This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Evaluating large language models (LLMs) is crucial as LLM-based systems become increasingly powerful and relevant in our society. Rigorous testing allows us to understand an LLMs capabilities, limitations, and potential biases, and provide actionable feedback to identify and mitigate risk.
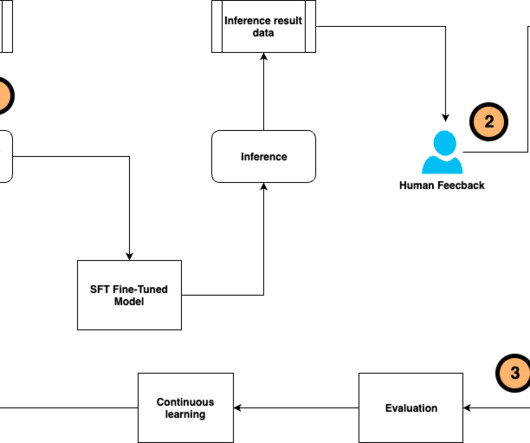
Fine-tuning a pre-trained large language model (LLM) allows users to customize the model to perform better on domain-specific tasks or align more closely with human preferences. You can use supervised fine-tuning (SFT) and instruction tuning to train the LLM to perform better on specific tasks using human-annotated datasets and instructions.
Adaptive RAG Systems with Knowledge Graphs: Building Smarter LLM Pipelines David vonThenen, Senior AI/MLEngineer at DigitalOcean Unlock the full potential of Retrieval-Augmented Generation by embedding adaptive reasoning with knowledge graphs.
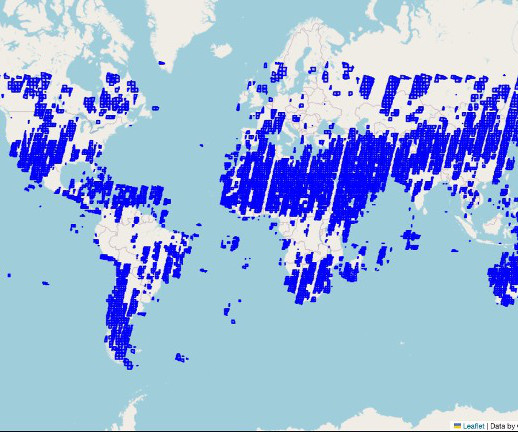
Amazon SageMaker supports geospatial machine learning (ML) capabilities, allowing data scientists and MLengineers to build, train, and deploy ML models using geospatial data. His current area of research includes LLM evaluation and data generation. About the Author Xiong Zhou is a Senior Applied Scientist at AWS.
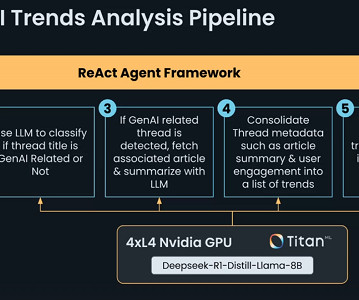
The AI agent classified and summarized GenAI-related content from Reddit, using a structured pipeline with utility functions for API interactions, web scraping, and LLM-based reasoning. The session emphasized the accessibility of AI development and the increasing efficiency of AI-assisted softwareengineering.
MLflow , a popular open-source tool, helps data scientists organize, track, and analyze ML and generative AI experiments, making it easier to reproduce and compare results. SageMaker is a comprehensive, fully managed ML service designed to provide data scientists and MLengineers with the tools they need to handle the entire ML workflow.
Machine learning (ML) engineers must make trade-offs and prioritize the most important factors for their specific use case and business requirements. Enterprise Solutions Architect at AWS, experienced in SoftwareEngineering, Enterprise Architecture, and AI/ML. Nitin Eusebius is a Sr.
About Building LLMs for Production Generative AI and LLMs are transforming industries with their ability to understand and generate human-like text and images. However, building reliable and scalable LLM applications requires a lot of extra work and a deep understanding of various techniques and frameworks.
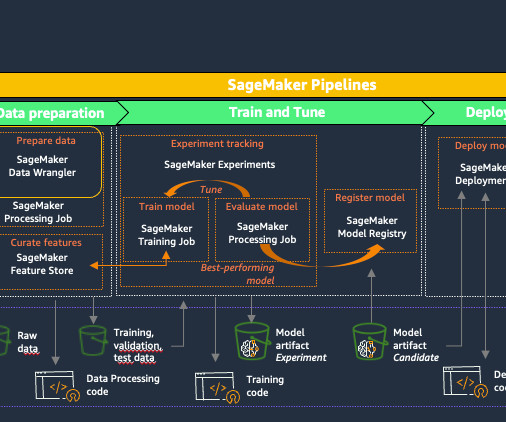
Solution overview In the following sections, we share how you can develop an example ML project with Code Editor on Amazon SageMaker Studio. We will deploy a Mistral-7B large language model (LLM) model into an Amazon SageMaker real-time endpoint using a built-in container from HuggingFace.
Topics Include: Agentic AI DesignPatterns LLMs & RAG forAgents Agent Architectures &Chaining Evaluating AI Agent Performance Building with LangChain and LlamaIndex Real-World Applications of Autonomous Agents Who Should Attend: Data Scientists, Developers, AI Architects, and MLEngineers seeking to build cutting-edge autonomous systems.
Data scientists and machine learning (ML) engineers use pipelines for tasks such as continuous fine-tuning of large language models (LLMs) and scheduled notebook job workflows. Create a complete AI/ML pipeline for fine-tuning an LLM using drag-and-drop functionality. But fine-tuning an LLM just once isn’t enough.
AI Agents AI SoftwareEngineering Agents: What Works and WhatDoesnt Robert Brennan | CEO | All HandsAI AI is reshaping software development, but are autonomous coding agents like Devin and OpenHands a game-changer or just hype? These luminaries come from the companies and institutions at the forefront of innovation.
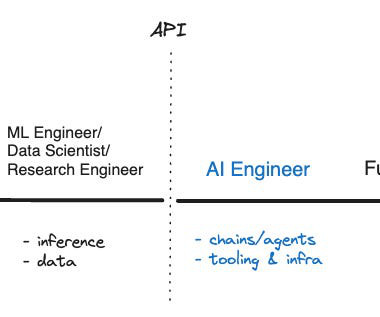
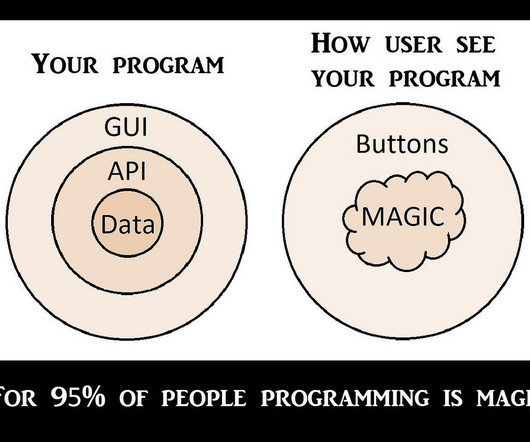
You probably don’t need MLengineers In the last two years, the technical sophistication needed to build with AI has dropped dramatically. MLengineers used to be crucial to AI projects because you needed to train custom models from scratch. Instead, Twain employs linguists and salespeople as prompt engineers.
This makes Amazon Comprehend particularly helpful for redacting PII from unstructured text that may contain a mix of PII and non-PII words (for example, support tickets or LLM prompts) that is stored in a tabular format. Amazon SageMaker provides purpose-built tools for ML teams to automate and standardize processes across the ML lifecycle.
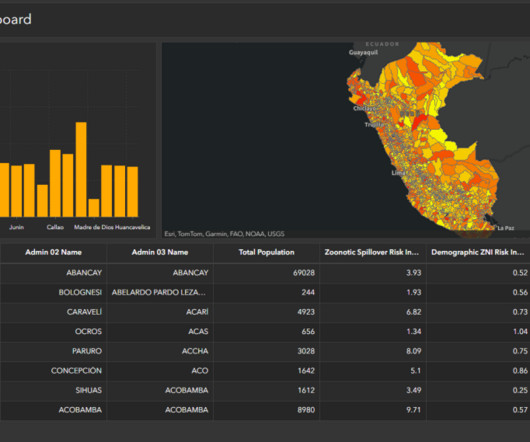
SageMaker geospatial capabilities make it easy for data scientists and machine learning (ML) engineers to build, train, and deploy models using geospatial data. With over 15 years of experience, he supports customers globally in leveraging AI and ML for innovative solutions that capitalize on geospatial data.
As a softwareengineer your role is to write code for a certain cause. As a software developer the more versed you are in DevOps the better you can foresee issues, fix bugs and be a valued team member. As an MLengineer you’re in charge of some code/model. Same analogy applies to MLOps.
Collaborative workflows : Dataset storage and versioning tools should support collaborative workflows, allowing multiple users to access and contribute to datasets simultaneously, ensuring efficient collaboration among MLengineers, data scientists, and other stakeholders. LLM training configurations.
collection of multilingual large language models (LLMs), which includes pre-trained and instruction tuned generative AI models in 8B, 70B, and 405B sizes, is available through Amazon SageMaker JumpStart to deploy for inference. Architecturally, the core LLM for Llama 3 and Llama 3.1 models using SageMaker JumpStart.
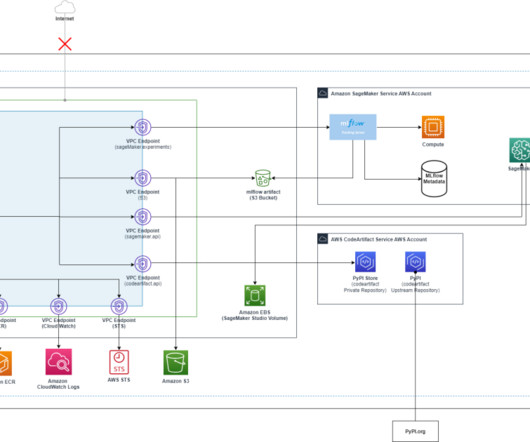
This integration addresses these hurdles by providing data scientists and MLengineers with a comprehensive environment that supports the entire ML lifecycle, from development to deployment at scale. In this post, we walk you through the process of scaling your ML workloads using SageMaker Studio and SageMaker HyperPod.
The second script shows how to query those embeddings with an LLM for RAG-based Q&A. This quick workflow lets you maintain a powerful, scalable knowledge base for any LLM-powered application. The first script ingests text data, chunks it, creates embeddings, and writes them to Neo4j. This is for demonstration purposesonly! .")
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content