This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In recent years, generativeAI has surged in popularity, transforming fields like text generation, image creation, and code development. Learning generativeAI is crucial for staying competitive and leveraging the technology’s potential to innovate and improve efficiency.
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generativeAI models for inference. In our tests, we’ve seen substantial improvements in scaling times for generativeAI model endpoints across various frameworks.
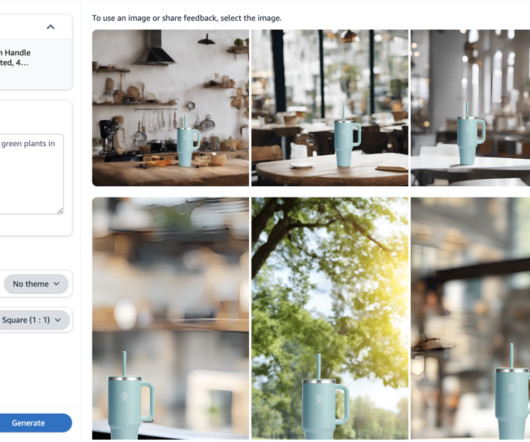
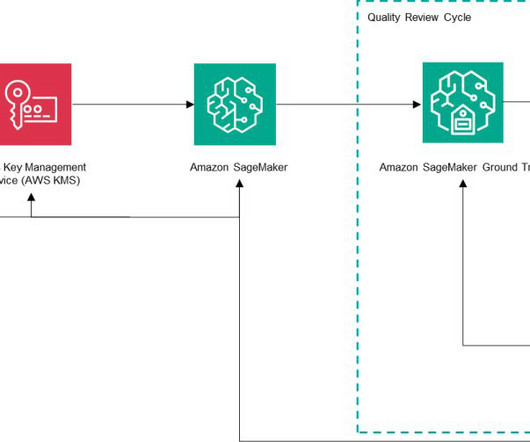
To help advertisers more seamlessly address this challenge, Amazon Ads rolled out an image generation capability that quickly and easily develops lifestyle imagery, which helps advertisers bring their brand stories to life. Here, Amazon SageMaker Ground Truth allowed MLengineers to easily build the human-in-the-loop workflow (step v).
In recent years, generativeAI has surged in popularity, transforming fields like text generation, image creation, and code development. Learning generativeAI is crucial for staying competitive and leveraging the technology’s potential to innovate and improve efficiency.
Top 5 GenerativeAI Integration Companies to Drive Customer Support in 2023 If you’ve been following the buzz around ChatGPT, OpenAI, and generativeAI, it’s likely that you’re interested in finding the best GenerativeAI integration provider for your business.
The integration of generativeAI into Customer Experience Management (CXM) is heralding a new era of digital transformation. Key Drivers and Deployment Areas One of the report's key insights is the identification of major drivers for generativeAI adoption in CXM.
Building a deployment pipeline for generative artificial intelligence (AI) applications at scale is a formidable challenge because of the complexities and unique requirements of these systems. GenerativeAI models are constantly evolving, with new versions and updates released frequently.
How to use ML to automate the refining process into a cyclical ML process. Initiate updates and optimization—Here, MLengineers will begin “retraining” the ML model method by updating how the decision process comes to the final decision, aiming to get closer to the ideal outcome.
Their skilled workforce and streamlined workflows allowed us to rapidly label the massive datasets required to train our innovative text-to-animation AI models. Ketaki Shriram, Co-Founder and CTO of Krikey AI. About Krikey AI Krikey AI Animation tools empower anyone to animate a 3D character in minutes.
At AWS re:Invent 2024, we launched a new innovation in Amazon SageMaker HyperPod on Amazon Elastic Kubernetes Service (Amazon EKS) that enables you to run generativeAIdevelopment tasks on shared accelerated compute resources efficiently and reduce costs by up to 40%. HyperPod CLI v2.0.0
As generativeAI moves from proofs of concept (POCs) to production, we’re seeing a massive shift in how businesses and consumers interact with data, information—and each other. While these layers provide different points of entry, the fundamental truth is that every generativeAI journey starts at the foundational bottom layer.
TWCo data scientists and MLengineers took advantage of automation, detailed experiment tracking, integrated training, and deployment pipelines to help scale MLOps effectively. ML model experimentation is one of the sub-components of the MLOps architecture. Anila Joshi has more than a decade of experience building AI solutions.
Machine learning (ML) engineers have traditionally focused on striking a balance between model training and deployment cost vs. performance. This is important because training ML models and then using the trained models to make predictions (inference) can be highly energy-intensive tasks.
It also helps achieve data, project, and team isolation while supporting softwaredevelopment lifecycle best practices. Furthermore, sharing model resources directly across multiple accounts helps improve ML model approval, deployment, and auditing. Siamak Nariman is a Senior Product Manager at AWS. Madhubalasri B.
Search for the embedding and text generation endpoints. Conclusion In this post, we explored how SageMaker JumpStart empowers data scientists and MLengineers to discover, access, and deploy a wide range of pre-trained FMs for inference, including Metas most advanced and capable models to date. Choose Delete again to confirm.
However, businesses can meet this challenge while providing personalized and efficient customer service with the advancements in generative artificial intelligence (generativeAI) powered by large language models (LLMs). GenerativeAI chatbots have gained notoriety for their ability to imitate human intellect.
models help you build and deploy cutting-edge generativeAI models to ignite new innovations like image reasoning and are also more accessible for on-edge applications. Search for the embedding and text generation endpoints. With a focus on responsible innovation and system-level safety, Llama 3.2 Choose Delete again to confirm.
Amazon Bedrock also provides a broad set of capabilities needed to build generativeAI applications with security, privacy, and responsible AI practices. However, deploying customized FMs to support generativeAI applications in a secure and scalable manner isn’t a trivial task.
Specialist Data Engineering at Merck, and Prabakaran Mathaiyan, Sr. MLEngineer at Tiger Analytics. The large machine learning (ML) model development lifecycle requires a scalable model release process similar to that of softwaredevelopment. This post is co-written with Jayadeep Pabbisetty, Sr.
Conclusion In this post, we explored how SageMaker JumpStart empowers data scientists and MLengineers to discover, access, and deploy a wide range of pre-trained FMs for inference, including Metas most advanced and capable models to date. On the endpoint details page, choose Delete. Choose Delete again to confirm. models today.
Amazon SageMaker provides purpose-built tools for machine learning operations (MLOps) to help automate and standardize processes across the ML lifecycle. In this post, we describe how Philips partnered with AWS to developAI ToolSuite—a scalable, secure, and compliant ML platform on SageMaker.
Fortunately, generativeAI-powered developer assistants like Amazon Q Developer have emerged to help data scientists streamline their workflows and fast-track ML projects, allowing them to save time and focus on strategic initiatives and innovation. For pricing information, see Amazon Q Developer pricing.
Fast Bria AI offers a family of high-quality visual content models. Fast in SageMaker JumpStart and AWS Marketplace, enterprises can now use advanced generativeAI capabilities to enhance their visual content creation processes. About the Authors Bar Fingerman is the Head of AI/MLEngineering at Bria.
His area of focus is generativeAI and AWS AI Accelerators. Niithiyn works closely with the GenerativeAI GTM team to enable AWS customers on multiple fronts and accelerate their adoption of generativeAI. Ziwen Ning is a softwaredevelopmentengineer at AWS.
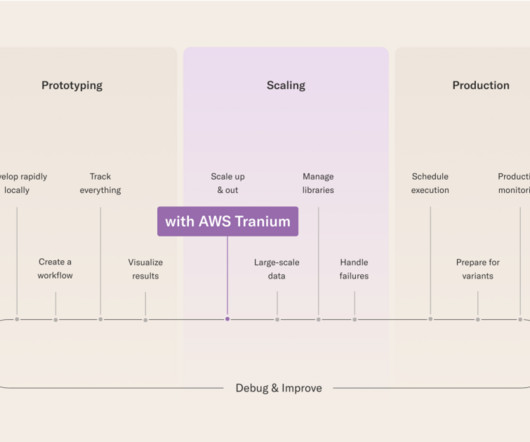
Metaflow overview Metaflow was originally developed at Netflix to enable data scientists and MLengineers to build ML/AI systems quickly and deploy them on production-grade infrastructure. How Metaflow integrates with Trainium From a Metaflow developer perspective, using Trainium is similar to other accelerators.
collection of multilingual large language models (LLMs), which includes pre-trained and instruction tuned generativeAI models in 8B, 70B, and 405B sizes, is available through Amazon SageMaker JumpStart to deploy for inference. Christopher Whitten is a softwaredeveloper on the JumpStart team.
Prior to working at Amazon Music, Siddharth was working at companies like Meta, Walmart Labs, Rakuten on E-Commerce centric ML Problems. Tarun Sharma is a SoftwareDevelopment Manager leading Amazon Music Search Relevance. Siddharth spent early part of his career working with bay area ad-tech startups.
The free virtual conference is the largest annual gathering of the data-centric AI community. The sessions at this year’s conference will focus on the following: Data development techniques: programmatic labeling, synthetic data, active learning, weak supervision, data cleaning, and augmentation.
The free virtual conference is the largest annual gathering of the data-centric AI community. The sessions at this year’s conference will focus on the following: Data development techniques: programmatic labeling, synthetic data, active learning, weak supervision, data cleaning, and augmentation.
The AI Paradigm Shift: Under the Hood of a Large Language Models Valentina Alto | Azure Specialist — Data and Artificial Intelligence | Microsoft Develop an understanding of GenerativeAI and Large Language Models, including the architecture behind them, their functioning, and how to leverage their unique conversational capabilities.
This allows MLengineers and admins to configure these environment variables so data scientists can focus on ML model building and iterate faster. About the Authors Dipankar Patro is a SoftwareDevelopmentEngineer at AWS SageMaker, innovating and building MLOps solutions to help customers adopt AI/ML solutions at scale.
Many customers are looking for guidance on how to manage security, privacy, and compliance as they developgenerativeAI applications. This post provides three guided steps to architect risk management strategies while developinggenerativeAI applications using LLMs.
Organizations of every size and across every industry are looking to use generativeAI to fundamentally transform the business landscape with reimagined customer experiences, increased employee productivity, new levels of creativity, and optimized business processes.
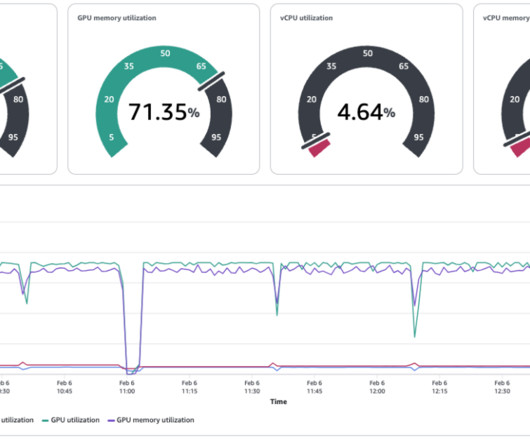
The generativeAI landscape has been rapidly evolving, with large language models (LLMs) at the forefront of this transformation. As LLMs continue to expand, AIengineers face increasing challenges in deploying and scaling these models efficiently for inference. The following table summarizes our setup.
Bio: Hamza Tahir is a softwaredeveloper turned MLengineer. Based on his learnings from deploying ML in production for predictive maintenance use-cases in his previous startup, he co-created ZenML , an open-source MLOps framework for creating production grade ML pipelines on any infrastructure stack.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content