This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Artificial intelligence has made remarkable strides in recent years, with largelanguagemodels (LLMs) leading in natural language understanding, reasoning, and creative expression. Yet, despite their capabilities, these models still depend entirely on external feedback to improve.
LargeLanguageModels (LLMs) are changing how we interact with AI. LLMs are helping us connect the dots between complicated machine-learning models and those who need to understand them. The conversational agent translates this technical information into something easy to follow.
LargeLanguageModels (LLMs) have changed how we handle natural language processing. People dont just need information; they want results. By developing these skills, LLMs can move beyond just processing information. They can answer questions, write code, and hold conversations.
This change is driven by the evolution of LargeLanguageModels (LLMs) into active, decision-making entities. These models are no longer limited to generating human-like text; they are gaining the ability to reason, plan, tool-using, and autonomously execute complex tasks. Identify frequent purchases.
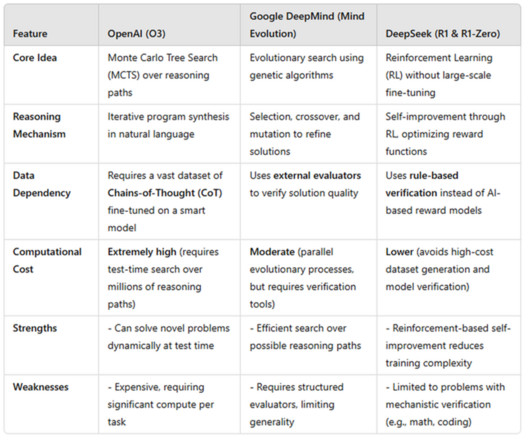
As R1 advances the reasoning abilities of largelanguagemodels, it begins to operate in ways that are increasingly difficult for humans to understand. The Rise of DeepSeek R1 DeepSeek's R1 model has quickly established itself as a powerful AI system, particularly recognized for its ability to handle complex reasoning tasks.
Artificial intelligence (AI) has come a long way, with largelanguagemodels (LLMs) demonstrating impressive capabilities in natural language processing. These models have changed the way we think about AI’s ability to understand and generate human language. But there are challenges.
The introduction of generative AI and the emergence of Retrieval-Augmented Generation (RAG) have transformed traditional information retrieval, enabling AI to extract relevant data from vast sources and generate structured, coherent responses. These systems can analyze data, navigate complex data environments, and make informed decisions.
At the forefront of this progress are largelanguagemodels (LLMs) known for their ability to understand and generate human language. The core limitation lies in how LLMs process information. Complex tasks often require keeping track of previous decisions and adapting as new information arises.
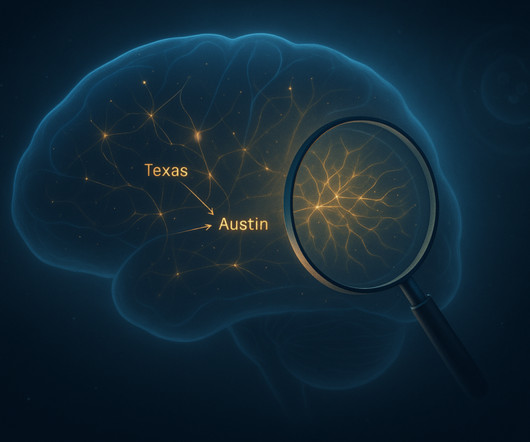
Largelanguagemodels (LLMs) like Claude have changed the way we use technology. But despite their amazing abilities, these models are still a mystery in many ways. They created a basic “map” of how Claude processes information. They power tools like chatbots, help write essays and even create poetry.
RAG, or Retrieval-Augmented Generation, has received widespread acceptance when it comes to reducing model hallucinations and enhancing the domain-specific knowledge base of largelanguagemodels (LLMs). However, recent findings in a RAG system have underscored the […] The post What is Bias in a RAG System?
Introduction In today’s digital world, LargeLanguageModels (LLMs) are revolutionizing how we interact with information and services. LLMs are advanced AI systems designed to understand and generate human-like text based on vast amounts of data.
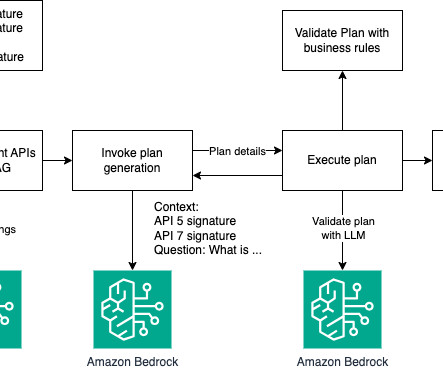
The goal of this blog post is to show you how a largelanguagemodel (LLM) can be used to perform tasks that require multi-step dynamic reasoning and execution. These tools allow LLMs to perform specialized tasks such as retrieving real-time information, running code, browsing the web, or generating images.
LargeLanguageModels (LLMs) have shown remarkable capabilities across diverse natural language processing tasks, from generating text to contextual reasoning. SepLLM leverages these tokens to condense segment information, reducing computational overhead while retaining essential context.
Largelanguagemodels (LLMs) are rapidly evolving from simple text prediction systems into advanced reasoning engines capable of tackling complex challenges. The development of reasoning techniques is the key driver behind this transformation, allowing AI models to process information in a structured and logical manner.
In recent times, AI lab researchers have experienced delays in and challenges to developing and releasing largelanguagemodels (LLM) that are more powerful than OpenAI’s GPT-4 model. First, there is the cost of training largemodels, often running into tens of millions of dollars.
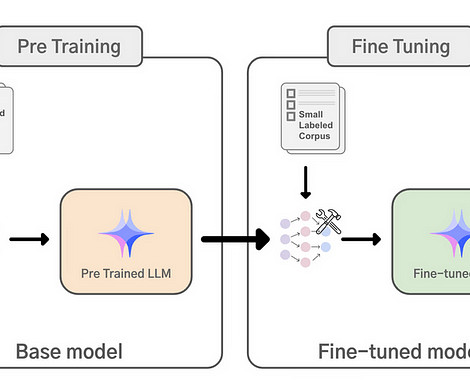
Fine-tuning largelanguagemodels (LLMs) has become an easier task today thanks to the availability of low-code/no-code tools that allow you to simply upload your data, select a base model and obtain a fine-tuned model. However, it is important to understand the fundamentals before diving into these tools.
Retrieval-Augmented Generation (RAG) enhances largelanguagemodels (LLMs) by integrating external knowledge, making responses more informative and context-aware. However, RAG fails in many scenarios, affecting its ability to generate accurate and relevant outputs.
In Artificial Intelligence, largelanguagemodels (LLMs) have become essential, tailored for specific tasks, rather than monolithic entities. In this […] The post Top 6 SOTA LLMs for Code, Web search, Research and More appeared first on Analytics Vidhya.
The programme includes the joint development of Managed LargeLanguageModel Services with service partners, leveraging the company’s generative AI capabilities. Japan: Information security firm Securai will localise Alibaba Cloud’s Zstack service for the Japanese market.
In recent years, the AI field has been captivated by the success of largelanguagemodels (LLMs). Initially designed for natural language processing, these models have evolved into powerful reasoning tools capable of tackling complex problems with human-like step-by-step thought process.
A new study from the AI Disclosures Project has raised questions about the data OpenAI uses to train its largelanguagemodels (LLMs). The research indicates the GPT-4o model from OpenAI demonstrates a “strong recognition” of paywalled and copyrighted data from O’Reilly Media books.
Retrieval-Augmented Generation is a technique that enhances the capabilities of largelanguagemodels by integrating information retrieval processes into their operation. Corrective RAG (CRAG) is an advanced strategy within the […] The post Corrective RAG (CRAG) in Action appeared first on Analytics Vidhya.
Largelanguagemodels struggle to process and reason over lengthy, complex texts without losing essential context. Traditional models often suffer from context loss, inefficient handling of long-range dependencies, and difficulties aligning with human preferences, affecting the accuracy and efficiency of their responses.
Largelanguagemodels (LLMs) have evolved significantly. Rather than merely predicting the next word in a sequence, these models can now perform structured reasoning, making them more effective at handling complex tasks. Understanding Simulated Thinking Humans naturally analyze different options before making decisions.
Web scraping has long been a vital technique for extracting information from the internet, enabling developers to gather insights from various domains. With the integration of LargeLanguageModels (LLMs) like ChatGroq, web scraping becomes even more powerful, offering enhanced flexibility and precision.
Retrieval Augmented Generation systems, better known as RAG systems have become the de-facto standard to build Customized Intelligent AI Assistants answering questions on custom enterprise data without the hassles of expensive fine-tuning of LargeLanguageModels (LLMs).
This nomenclature perfectly describes the dual capabilities of Manus to think (process complex information and make decisions) and act (execute tasks and generate results). For thinking, Manus relies on largelanguagemodels (LLMs), and for action, it integrates LLMs with traditional automation tools.
While largelanguagemodels (LLMs) have advanced at an incredible pace, the challenge of proving their accuracy has remained unsolved. The company has released Citations , a new API feature for its Claude models that changes how the AI systems verify their responses.
LargeLanguageModels (LLMs) have advanced significantly, but a key limitation remains their inability to process long-context sequences effectively. While models like GPT-4o and LLaMA3.1 support context windows up to 128K tokens, maintaining high performance at extended lengths is challenging.
We refer to these as largelanguagemodels. In the AI community, we call this ‘hallucination’ essentially, the system fabricates information. The problem is, once a hallucination enters the data pool, it can be repeated and reinforced by the model. How does it do that? But there are downsides.
While no AI today is definitively conscious, some researchers believe that advanced neural networks , neuromorphic computing , deep reinforcement learning (DRL), and largelanguagemodels (LLMs) could lead to AI systems that at least simulate self-awareness.
Synthetic data is information that is generated by AI. When prompted, it produces a second set that closely mirrors the first but contains no genuine information. However, fake information is more commonly used for supplementation. Generative models pretrained largelanguagemodels in particular are especially vulnerable.
Prior research has explored strategies to integrate LLMs into feature selection, including fine-tuning models on task descriptions and feature names, prompting-based selection methods, and direct filtering based on test scores. A built-in validation step ensures reliability, mitigating potential LLM inaccuracies.
Now, for this weeks issue, we have a very interesting article on information theory, exploring self-information, entropy, cross-entropy, and KL divergence these concepts bridge probability theory with real-world applications. Ill attend many discussions and am excited to meet some of you there. Our must-read articles 1.
Companies must validate and secure the underlying largelanguagemodels (LLMs) to prevent malicious actors from exploiting these technologies. Enhanced observability and monitoring of model behaviours, along with a focus on data lineage can help identify when LLMs have been compromised.
Machines are demonstrating remarkable capabilities as Artificial Intelligence (AI) advances, particularly with LargeLanguageModels (LLMs). At the leading edge of Natural Language Processing (NLP) , models like GPT-4 are trained on vast datasets. They understand and generate language with high accuracy.
One of the most frustrating things about using a largelanguagemodel is dealing with its tendency to confabulate information , hallucinating answers that are not supported by its training data.
Successful businesses use data to stay agile, which allows them to make intelligent and informed decisions regarding resources and efficiency. Leaders now have access to more data than ever before to inform their decisions. To truly harness the power of AI, companies need to move beyond merely touting AI as a buzzword.
This method has been celebrated for helping largelanguagemodels (LLMs) stay factual and reduce hallucinations by grounding their responses in real data. Intuitively, one might think that the more documents an AI retrieves, the better informed its answer will be. Source: Levy et al. Why is this such a surprise?
Instead of relying solely on labelled examples, zero-shot models use auxiliary information, such as semantic attributes or contextual relationships, to generalize across tasks. It achieves this through an iterative two-step process powered by two key components: The Generator : A LargeLanguageModel (LLM) , such as LLaMA-3.1-8B,
As their name warns us, largelanguagemodels offer to take care of language for us. Thought and language aren't one and the same, but the line separating them is blurry. In any case, it's an awful lot to be surrendering to tools that are infamously prone to making up information and lying.
As LargeLanguageModels (LLMs) continue to advance quickly, one of their most sight after applications is in RAG systems. Retrieval-Augmented Generation, or RAG connects these models to external information sources, thereby increasing their usability.
LinkedIn Photo) Perplexity , an OpenAI rival valued at $9 billion, acquired Carbon , a Seattle startup that helps companies connect external data sources to their largelanguagemodels. Carbon CEO Derek Tu. ” Carbon raised a $1.3 million seed round in 2023. . ” Carbon raised a $1.3 million seed round in 2023.
Amazon has introduced Nova Act, an advanced AI model engineered for smarter agents that can execute tasks within web browsers. While largelanguagemodels popularised the concept of agents as tools that answer queries or retrieve information via methods such as Retrieval-Augmented Generation (RAG), Amazon envisions something more robust.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content