This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The effectiveness of RAG heavily depends on the quality of context provided to the large language model (LLM), which is typically retrieved from vector stores based on user queries. To address these challenges, you can use LLMs to create a robust solution.
Similar to how a customer service team maintains a bank of carefully crafted answers to frequently asked questions (FAQs), our solution first checks if a users question matches curated and verified responses before letting the LLM generate a new answer. No LLM invocation needed, response in less than 1 second.
Enter Chronos , a cutting-edge family of time series models that uses the power of large language model ( LLM ) architectures to break through these hurdles. It stores models, organizes model versions, captures essential metadata and artifacts such as container images, and governs the approval status of each model.
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
This approach has two primary shortcomings: Missed Contextual Signals : Without considering metadata such as source URLs, LMs overlook important contextual information that could guide their understanding of a texts intent or quality. Addressing these inefficiencies is essential for developing more effective and versatile language models.
Used alongside other techniques such as prompt engineering, RAG, and contextual grounding checks, Automated Reasoning checks add a more rigorous and verifiable approach to enhancing the accuracy of LLM-generated outputs. Amazon Bedrock Evaluations addresses this by helping you evaluate, compare, and select the best FMs for your use case.
Large language models (LLMs) have achieved remarkable success in various naturallanguageprocessing (NLP) tasks, but they may not always generalize well to specific domains or tasks. You may need to customize an LLM to adapt to your unique use case, improving its performance on your specific dataset or task.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. Most of today’s largest foundation models, including the large language model (LLM) powering ChatGPT, have been trained on information culled from the internet. Increase trust in AI outcomes.
Large language models (LLMs) are revolutionizing fields like search engines, naturallanguageprocessing (NLP), healthcare, robotics, and code generation. The personalization of LLM applications can be achieved by incorporating up-to-date user information, which typically involves integrating several components.
Sonnet model for naturallanguageprocessing. For example, we export pre-chunked asset metadata from our asset library to Amazon S3, letting Amazon Bedrock handle embeddings, vector storage, and search. Agents use this system in a loop to call functions and process their output until a success criterion is reached.
You can use metadata filtering to narrow down search results by specifying inclusion and exclusion criteria. For a demonstration on how you can use a RAG evaluation framework in Amazon Bedrock to compute RAG quality metrics, refer to New RAG evaluation and LLM-as-a-judge capabilities in Amazon Bedrock.
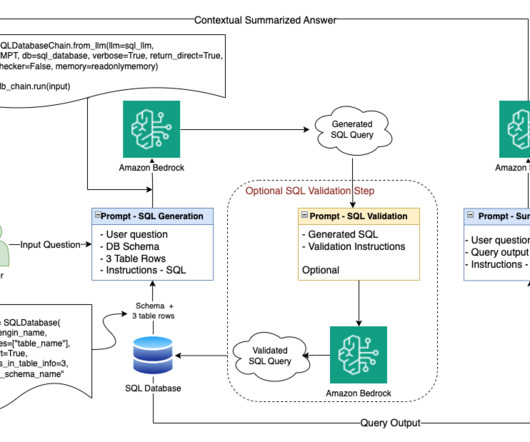
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. This generative AI task is called text-to-SQL, which generates SQL queries from naturallanguageprocessing (NLP) and converts text into semantically correct SQL. on Amazon Bedrock as our LLM.
In NaturalLanguageProcessing (NLP) tasks, data cleaning is an essential step before tokenization, particularly when working with text data that contains unusual word separations such as underscores, slashes, or other symbols in place of spaces.
The emergence of generative AI agents in recent years has contributed to the transformation of the AI landscape, driven by advances in large language models (LLMs) and naturallanguageprocessing (NLP). It might ask follow-up questions to clarify ambiguous points or gather more specific preferences.
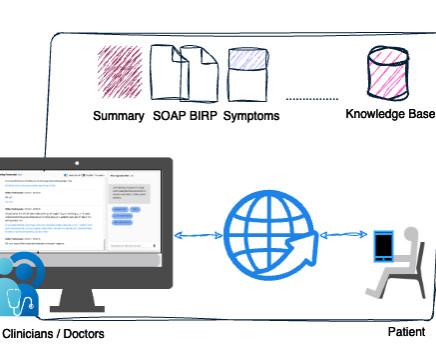
To create AI assistants that are capable of having discussions grounded in specialized enterprise knowledge, we need to connect these powerful but generic LLMs to internal knowledge bases of documents. The search precision can also be improved with metadata filtering.
With this LLM, CreditAI was now able to respond better to broader, industry-wide queries than before. Lambda functions process the event payload containing document location, perform format validation, and prepare content for extraction. Amazon Textract processes the documents to extract both text and structural information.
Using naturallanguageprocessing (NLP) and OpenAPI specs, Amazon Bedrock Agents dynamically manages API sequences, minimizing dependency management complexities. The LLM generates a summary of the damage, which is sent to an SQS queue, and is subsequently reviewed by the claim adjusters.
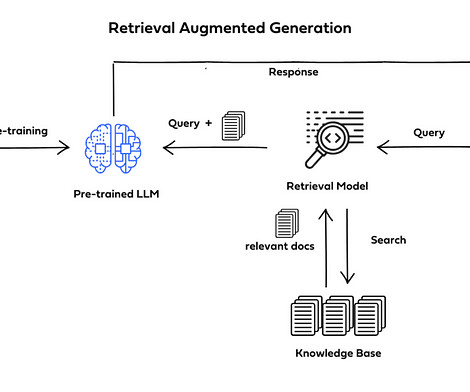
Retrieval-Augmented Generation (RAG) is a cutting-edge method of naturallanguageprocessing that produces precise and contextually relevant answers by fusing the strength of large language models (LLMs) with an external knowledge retrieval system. Generation : After augmentation, the input for the LLM is ready.
Participants learn to build metadata for documents containing text and images, retrieve relevant text chunks, and print citations using Multimodal RAG with Gemini. NaturalLanguageProcessing on Google Cloud This course introduces Google Cloud products and solutions for solving NLP problems.
The new SageMaker JumpStart Foundation Hub allows you to easily deploy large language models (LLM) and integrate them with your applications. First, you extract label and celebrity metadata from the images, using Amazon Rekognition. You then generate an embedding of the metadata using a LLM.
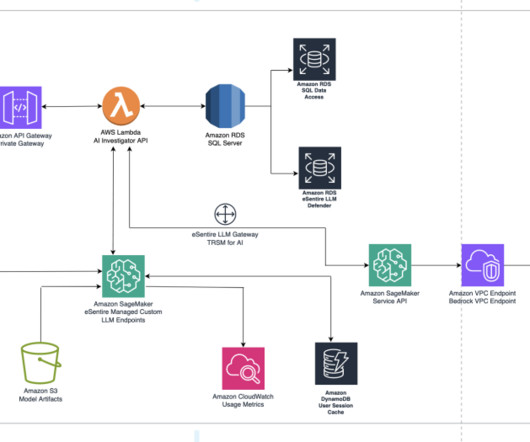
Providing AI Investigator internally to the eSentire SOC workbench has also accelerated eSentire’s investigation process by improving the scale and efficacy of multi-telemetry investigations. Therefore, eSentire decided to build their own LLM using Llama 1 and Llama 2 foundational models.
In order to update this knowledge, we must retrain the LLM, which takes a lot of time and money. Fortunately, we can also use source knowledge to inform our LLMs. Source knowledge is information fed into the LLM through an input prompt. Deploying an LLM In this post, we discuss two approaches to deploying an LLM.
Advanced parsing Advanced parsing is the process of analyzing and extracting meaningful information from unstructured or semi-structured documents. It involves breaking down the document into its constituent parts, such as text, tables, images, and metadata, and identifying the relationships between these elements.
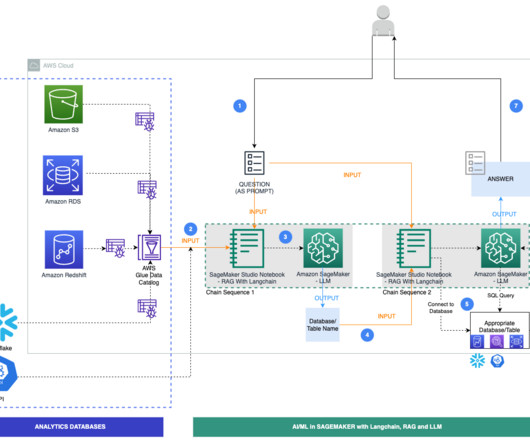
Solution overview A modern data architecture on AWS applies artificial intelligence and naturallanguageprocessing to query multiple analytics databases. An AWS Glue crawler is scheduled to run at frequent intervals to extract metadata from databases and create table definitions in the AWS Glue Data Catalog.
From customer service and ecommerce to healthcare and finance, the potential of LLMs is being rapidly recognized and embraced. Businesses can use LLMs to gain valuable insights, streamline processes, and deliver enhanced customer experiences. The raw data is processed by an LLM using a preconfigured user prompt.
By understanding its significance, readers can grasp how it empowers advancements in AI and contributes to cutting-edge innovation in naturallanguageprocessing. Key Takeaways The Pile dataset is an 800GB open-source resource designed for AI research and LLM training. Frequently Asked Questions What is the Pile dataset?
It’s developed by BAAI and is designed to enhance retrieval capabilities within large language models (LLMs). The model supports three retrieval methods: Dense retrieval (BGE-M3) Lexical retrieval (LLM Embedder) Multi-vector retrieval (BGE Embedding Reranker). The LLMprocesses the request and generates an appropriate response.
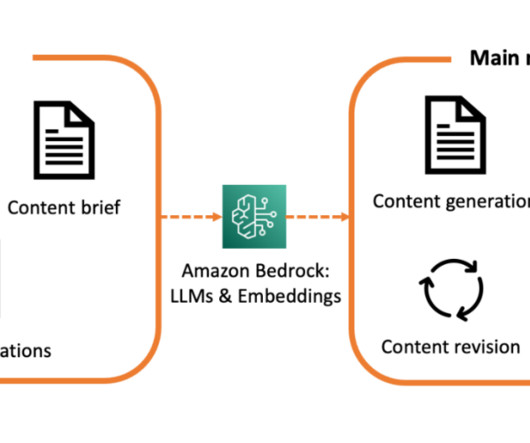
The system is built upon Amazon Bedrock and leverages LLM capabilities to generate curated medical content for disease awareness. With this AI assistant, we can effectively reduce the overall generation time from weeks to hours, while giving the subject matter experts (SMEs) more control over the generation process.
Large Language Models (LLMs) Concepts Difficulty Level: Beginner This course explores Large Language Models (LLMs), their impact on AI, and real-world applications. It helps learn about LLM building blocks, training methodologies, and ethical considerations.
I have written short summaries of 68 different research papers published in the areas of Machine Learning and NaturalLanguageProcessing. link] The paper investigates LLM robustness to prompt perturbations, measuring how much task performance drops for different models with different attacks. ArXiv 2023.
The following are some of the experiments that were conducted by the team, along with the challenges identified and lessons learned: Pre-training – Q4 understood the complexity and challenges that come with pre-training an LLM using its own dataset. In addition to the effort involved, it would be cost prohibitive.
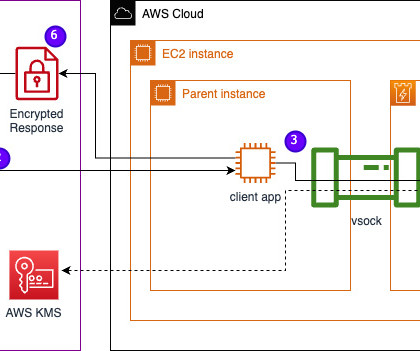
In this post, we discuss how Leidos worked with AWS to develop an approach to privacy-preserving large language model (LLM) inference using AWS Nitro Enclaves. LLMs are designed to understand and generate human-like language, and are used in many industries, including government, healthcare, financial, and intellectual property.
This could involve better preprocessing tools, semi-supervised learning techniques, and advances in naturallanguageprocessing. Data from social media, reviews, or any user generated contents can also contain toxic and biased contents, and you may need to filter them out using some pre-processing steps.
Using machine learning (ML) and naturallanguageprocessing (NLP) to automate product description generation has the potential to save manual effort and transform the way ecommerce platforms operate. BLIP-2 consists of three models: a CLIP-like image encoder, a Querying Transformer (Q-Former) and a large language model (LLM).
Large language models (LLMs) have exploded in popularity over the last few years, revolutionizing naturallanguageprocessing and AI. From chatbots to search engines to creative writing aids, LLMs are powering cutting-edge applications across industries.
Langchain is a powerful tool for building applications that understand naturallanguage. Using advanced models, we can achieve sophisticated naturallanguageprocessing tasks such as text generation, question answering, and language translation, enabling the development of highly interactive and intelligent applications.
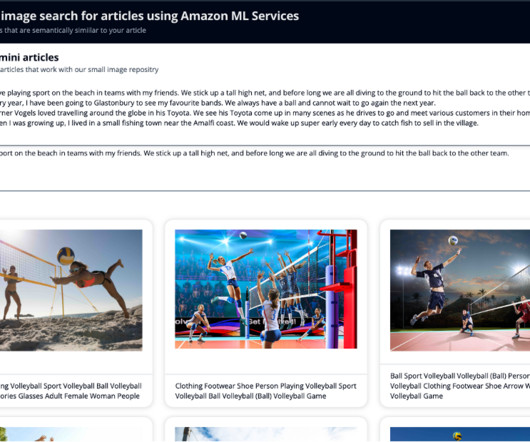
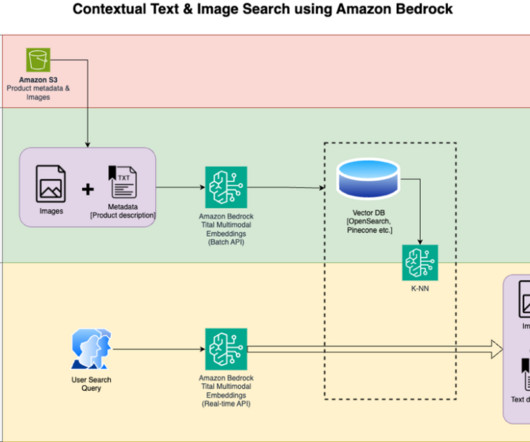
Solution overview The solution provides an implementation for building a large language model (LLM) powered search engine prototype to retrieve and recommend products based on text or image queries. Load the publicly available Amazon Berkeley Objects Dataset and metadata in a pandas data frame.
For example, if your team works on recommender systems or naturallanguageprocessing applications, you may want an MLOps tool that has built-in algorithms or templates for these use cases. Flexibility, speed, and accessibility : can you customize the metadata structure? Is it fast and reliable enough for your workflow?
The solution captures speaker audio and metadata directly from your browser-based meeting application (currently compatible with Zoom and Chime, with others coming), and audio from other browser-based meeting tools, softphones, or other audio input. During patient interactions without it, you can direct general inquiries to the LLM.
Using this context, modified prompt is constructed required for the LLM model. A request is posted to the Amazon Bedrock Claude-2 model to get the response from the LLM model selected. The data is post-processed from the LLM response and a response is sent to the user.
Large Language Models (LLMs) present a unique challenge when it comes to performance evaluation. Unlike traditional machine learning where outcomes are often binary, LLM outputs dwell in a spectrum of correctness. auto-evaluation) and using human-LLM hybrid approaches. This requires building a custom evaluation set.
You can use LLMs in one or all phases of IDP depending on the use case and desired outcome. In this architecture, LLMs are used to perform specific tasks within the IDP workflow. Document classification – In addition to using Amazon Comprehend , you can use an LLM to classify documents using few-shot prompting.
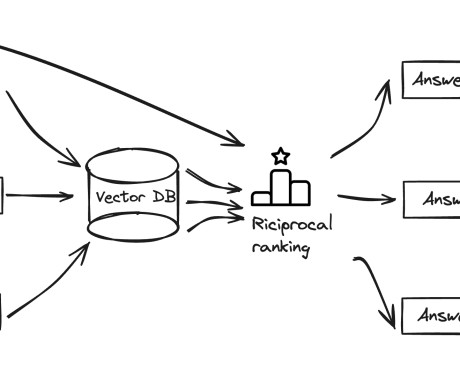
Retrieval Augmented Generation (RAG) models have emerged as a promising approach to enhance the capabilities of language models by incorporating external knowledge from large text corpora. The query will prompt the LLM to retrieve relevant vectors from both the vector database and document store and generate meaningful and accurate answers.
There is no doubt this powerful AI model becoming so popular and has opened up new possibilities for naturallanguageprocessing applications, enabling developers to create more sophisticated, human-like interactions in chatbots, question-answering systems, summarization tools, and beyond. What is Large Language Model ?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content