This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
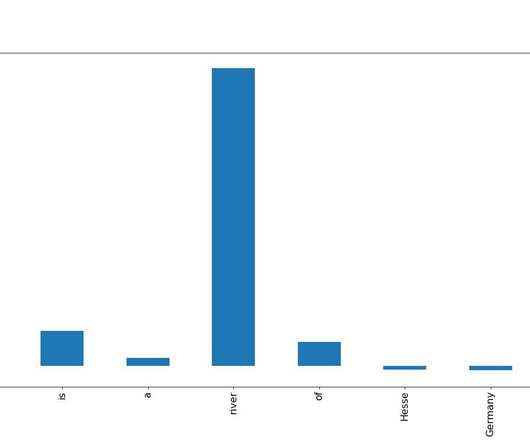
How much machine learning really is in MLEngineering? But what actually are the differences between a Data Engineer, Data Scientist, MLEngineer, Research Engineer, Research Scientist, or an Applied Scientist?! Data engineering is the foundation of all ML pipelines. It’s so confusing!
Amazon SageMaker has redesigned its Python SDK to provide a unified object-oriented interface that makes it straightforward to interact with SageMaker services. Over the past 5 years, she has worked with multiple enterprise customers to set up a secure, scalable AI/ML platform built on SageMaker.
Training Sessions Bayesian Analysis of Survey Data: Practical Modeling withPyMC Allen Downey, PhD, Principal Data Scientist at PyMCLabs Alexander Fengler, Postdoctoral Researcher at Brown University Bayesian methods offer a flexible and powerful approach to regression modeling, and PyMC is the go-to library for Bayesian inference in Python.
Core AI Skills Every Engineer ShouldMaster While its tempting to chase the newest framework or model, strong AI capability begins with foundational skills. That starts with programmingespecially in languages like Python and SQL, where most machine learning tools and AI libraries are built. Lets not forget data wrangling.
Model explainability refers to the process of relating the prediction of a machine learning (ML) model to the input feature values of an instance in humanly understandable terms. This field is often referred to as explainable artificial intelligence (XAI). In this post, we illustrate the use of Clarify for explaining NLP models.
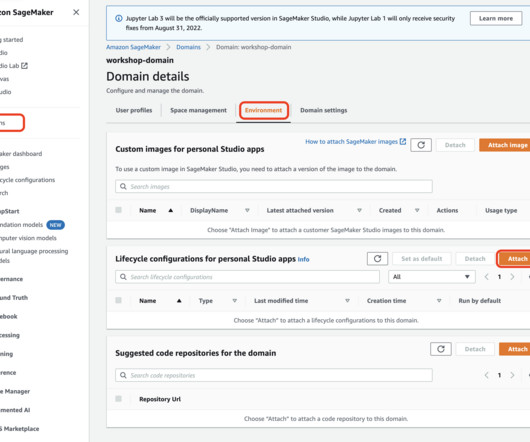
This post presents and compares options and recommended practices on how to manage Python packages and virtual environments in Amazon SageMaker Studio notebooks. Amazon SageMaker Studio is a web-based, integrated development environment (IDE) for machine learning (ML) that lets you build, train, debug, deploy, and monitor your ML models.
In this post, we explain how to automate this process. The solution described in this post is geared towards machine learning (ML) engineers and platform teams who are often responsible for managing and standardizing custom environments at scale across an organization.
How to save a trained model in Python? In this section, you will see different ways of saving machine learning (ML) as well as deep learning (DL) models. Note: The focus of this article is not to show you how you can create the best ML model but to explain how effectively you can save trained models.
How to use ML to automate the refining process into a cyclical ML process. Initiate updates and optimization—Here, MLengineers will begin “retraining” the ML model method by updating how the decision process comes to the final decision, aiming to get closer to the ideal outcome.
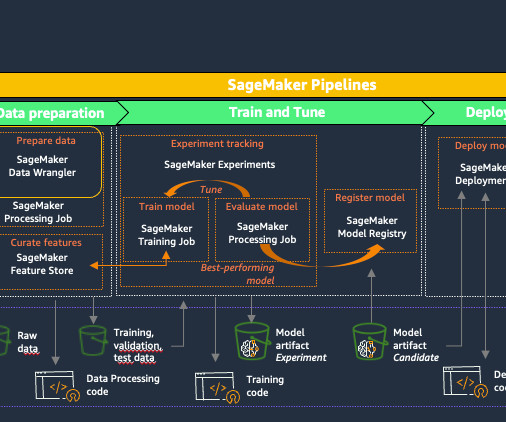
TWCo data scientists and MLengineers took advantage of automation, detailed experiment tracking, integrated training, and deployment pipelines to help scale MLOps effectively. ML model experimentation is one of the sub-components of the MLOps architecture. For this proof of concept, pipelines were set up using this SDK.
Envision yourself as an MLEngineer at one of the world’s largest companies. You make a Machine Learning (ML) pipeline that does everything, from gathering and preparing data to making predictions. This is suitable for making a variety of Python applications with other dependencies being added to it at the user’s convenience.
We’ll also discuss some of the benefits of using set union(), and we’ll see why it’s a popular tool for Python developers. We’ll also discuss some of the benefits of using set union(), and we’ll see why it’s a popular tool for Python developers.
True to its name, Explainable AI refers to the tools and methods that explain AI systems and how they arrive at a certain output. In this blog, we’ll dive into the need for AI explainability, the various methods available currently, and their applications. Why do we need Explainable AI (XAI)?
Sweetviz GitHub | Website Sweetviz is an open-source Python library that generates beautiful, high-density visualizations to kickstart EDA (Exploratory Data Analysis) with just two lines of code. Apache Superset GitHub | Website Apache Superset is a must-try project for any MLengineer, data scientist, or data analyst.
Artificial intelligence (AI) and machine learning (ML) are becoming an integral part of systems and processes, enabling decisions in real time, thereby driving top and bottom-line improvements across organizations. However, putting an ML model into production at scale is challenging and requires a set of best practices.
Although there are many potential metrics that you can use to monitor LLM performance, we explain some of the broadest ones in this post. This could be an actual classifier that can explain why the model refused the request. Refer to the Python documentation for an example. The function sends that average to CloudWatch metrics.
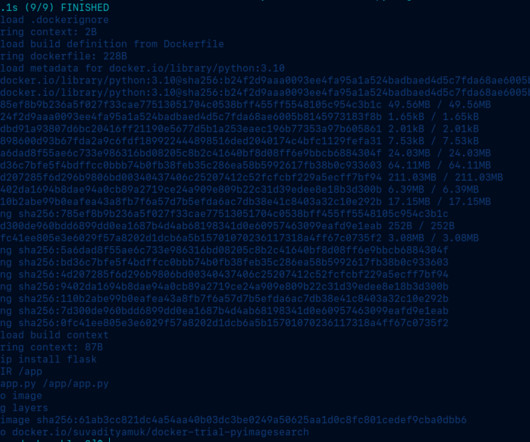
Getting Used to Docker for Machine Learning Introduction Docker is a powerful addition to any development environment, and this especially rings true for MLEngineers or enthusiasts who want to get started with experimentation without having to go through the hassle of setting up several drivers, packages, and more.
Discover Llama 4 models in SageMaker JumpStart SageMaker JumpStart provides FMs through two primary interfaces: SageMaker Studio and the Amazon SageMaker Python SDK. Alternatively, you can use the SageMaker Python SDK to programmatically access and use SageMaker JumpStart models.
Of course, I made a video giving more details about the book if you are curious: p.s. The only skill required for the book is some Python (or programming) knowledge. It starts from explaining what an LLM is in simpler terms, and takes you through a brief history of time in NLP to the most current state of technology in AI.
But who exactly is an LLM developer, and how are they different from software developers and MLengineers? If you are skilled in Python or computer vision, diffusion models, or GANS, you might be a great fit. Well, briefly, software developers focus on building traditional applications using explicit code. Meme of the week!
All ML projects are software projects. If you peek under the hood of an ML-powered application, these days you will often find a repository of Python code. Arguably, high-level programming languages like Python are the most expressive and efficient ways that humankind has conceived to formally define complex processes.
Amazon SageMaker provides purpose-built tools for ML teams to automate and standardize processes across the ML lifecycle. You can use SageMaker Data Wrangler to simplify and streamline dataset preprocessing and feature engineering by either using built-in, no-code transformations or customizing with your own Python scripts.
We use DSPy (Declarative Self-improving Python) to demonstrate the workflow of Retrieval Augmented Generation (RAG) optimization, LLM fine-tuning and evaluation, and human preference alignment for performance improvement. Clone the GitHub repository and follow the steps explained in the README. Set up a SageMaker notebook instance.
Knowledge and skills in the organization Evaluate the level of expertise and experience of your ML team and choose a tool that matches their skill set and learning curve. For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc.,
Set up the SDK for Python (Boto3). medium instance with the Python 3 (Data Science) kernel. About the Authors Sanjeeb Panda is a Data and MLengineer at Amazon. Outside of his work as a Data and MLengineer at Amazon, Sanjeeb Panda is an avid foodie and music enthusiast.
It can also be done at scale, as explained in Operationalize LLM Evaluation at Scale using Amazon SageMaker Clarify and MLOps services. Fine-tuning an LLM can be a complex workflow for data scientists and machine learning (ML) engineers to operationalize. You can then select the best model based on the evaluation results.
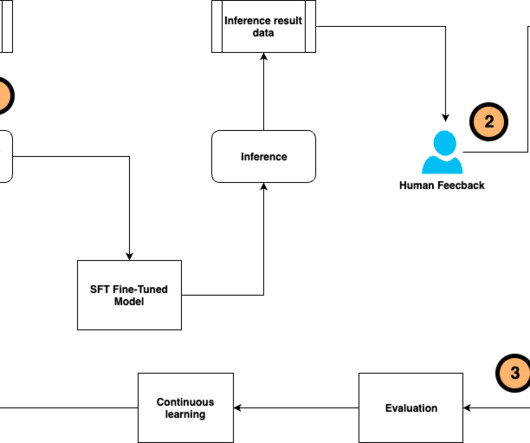
Explainability: Tracing provides insights into the agents decision-making process, helping you to understand the reasoning behind its actions. Imagine a large team of data scientists and MLengineers working on an agentic platform, as shown in the following image.
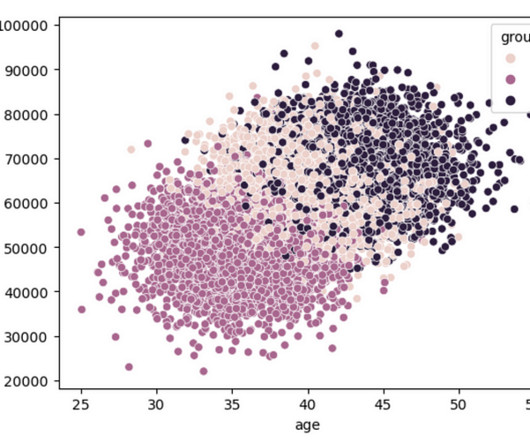
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Key programming languages include Python and R, while mathematical concepts like linear algebra and calculus are crucial for model optimisation. during the forecast period.
They needed a cloud platform and a strategic partner with proven expertise in delivering production-ready AI/ML solutions, to quickly bring EarthSnap to the market. We initiated a series of enhancements to deliver managed MLOps platform and augment MLengineering. Endpoints had to be deployed manually as well.
As everything is explained from scratch but extensively I hope you will find it interesting whether you are NLP Expert or just want to know what all the fuss is about. We will discuss how models such as ChatGPT will affect the work of software engineers and MLengineers. and we will also explain how GPT can create jobs.
Key points of this talk are: In this talk, we will focus on: The dangers of using post-hoc explainability methods as tools for decision making, and how traditional ML isn’t suited in situations where want to perform interventions on the system. In particular you will cover proper types, chaining, aggregation, debugging.
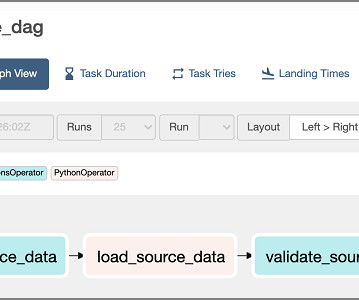
This post, part of the Governing the ML lifecycle at scale series ( Part 1 , Part 2 , Part 3 ), explains how to set up and govern a multi-account ML platform that addresses these challenges. MLengineers Develop model deployment pipelines and control the model deployment processes.
TL;DR This series explain how to implement intermediate MLOps with simple python code, without introducing MLOps frameworks (MLflow, DVC …). As an MLengineer you’re in charge of some code/model. Python has different flavors, and some freedom about the location of scripts and components. Why is this a requirement?
In this post, we discuss Bria’s family of models, explain the Amazon SageMaker platform, and walk through how to discover, deploy, and run inference on a Bria 2.3 ML practitioners can deploy FMs to dedicated SageMaker instances from a network-isolated environment and customize models using SageMaker for model training and deployment.
And that’s what we’re going to focus on in this article, which is the second in my series on Software Patterns for Data Science & MLEngineering. There, you can use infographics, custom visualizations, and broader ways to explain your ideas. Data on its own is not sufficient for a cohesive story. For one, Git diffs within.py
Throughout this exercise, you use Amazon Q Developer in SageMaker Studio for various stages of the development lifecycle and experience firsthand how this natural language assistant can help even the most experienced data scientists or MLengineers streamline the development process and accelerate time-to-value.
Can AI help explain the universe? Last week, computer scientist and physicist Stephen Wolfram published a long and detailed essay attempting to explain the potential and limits of AI in discovering new science. Is AI going to discover everything? What are the limits of AI when it comes to science?
Since a lot of developers are working on Python we continued to trainStarCoder for about 35B tokens (~3% of full training) on the Python subset which lead to a significant performance boost. Could you explain the data curation and training process required for building such a model? What are the best benchmarks in the market?
This collaboration ensures that your MLOps platform can adapt to evolving business needs and accelerates the adoption of ML across teams. Machine Learning Engineer with AWS Professional Services. She is passionate about developing, deploying, and explaining AI/ ML solutions across various domains.
We will be writing code in Python, but DataRobot Notebooks also supports R if that’s your preferred language. The built-in notebook environments come with the respective DataRobot client (Python or R) preinstalled, and DataRobot handles authenticating the client on the user’s behalf. Model Explainability for Responsible and Trusted AI.
ML focuses on algorithms like decision trees, neural networks, and support vector machines for pattern recognition. Skills Proficiency in programming languages (Python, R), statistical analysis, and domain expertise are crucial. AI Engineer, Machine Learning Engineer, and Robotics Engineer are prominent roles in AI.
Comet Comet is a machine learning platform built to help data scientists and MLengineers track, compare, and optimize machine learning experiments. We can install this library in the same way as other Python libraries, using pip . We're committed to supporting and inspiring developers and engineers from all walks of life.
It also integrates with Machine Learning and Operation (MLOps) workflows in Amazon SageMaker to automate and scale the ML lifecycle. He leads a team of scientists working on Responsible AI and his research interests are Algorithmic Fairness and Explainable Machine Learning. What is FMEval? How can you get started?
Takeaways include: The dangers of using post-hoc explainability methods as tools for decision-making, and where traditional ML falls short. You will also become familiar with the concept of LLM as a reasoning engine that can power your applications, paving the way to a new landscape of software development in the era of Generative AI.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content