This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Unlocking the Power of Real-time Predictions: An Introduction to Incremental Machine Learning for LinkedData Event Streams Photo by Isaac Smith on Unsplash This article discusses online machine learning, one of the most exciting subdomains of machine learning theory. LDES workbench in Apache NIFI (Image by the author.)
Modeling the underlying academic data as an RDF knowledge graph (KG) is one efficient method. This makes standardization, visualization, and interlinking with LinkedData resources easier. As a result, scholarly KGs are essential for converting document-centric academic material into linked and automatable knowledge structures.
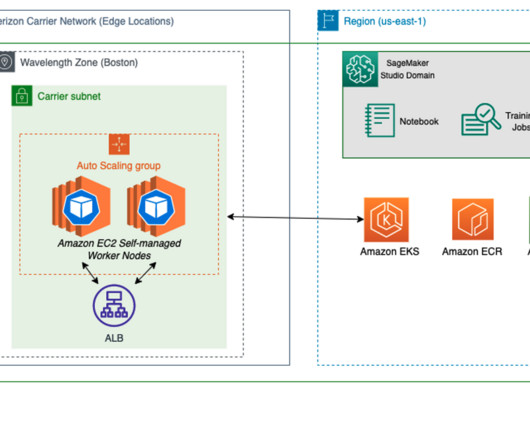
As one of the most prominent use cases to date, machine learning (ML) at the edge has allowed enterprises to deploy ML models closer to their end-customers to reduce latency and increase responsiveness of their applications. Even ground and aerial robotics can use ML to unlock safer, more autonomous operations. Instances[*].
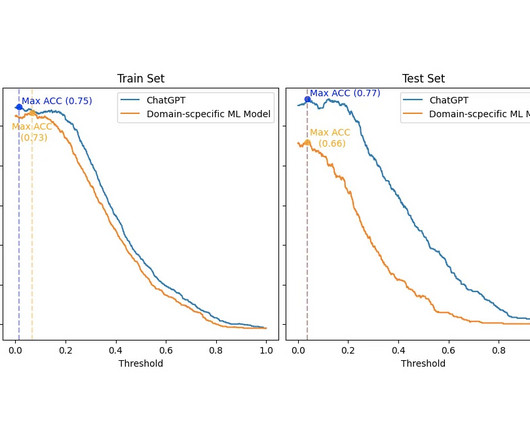
ChatGPT is a GPT ( G enerative P re-trained T ransformer) machine learning (ML) tool that has surprised the world. Moreover, its capacity to be an ML model trained for general tasks and perform very well in domain-specific situations is impressive. which ranked best on the test set) named their ML architecture Fortia-FBK.
Github : [link] Data Augmentation Techniques Engineers could also explore data augmentation techniques to increase the diversity and complexity of training data for AI algorithms. DALL-E generates images based on textual descriptions, allowing for more control over the content of the generated images.
They can provide a logical justification for such phase changes thanks to this link. Data on the flow of cognition throughout training. Based on these findings, they investigate the possible advantages of chain-of-thought data during training. Check out the Paper and Github link.
Under the academic leadership of Turing Award winner Michael Stonebraker, the question the team were investigating was “can we linkdata records across hundreds of thousands of sources and millions of records.” Bad data for them could mean a provider gets more shifts than they can handle, leading to burnout.
Here a few easy-to-use open source solutions fit for the purpose: GeoNetwork , GeoNode , pyCSW and STAC ( SpatioTemporal Asset Catalogs ) to register metadata for geospatial assets (raster and vector) and serve them; Leaflet + rio-tiler to visualise geospatial data; XCUBE + Viewer App out-of-box solution to create a web-GIS, especially suitable for (..)
with sdk v2 import libraries import tqdm import matplotlib.pyplot as plt import numpy as np import pandas as pd import seaborn as sns sns.set_style("whitegrid") import the data set # Import required libraries from azure.identity import DefaultAzureCredential from azure.identity import AzureCliCredential from azure.ai.ml
First, let’s load the dataset and split it into features and labels: import pandas as pd from sklearn.model_selection import train_test_split url = "[link] data = pd.read_csv(url, delimiter=";") features = data.drop("quality", axis=1).values.astype(np.float32)
Posted by Chansung Park and Sayak Paul (ML and Cloud GDEs) Generative AI models like Stable Diffusion 1 that lets anyone generate high-quality images from natural language text prompts enable different use cases across different industries. References CLIP: Connecting text and images, OpenAI, [link].
Please refer to this documentation link. Let's pull data from the table historical_prices [link] We can convert the Snowpark DataFrame to Pandas DataFrame [link] View Pricing data [link] Data Preprocessing After data extraction, we will check some basic information & statistics of the dataset.
In this article, we will explore some common data science interview questions that will help you prepare and increase your chances of success. Read the full blog here — [link] Data Science Interview Questions for Freshers 1. What is Data Science? This model also learns noise from the data set that is meant for training.
References / Further Resources Astronomer Documentation on Apache Airflow — [link] A comparison between Apache Airflow Executors — [link] Types of Executors in Apache Airflow — [link]. We're committed to supporting and inspiring developers and engineers from all walks of life.
After all, companies cant have AI development without fixing data first, and leaders are pulling away from the pack by using their more matured capabilities to better ideate, prioritize, and ensure adoption of more differentiating and transformational uses of data and AI.
In the context of enterprise data asset search powered by a metadata catalog hosted on services such Amazon DataZone, AWS Glue, and other third-party catalogs, knowledge graphs can help integrate this linkeddata and also enable a scalable search paradigm that integrates metadata that evolves over time.
About the Authors Simon Zamarin is an AI/ML Solutions Architect whose main focus is helping customers extract value from their data assets. Vikram Elango is an AI/ML Specialist Solutions Architect at Amazon Web Services, based in Virginia USA. Manager of AI/ML Solutions Architecture at Amazon Web Services.
Paper : [link] Model : [link] Data : [link] s1-prob: [link] s1-teasers: [link] Full 59K: [link] Pathway is a Python ETL framework for stream processing, real-time analytics, LLM pipelines, and RAG.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content