This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The effectiveness of RAG heavily depends on the quality of context provided to the large language model (LLM), which is typically retrieved from vector stores based on user queries. To address these challenges, you can use LLMs to create a robust solution.
Its a cost-effective approach to improving LLM output so it remains relevant, accurate, and useful in various contexts. It also provides developers with greater control over the LLMs outputs, including the ability to include citations and manage sensitive information. The user_data fields must match the metadata fields.
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.
With a growing library of long-form video content, DPG Media recognizes the importance of efficiently managing and enhancing video metadata such as actor information, genre, summary of episodes, the mood of the video, and more. Video data analysis with AI wasn’t required for generating detailed, accurate, and high-quality metadata.
Avi Perez, CTO of Pyramid Analytics, explained that his business intelligence software’s AI infrastructure was deliberately built to keep data away from the LLM , sharing only metadata that describes the problem and interfacing with the LLM as the best way for locally-hosted engines to run analysis.”There’s
Similar to how a customer service team maintains a bank of carefully crafted answers to frequently asked questions (FAQs), our solution first checks if a users question matches curated and verified responses before letting the LLM generate a new answer. No LLM invocation needed, response in less than 1 second.
This is where LLMs come into play with their capabilities to interpret customer feedback and present it in a structured way that is easy to analyze. This article will focus on LLM capabilities to extract meaningful metadata from product reviews, specifically using OpenAI API. Data We decided to use the Amazon reviews dataset.
In-context learning has emerged as an alternative, prioritizing the crafting of inputs and prompts to provide the LLM with the necessary context for generating accurate outputs. Behind the scenes, it dissects raw documents into intermediate representations, computes vector embeddings, and deduces metadata.
Evaluating large language models (LLMs) is crucial as LLM-based systems become increasingly powerful and relevant in our society. Rigorous testing allows us to understand an LLMs capabilities, limitations, and potential biases, and provide actionable feedback to identify and mitigate risk.
Enter Chronos , a cutting-edge family of time series models that uses the power of large language model ( LLM ) architectures to break through these hurdles. It stores models, organizes model versions, captures essential metadata and artifacts such as container images, and governs the approval status of each model.
Contrast that with Scope 4/5 applications, where not only do you build and secure the generative AI application yourself, but you are also responsible for fine-tuning and training the underlying large language model (LLM). LLM and LLM agent The LLM provides the core generative AI capability to the assistant.
Large language models (LLMs) are limited by complex reasoning tasks that require multiple steps, domain-specific knowledge, or external tool integration. To address these challenges, researchers have explored ways to enhance LLM capabilities through external tool usage.
However, the industry is seeing enough potential to consider LLMs as a valuable option. The following are a few potential benefits: Improved accuracy and consistency LLMs can benefit from the high-quality translations stored in TMs, which can help improve the overall accuracy and consistency of the translations produced by the LLM.
With metadata filtering now available in Knowledge Bases for Amazon Bedrock, you can define and use metadata fields to filter the source data used for retrieving relevant context during RAG. Metadata filtering gives you more control over the RAG process for better results tailored to your specific use case needs.
Solution overview By combining the powerful vector search capabilities of OpenSearch Service with the access control features provided by Amazon Cognito , this solution enables organizations to manage access controls based on custom user attributes and document metadata. If you don’t already have an AWS account, you can create one.
With the release of DeepSeek, a highly sophisticated large language model (LLM) with controversial origins, the industry is currently gripped by two questions: Is DeepSeek real or just smoke and mirrors? Why AI-native infrastructure is mission-critical Each LLM excels at different tasks.
This comprehensive documentation serves as the foundational knowledge base for code generation by providing the LLM with the necessary context to understand and generate SimTalk code. There are several critical components in our pipeline, each designed to provide the LLM with precise context.
It also mandates the labelling of deepfakes with permanent unique metadata or other identifiers to prevent misuse. Furthermore, the document outlines plans for implementing a “consent popup” mechanism to inform users about potential defects or errors produced by AI.
It not only collects data from websites but also processes and cleans it into LLM-friendly formats like JSON, cleaned HTML, and Markdown. These customizations make the tool adaptable for various data types and web structures, allowing users to gather text, images, metadata, and more in a structured way that benefits LLM training.
TL;DR LangChain provides composable building blocks to create LLM-powered applications, making it an ideal framework for building RAG systems. makes it easy for RAG developers to track evaluation metrics and metadata, enabling them to analyze and compare different system configurations. Source What is LangChain? langchain-openai== 0.0.6
🔎 Decoding LLM Pipeline Step 1: Input Processing & Tokenization 🔹 From Raw Text to Model-Ready Input In my previous post, I laid out the 8-step LLM pipeline, decoding how large language models (LLMs) process language behind the scenes. Now, lets zoom in starting with Step 1: Input Processing.
I don’t need any other information for now We get the following response from the LLM: Based on the image provided, the class of this document appears to be an ID card or identification document. The LLM has filled in the table based on the graph and its own knowledge about the capital of each country.
Extract and generate data : Find out how to extract tags and descriptions from your audio to enhance metadata and searchability with LeMUR. video conferencing app that supports video calls with live transcriptions and an LLM-powered meeting assistant. and Stream : Learn how to build a Next.js
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
In this paper researchers introduced a new framework, ReasonFlux that addresses these limitations by reimagining how LLMs plan and execute reasoning steps using hierarchical, template-guided strategies. Recent approaches to enhance LLM reasoning fall into two categories: deliberate search and reward-guided methods.
The platform automatically analyzes metadata to locate and label structured data without moving or altering it, adding semantic meaning and aligning definitions to ensure clarity and transparency. When onboarding customers, we automatically retrain these ontologies on their metadata.
This approach has two primary shortcomings: Missed Contextual Signals : Without considering metadata such as source URLs, LMs overlook important contextual information that could guide their understanding of a texts intent or quality. MeCo leverages readily available metadata, such as source URLs, during the pre-training phase.
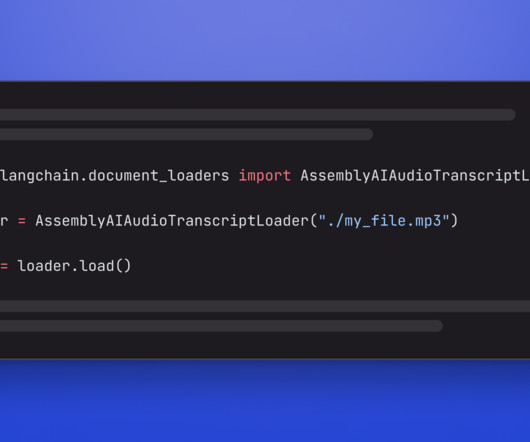
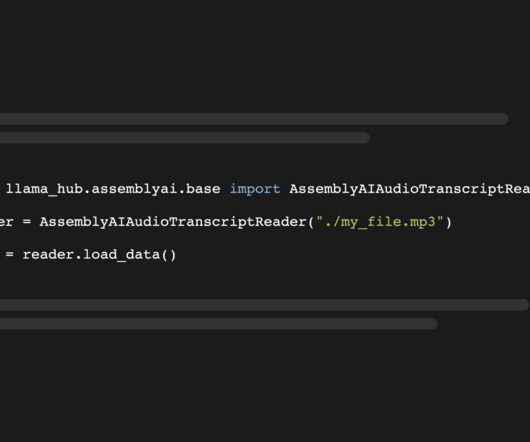
For this, we create a small demo application that lets you load audio data and apply an LLM that can answer questions about your spoken data. The metadata contains the full JSON response of our API with more meta information: print(docs[0].metadata) page_content) # Runner's knee. Runner's knee is a condition.
Customizable Uses prompt engineering , which enables customization and iterative refinement of the prompts used to drive the large language model (LLM), allowing for refining and continuous enhancement of the assessment process. Metadata filtering is used to improve retrieval accuracy.
the router would direct the query to a text-based RAG that retrieves relevant documents and uses an LLM to generate an answer based on textual information. For instance, analyzing large tables might require prompting the LLM to generate Python or SQL and running it, rather than passing the tabular data to the LLM.
For this, we create a small demo application with an LLM-powered query engine that lets you load audio data and ask questions about your data. The metadata contains the full JSON response of our API with more meta information: print(docs[0].metadata) Getting Started Create a new virtual environment: # Mac/Linux: python3 -m venv venv.
For instance, a medical LLM fine-tuned on clinical notes can make more accurate recommendations because it understands niche medical terminology. For instance, a medical LLM fine-tuned on clinical notes can make more accurate recommendations because it understands niche medical terminology.
Retrieval Augmented Generation (RAG) is a method to augment the relevance and transparency of Large Language Model (LLM) responses. In this approach, the LLM query retrieves relevant documents from a database and passes these into the LLM as additional context. as the LLM and Chroma as the retriever vector database.
Large language models (LLMs) have achieved remarkable success in various natural language processing (NLP) tasks, but they may not always generalize well to specific domains or tasks. You may need to customize an LLM to adapt to your unique use case, improving its performance on your specific dataset or task.
Moreover, employing an LLM for individual product categorization proved to be a costly endeavor. If it was a 4xx error, its written in the metadata of the Job. The PydanticOutputParser requires a schema to be able to parse the JSON generated by the LLM. The generated categories were often incomplete or mislabeled.
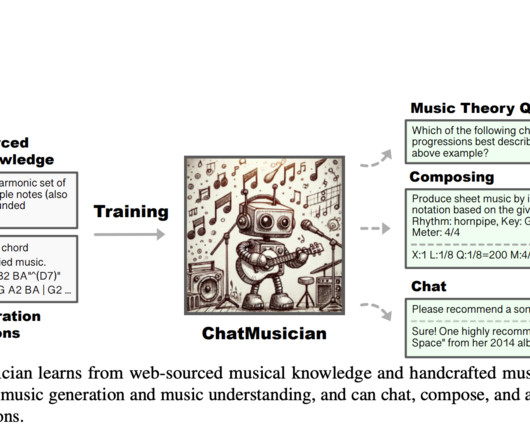
and Hong Kong University of Science and Technology have developed ChatMusician, a text-based LLM, to address these issues. Metadata like song titles, descriptions, albums, artists, lyrics, playlists, and more are crawled for 2 million music recordings on YouTube. The team uses GPT-4 to create summaries of these metadata records.
Used alongside other techniques such as prompt engineering, RAG, and contextual grounding checks, Automated Reasoning checks add a more rigorous and verifiable approach to enhancing the accuracy of LLM-generated outputs. Amazon Bedrock Evaluations addresses this by helping you evaluate, compare, and select the best FMs for your use case.
The lack of global standards or centralized databases to validate and license datasets and incomplete or inconsistent metadata makes it impossible to assess the legal status of works. Current methods of building open datasets for LLMs often lack clear legal frameworks and face significant technical, operational, and ethical challenges.
At a high level, we can detect malware that the deep learning framework tags within an attack and then feed it as metadata into the LLM model. By extracting metadata without exposing sensitive information, DIANNA provides the zero-day explainability and focused answers that customers are seeking.
Large language model (LLM) agents are programs that extend the capabilities of standalone LLMs with 1) access to external tools (APIs, functions, webhooks, plugins, and so on), and 2) the ability to plan and execute tasks in a self-directed fashion. We conclude the post with items to consider before deploying LLM agents to production.
Thats a problem, especially given that an LLM cant be fired or held accountable. It is important to do it right, with all required metadata about the information structure and attributes. Alternatively, you can use the Agents model, where several LLM agents communicate with each other and verify each other's outputs and each step.
For this demo, weve implemented metadata filtering to retrieve only the appropriate level of documents based on the users access level, further enhancing efficiency and security. The role information is also used to configure metadata filtering in the knowledge bases to generate relevant responses.
Traditional RAG pipelines generally follow a retrieve-then-read framework, where a retriever searches for document chunks related to a user’s query and then provides these chunks as context for the LLM to generate a response.
AI-generated deepfakes make it easy for anyone to create impersonations or synthetic identities whether it be of celebrities or even your boss. AI and Large Language Model (LLM) generative language applications can be used to create more sophisticated and evasive fraud that is difficult to detect and remove.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content