
The Hallucination Problem of Large Language Models
Mlearning.ai
SEPTEMBER 5, 2023
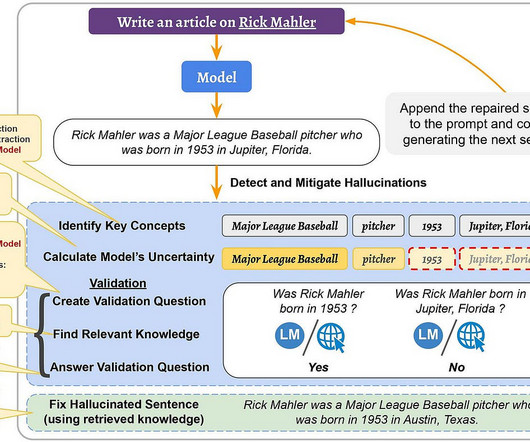
Hallucination in the context of language models refers to the generation of text or responses that seem syntactically sound, fluent, and natural but are factually incorrect, nonsensical, or unfaithful to the provided source input. Furthermore, they have been shown to possess an impressive ability to generate fluent and coherent text.







Let's personalize your content