This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Evaluating large language models (LLMs) is crucial as LLM-based systems become increasingly powerful and relevant in our society. Rigorous testing allows us to understand an LLMs capabilities, limitations, and potential biases, and provide actionable feedback to identify and mitigate risk.
With access to a wide range of generative AI foundation models (FM) and the ability to build and train their own machine learning (ML) models in Amazon SageMaker , users want a seamless and secure way to experiment with and select the models that deliver the most value for their business.
Whether you're a seasoned MLengineer or a new LLM developer, these tools will help you get more productive and accelerate the development and deployment of your AI projects.
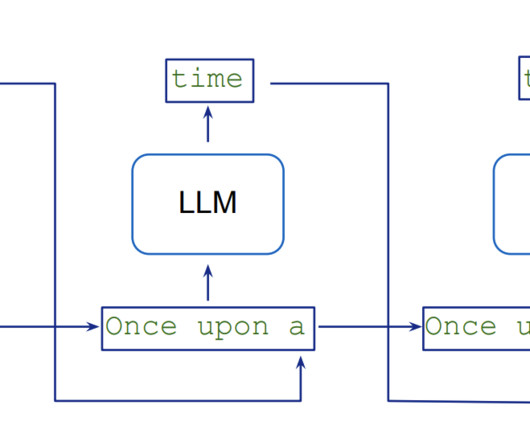
Researchers developed Medusa , a framework to speed up LLM inference by adding extra heads to predict multiple tokens simultaneously. This post demonstrates how to use Medusa-1, the first version of the framework, to speed up an LLM by fine-tuning it on Amazon SageMaker AI and confirms the speed up with deployment and a simple load test.
” Transforming AI Performance Across Industries Future AGI is already delivering impactful results across industries: A Series E sales-tech company used Future AGIs LLM Experimentation Hub to achieve 99% accuracy in its agentic pipeline, compressing weeks of work into just hours.
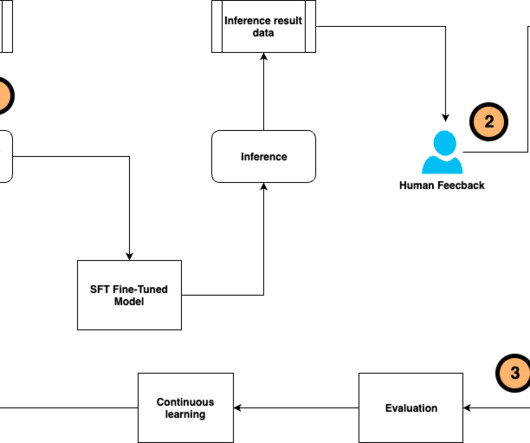
Fine-tuning a pre-trained large language model (LLM) allows users to customize the model to perform better on domain-specific tasks or align more closely with human preferences. You can use supervised fine-tuning (SFT) and instruction tuning to train the LLM to perform better on specific tasks using human-annotated datasets and instructions.
Amazon SageMaker is a cloud-based machine learning (ML) platform within the AWS ecosystem that offers developers a seamless and convenient way to build, train, and deploy ML models. He focuses on architecting and implementing large-scale generative AI and classic ML pipeline solutions.
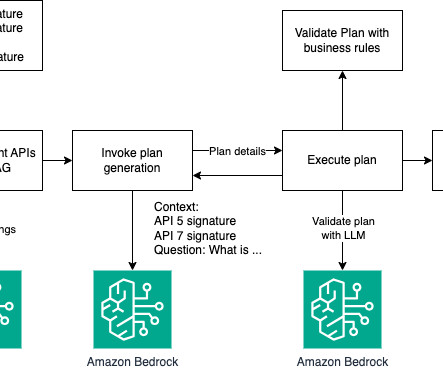
The goal of this blog post is to show you how a large language model (LLM) can be used to perform tasks that require multi-step dynamic reasoning and execution. Fig 1: Simple execution flow solution overview In a more complex scheme, you can add multiple layers of validation and provide relevant APIs to increase the success rate of the LLM.
Currently, I am working on Large Language Model (LLM) based autonomous agents. I have previously worked on sequence models for DNA and RNA, and benchmarks for evaluating the interpretability and fairness of ML models across domains. Specifically, I work on methods that algorithmically generates diverse training environments (i.e.,
Edited Photo by Taylor Vick on Unsplash In MLengineering, data quality isn’t just critical — it’s foundational. Yet, this perspective often gets sidelined and there was never a consensus in the ML community about it. Because of how ML practitioners were initially trained. That early obsession with algorithms was vital.
This transcription then serves as the input for a powerful LLM, which draws upon its vast knowledge base to provide personalized, context-aware responses tailored to your specific situation. LLM integration The preprocessed text is fed into a powerful LLM tailored for the healthcare and life sciences (HCLS) domain.
This enhancement allows customers running high-throughput production workloads to handle sudden traffic spikes more efficiently, providing more predictable scaling behavior and minimal impact on end-user latency across their ML infrastructure, regardless of the chosen inference framework.
Amazon SageMaker supports geospatial machine learning (ML) capabilities, allowing data scientists and MLengineers to build, train, and deploy ML models using geospatial data. SageMaker Processing provisions cluster resources for you to run city-, country-, or continent-scale geospatial ML workloads.
Large language models (LLMs) have achieved remarkable success in various natural language processing (NLP) tasks, but they may not always generalize well to specific domains or tasks. You may need to customize an LLM to adapt to your unique use case, improving its performance on your specific dataset or task.
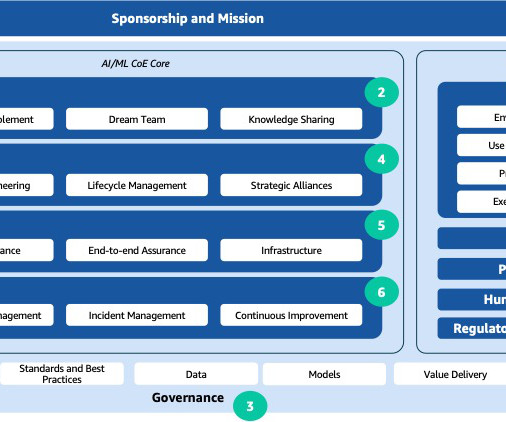
The rapid advancements in artificial intelligence and machine learning (AI/ML) have made these technologies a transformative force across industries. An effective approach that addresses a wide range of observed issues is the establishment of an AI/ML center of excellence (CoE). What is an AI/ML CoE?
Whether an engineer is cleaning a dataset, building a recommendation engine, or troubleshooting LLM behavior, these cognitive skills form the bedrock of effective AI development. Engineers who can visualize data, explain outputs, and align their work with business objectives are consistently more valuable to theirteams.
Recently, Yandex has introduced a new solution: YaFSDP, an open-source tool that promises to revolutionize LLM training by significantly reducing GPU resource consumption and training time. MLengineers can leverage this tool to enhance the efficiency of their LLM training processes. Check out the GitHub Page.
Get started with SageMaker JumpStart SageMaker JumpStart is a machine learning (ML) hub that can help accelerate your ML journey. Marc Karp is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale.
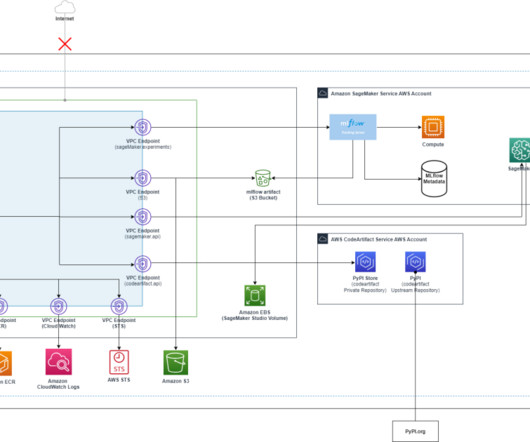
This post explores how Amazon SageMaker AI with MLflow can help you as a developer and a machine learning (ML) practitioner efficiently experiment, evaluate generative AI agent performance, and optimize their applications for production readiness. You can follow this example by running the code in the same aws-samples GitHub repository.
It supports multiple LLM providers, making it compatible with a wide array of hosted and local models, including OpenAI’s models, Anthropic’s Claude, and Google Gemini. This combination of technical depth and usability lowers the barrier for data scientists and MLengineers to generate synthetic data efficiently.
GenAI evaluation with SME-evaluator agreement AI/MLengineers develop specialized evaluators with ground truth. Lets consider an LLM-as-a-Judge (LLMAJ) which checks to see if an AI assistant has repeated itself. Its far more likely that the AI/MLengineer needs to go back and continue iterating on the prompt.
Building Multimodal AI Agents: Agentic RAG with Image, Text, and Audio Inputs Suman Debnath, Principal AI/ML Advocate at Amazon Web Services Discover the transformative potential of Multimodal Agentic RAG systems that integrate image, audio, and text to power intelligent, real-world applications.
This innovative system employs large language models (LLMs) to streamline key stages of research, including literature review, experimentation, and report writing. Dont Forget to join our 60k+ ML SubReddit. Agent Laboratory comprises a pipeline of specialized agents tailored to specific research tasks.
Building Multimodal AI Agents: Agentic RAG with Vision-Language Models Suman Debnath, Principal AI/ML Advocate at Amazon WebServices Building a truly intelligent AI assistant requires overcoming the limitations of native Retrieval-Augmented Generation (RAG) models, especially when handling diverse data types like text, tables, and images.
The Top Secret Behind Effective LLM Training in 2024 Large-scale unsupervised language models (LMs) have shown remarkable capabilities in understanding and generating human-like text. MLEngineers(LLM), Tech Enthusiasts, VCs, etc. Anybody previously acquainted with ML terms should be able to follow along.
Introduction to AI and Machine Learning on Google Cloud This course introduces Google Cloud’s AI and ML offerings for predictive and generative projects, covering technologies, products, and tools across the data-to-AI lifecycle. It includes labs on feature engineering with BigQuery ML, Keras, and TensorFlow.
About the Authors Rajesh Ramchander is a Principal MLEngineer in Professional Services at AWS. He helps customers at various stages in their AI/ML and GenAI journey, from those that are just getting started all the way to those that are leading their business with an AI-first strategy.
Libraries STORM(Synthesis of Topic Outlines through Retrieval and Multi-perspective Question Asking) is a LLM system that writes Wikipedia-like articles from scratch based on Internet search. local-gemma provides an easy way to run Gemma-2 locally directly from your CLI (or via a Python library) and fast. Hardware: Trained on H100 GPUs
AI agents, on the other hand, hold a lot of promise but are still constrained by the reliability of LLM reasoning. From an engineering perspective, the core challenge for both lies in improving accuracy and reliability to meet real-world business requirements. They also inspired a bunch of new potentials for MLengineers.
Machine learning (ML) engineers have traditionally focused on striking a balance between model training and deployment cost vs. performance. This is important because training ML models and then using the trained models to make predictions (inference) can be highly energy-intensive tasks.
Our proposed architecture provides a scalable and customizable solution for online LLM monitoring, enabling teams to tailor your monitoring solution to your specific use cases and requirements. We suggest that each module take incoming inference requests to the LLM, passing prompt and completion (response) pairs to metric compute modules.
We formulated a text-to-SQL approach where by a user’s natural language query is converted to a SQL statement using an LLM. This data is again provided to an LLM, which is asked to answer the user’s query given the data. The relevant information is then provided to the LLM for final response generation.
However, when evaluations provide deep insights into the behavior of GenAI applications, AI/MLengineers can quickly identify what improvements are needed and correctly determine the best way to implement them resulting in a much faster, and far more efficient, GenAI development process.
Attackers may attempt to fine-tune surrogate models using queries to the target LLM to reverse-engineer its knowledge. Adversaries can also attempt to breach cloud environments hosting LLMs to sabotage operations or exfiltrate data. Stolen models also create additional attack surface for adversaries to mount further attacks.
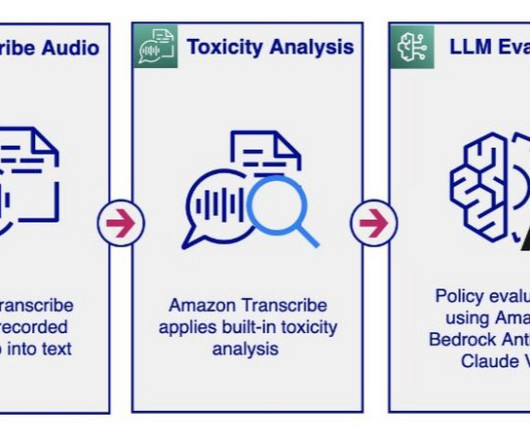
The LLM analysis provides a violation result (Y or N) and explains the rationale behind the model’s decision regarding policy violation. The audio moderation workflow activates the LLM’s policy evaluation only when the toxicity analysis exceeds a set threshold. LLMs, in contrast, offer a high degree of flexibility.
In part 1 of this blog series, we discussed how a large language model (LLM) available on Amazon SageMaker JumpStart can be fine-tuned for the task of radiology report impression generation. We also explore the utility of the RAG prompt engineering technique as it applies to the task of summarization.
They enable efficient context retrieval or dynamic few-shot prompting to improve the factual accuracy of LLM-generated responses. Use re-ranking or contextual compression techniques to ensure only the most relevant information is provided to the LLM, improving response accuracy and reducing cost.
You can use Amazon SageMaker Model Building Pipelines to collaborate between multiple AI/ML teams. SageMaker Pipelines You can use SageMaker Pipelines to define and orchestrate the various steps involved in the ML lifecycle, such as data preprocessing, model training, evaluation, and deployment. We use Python to do this.
Snorkel AI held its Enterprise LLM Virtual Summit on October 26, 2023, drawing an engaged crowd of more than 1,000 attendees across three hours and eight sessions that featured 11 speakers. How to fine-tune and customize LLMs Hoang Tran, MLEngineer at Snorkel AI, outlined how he saw LLMs creating value in enterprise environments.
Specialist Data Engineering at Merck, and Prabakaran Mathaiyan, Sr. MLEngineer at Tiger Analytics. The large machine learning (ML) model development lifecycle requires a scalable model release process similar to that of software development. The input to the training pipeline is the features dataset.
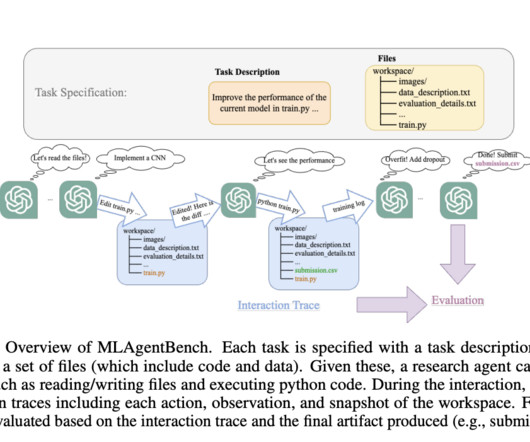
The team started with a collection of 15 MLengineering projects spanning various fields, with experiments that are quick and cheap to run. At a high level, they simply ask the LLMs to take the next action, using a prompt that is automatically produced based on the available information about the task and previous steps.
Building LLMs for Production: Enhancing LLM Abilities and Reliability with Prompting, Fine-Tuning, and RAG” is now available on Amazon! The application topics include prompting, RAG, agents, fine-tuning, and deployment — all essential topics in an AI Engineer’s toolkit.” The defacto manual for AI Engineering.
Furthermore, we deep dive on the most common generative AI use case of text-to-text applications and LLM operations (LLMOps), a subset of FMOps. The ML consumers are other business stakeholders who use the inference results (predictions) to drive decisions. The following figure illustrates the topics we discuss.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content