This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
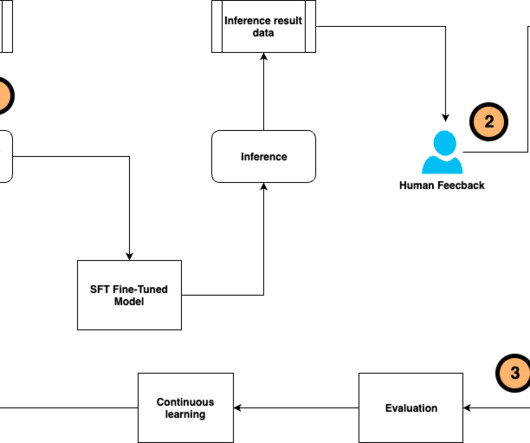
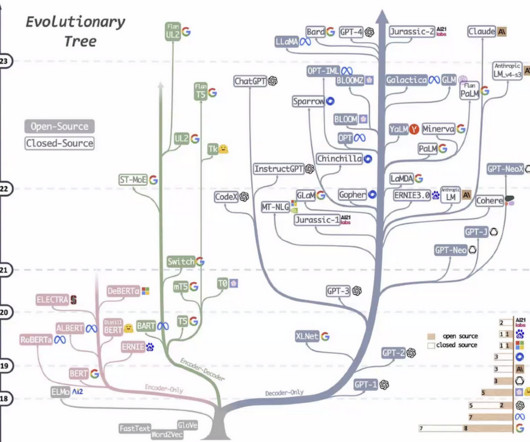
Evaluating large language models (LLMs) is crucial as LLM-based systems become increasingly powerful and relevant in our society. Rigorous testing allows us to understand an LLMs capabilities, limitations, and potential biases, and provide actionable feedback to identify and mitigate risk.
Fine-tuning a pre-trained large language model (LLM) allows users to customize the model to perform better on domain-specific tasks or align more closely with human preferences. You can use supervised fine-tuning (SFT) and instruction tuning to train the LLM to perform better on specific tasks using human-annotated datasets and instructions.
Large language models (LLMs) have achieved remarkable success in various natural language processing (NLP) tasks, but they may not always generalize well to specific domains or tasks. You may need to customize an LLM to adapt to your unique use case, improving its performance on your specific dataset or task.
In part 1 of this blog series, we discussed how a large language model (LLM) available on Amazon SageMaker JumpStart can be fine-tuned for the task of radiology report impression generation. When summarizing healthcare texts, pre-trained LLMs do not always achieve optimal performance. There are many promptengineering techniques.
Introduction to Large Language Models Difficulty Level: Beginner This course covers large language models (LLMs), their use cases, and how to enhance their performance with prompt tuning. It includes over 20 hands-on projects to gain practical experience in LLMOps, such as deploying models, creating prompts, and building chatbots.
Building LLMs for Production: Enhancing LLM Abilities and Reliability with Prompting, Fine-Tuning, and RAG” is now available on Amazon! The application topics include prompting, RAG, agents, fine-tuning, and deployment — all essential topics in an AI Engineer’s toolkit.” The defacto manual for AI Engineering.
Machine learning (ML) engineers must make trade-offs and prioritize the most important factors for their specific use case and business requirements. For more information on application security, refer to Safeguard a generative AI travel agent with promptengineering and Amazon Bedrock Guardrails.
Introduction to AI and Machine Learning on Google Cloud This course introduces Google Cloud’s AI and ML offerings for predictive and generative projects, covering technologies, products, and tools across the data-to-AI lifecycle. It includes lessons on vector search and text embeddings, practical demos, and a hands-on lab.
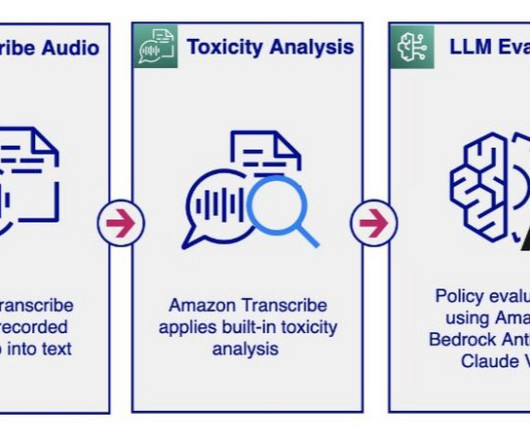
The LLM analysis provides a violation result (Y or N) and explains the rationale behind the model’s decision regarding policy violation. The audio moderation workflow activates the LLM’s policy evaluation only when the toxicity analysis exceeds a set threshold. LLMs, in contrast, offer a high degree of flexibility.
Instead, Vitech opted for Retrieval Augmented Generation (RAG), in which the LLM can use vector embeddings to perform a semantic search and provide a more relevant answer to users when interacting with the chatbot. PromptengineeringPromptengineering is crucial for the knowledge retrieval system.
About Building LLMs for Production Generative AI and LLMs are transforming industries with their ability to understand and generate human-like text and images. However, building reliable and scalable LLM applications requires a lot of extra work and a deep understanding of various techniques and frameworks.
However, with the advent of LLM, everything has changed. LLMs seem to rule them all, and interestingly, no one knows how LLMs work. Now, people are questioning whether they should still develop solutions other than LLM but know little about how to make LLM-based solutions accountable.
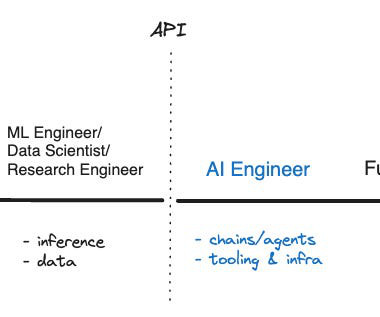
You will also find useful tools from the community, collaboration opportunities for diverse skill sets, and, in my industry-special Whats AI section, I will dive into the most sought-after role: LLM developers. But who exactly is an LLM developer, and how are they different from software developers and MLengineers?
In this post, we walk you through deploying a Falcon large language model (LLM) using Amazon SageMaker JumpStart and using the model to summarize long documents with LangChain and Python. SageMaker is a HIPAA-eligible managed service that provides tools that enable data scientists, MLengineers, and business analysts to innovate with ML.
You probably don’t need MLengineers In the last two years, the technical sophistication needed to build with AI has dropped dramatically. MLengineers used to be crucial to AI projects because you needed to train custom models from scratch. LLMs change this.
📌 MLEngineering Event: Join Meta, PepsiCo, RiotGames, Uber & more at apply(ops) apply(ops) is in two days! SAVE MY SPOT 🔎 ML Research LLM Pruning Microsoft Research published a research paper proposing LoRAShear, a technique for pruning and recovering knowledge in LLMs.
Feature Engineering and Model Experimentation MLOps: Involves improving ML performance through experiments and feature engineering. LLMOps: LLMs excel at learning from raw data, making feature engineering less relevant. The focus shifts towards promptengineering and fine-tuning.
You will also become familiar with the concept of LLM as a reasoning engine that can power your applications, paving the way to a new landscape of software development in the era of Generative AI.
Selected Training Sessions for Week 1LLMs (Wed 15 JanThu 16Jan) Cracking the Code: How to Choose the Right LLMs Model for Your Project Ivan Lee, CEO and Founder ofDatasaur Selecting the right AI model is a strategic process that requires careful evaluation and optimization to ensure project success.
The platform also offers features for hyperparameter optimization, automating model training workflows, model management, promptengineering, and no-code ML app development. LLM training configurations. Guardrails: – Does pydantic-style validation of LLM outputs. recovery from node failures).
That means curating an optimized set of prompts and responses for instruction tuning as well as cultivating the right mix of pre-training data for self-supervision. Snorkel Foundry will allow customers to programmatically curate unstructured data to pre-train an LLM for a specific domain.
That means curating an optimized set of prompts and responses for instruction tuning as well as cultivating the right mix of pre-training data for self-supervision. Snorkel Foundry will allow customers to programmatically curate unstructured data to pre-train an LLM for a specific domain.
Furthermore, we deep dive on the most common generative AI use case of text-to-text applications and LLM operations (LLMOps), a subset of FMOps. MLOps engineers are responsible for providing a secure environment for data scientists and MLengineers to productionize the ML use cases.
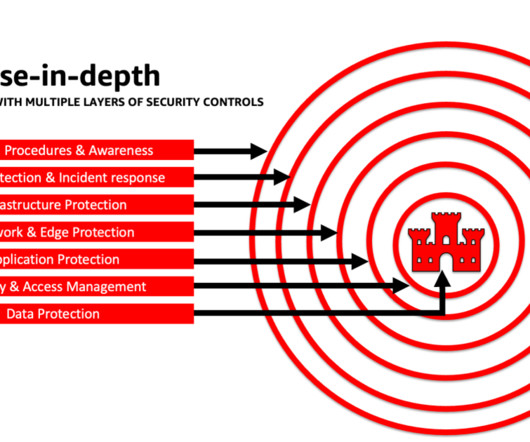
Understanding and addressing LLM vulnerabilities, threats, and risks during the design and architecture phases helps teams focus on maximizing the economic and productivity benefits generative AI can bring. This post provides three guided steps to architect risk management strategies while developing generative AI applications using LLMs.
This includes implementation of industry best practice measures and industry frameworks, such as NIST , OWASP-LLM , OWASP-ML , MITRE Atlas. AI/ML Specialist Solutions Architect at AWS, based in Virginia, US. Vikram Elango is a Sr.
However, harnessing this potential while ensuring the responsible and effective use of these models hinges on the critical process of LLM evaluation. An evaluation is a task used to measure the quality and responsibility of output of an LLM or generative AI service. Who needs to perform LLM evaluation?
Amazon SageMaker helps data scientists and machine learning (ML) engineers build FMs from scratch, evaluate and customize FMs with advanced techniques, and deploy FMs with fine-grain controls for generative AI use cases that have stringent requirements on accuracy, latency, and cost. Of the six challenges, the LLM met only one.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content