To-Text with Go : Integrate speech recognition into your Go application in only a few lines of code.
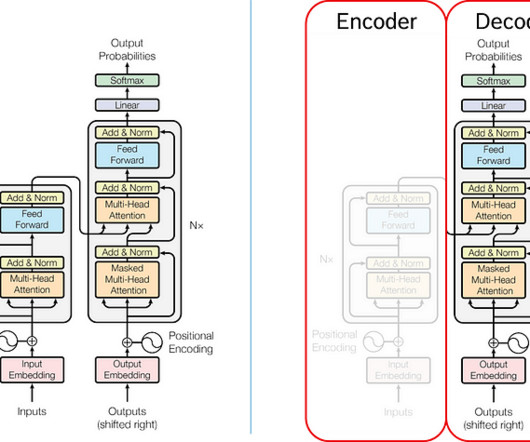
we see that the output of the attention block is normalized (Layer Norm), fed into a neuralnetwork (Feed forward), softmaxed, and finally runs through a multinomial distribution. These tokens are known to the LLM and will be represented by an internal number for further processing. On the right side of Fig.
In a world where AI seems to work like magic, Anthropic has made significant strides in deciphering the inner workings of Large Language Models (LLMs). By examining the ‘brain' of their LLM, Claude Sonnet, they are uncovering how these models think. How Anthropic Enhances Transparency of LLMs?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content