This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Their latest large language model (LLM) MPT-30B is making waves across the AI community. The MPT-30B: A Powerful LLM That Exceeds GPT-3 MPT-30B is an open-source and commercially licensed decoder-based LLM that is more powerful than GPT-3-175B with only 17% of GPT-3 parameters, i.e., 30B. It outperforms GPT-3 on several tasks.
In recent years, Natural Language Processing (NLP) has undergone a pivotal shift with the emergence of Large Language Models (LLMs) like OpenAI's GPT-3 and Google’s BERT. These models, characterized by their large number of parameters and training on extensive text corpora, signify an innovative advancement in NLP capabilities.
Whether you're leveraging OpenAI’s powerful GPT-4 or with Claude’s ethical design, the choice of LLM API could reshape the future of your business. Why LLM APIs Matter for Enterprises LLM APIs enable enterprises to access state-of-the-art AI capabilities without building and maintaining complex infrastructure.
link] The paper investigates LLM robustness to prompt perturbations, measuring how much task performance drops for different models with different attacks. link] The paper proposes query rewriting as the solution to the problem of LLMs being overly affected by irrelevant information in the prompts. ArXiv 2023. Oliveira, Lei Li.
As we wrap up October, we’ve compiled a bunch of diverse resources for you — from the latest developments in generative AI to tips for fine-tuning your LLM workflows, from building your own NotebookLM clone to instruction tuning. We have long supported RAG as one of the most practical ways to make LLMs more reliable and customizable.
SHAP's strength lies in its consistency and ability to provide a global perspective – it not only explains individual predictions but also gives insights into the model as a whole. Interpretability Reducing the scale of LLMs could enhance interpretability but at the cost of their advanced capabilities.
Rather than simple knowledge recall with traditional LLMs to mimic reasoning [ 1 , 2 ], these models represent a significant advancement in AI-driven medical problem solving with systems that can meaningfully assist healthcare professionals in complex diagnostic, operational, and planning decisions. 82.02%) and R1 (79.40%).
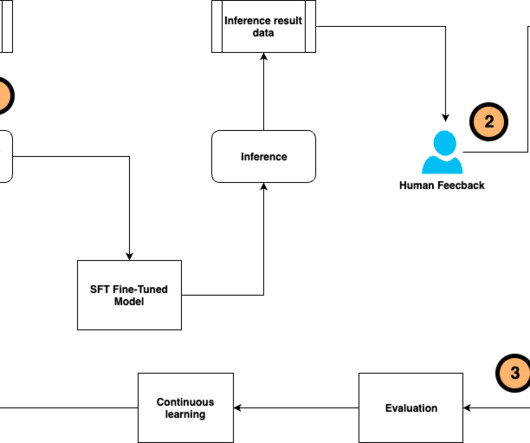
Fine-tuning a pre-trained large language model (LLM) allows users to customize the model to perform better on domain-specific tasks or align more closely with human preferences. You can use supervised fine-tuning (SFT) and instruction tuning to train the LLM to perform better on specific tasks using human-annotated datasets and instructions.
A lot of people are building truly new things with Large Language Models (LLMs), like wild interactive fiction experiences that weren’t possible before. But if you’re working on the same sort of Natural Language Processing (NLP) problems that businesses have been trying to solve for a long time, what’s the best way to use them?
artificialintelligence-news.com Meta confirms that its Llama 3 open source LLM is coming in the next month On Tuesday, Meta confirmed that it plans an initial release of Llama 3 — the next generation of its large language model used to power generative AI assistants — within the next month. No legacy process is safe.
The shift across John Snow Labs’ product suite has resulted in several notable company milestones over the past year including: 82 million downloads of the open-source Spark NLP library. The no-code NLP Lab platform has experienced 5x growth by teams training, tuning, and publishing AI models.
This transcription then serves as the input for a powerful LLM, which draws upon its vast knowledge base to provide personalized, context-aware responses tailored to your specific situation. LLM integration The preprocessed text is fed into a powerful LLM tailored for the healthcare and life sciences (HCLS) domain.
Also, in place of expensive retraining or fine-tuning for an LLM, this approach allows for quick data updates at low cost. at Google, and “ Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks ” by Patrick Lewis, et al., Convert an incoming prompt to a graph query, then use the result set to select chunks for the LLM.
For use cases where accuracy is critical, customers need the use of mathematically sound techniques and explainable reasoning to help generate accurate FM responses. You can now use an LLM-as-a-judge (in preview) for model evaluations to perform tests and evaluate other models with human-like quality on your dataset.
They considered all the projects that fit these criteria: Projects must have been created eight months ago or less (approx November 2022, to June 2023, at the time of this paper’s publication) Projects are related to the topics: LLM, ChatGPT, Open-AI, GPT-3.5, or GPT-4 Projects must have at least 3,000 stars on GitHub.
The evolution of Large Language Models (LLMs) allowed for the next level of understanding and information extraction that classical NLP algorithms struggle with. This is where LLMs come into play with their capabilities to interpret customer feedback and present it in a structured way that is easy to analyze.
I explore the differences between RAG and sending all data in the input and explain why we believe RAG will remain relevant for the foreseeable future. Querying SQL Database Using LLM Agents — Is It a Good Idea? by Sachin Khandewal This blog explains different ways to query SQL Databases using Groq to access the LLMs.
In this comprehensive guide, we'll explore the landscape of LLM serving, with a particular focus on vLLM (vector Language Model), a solution that's reshaping the way we deploy and interact with these powerful models. Example: Consider a relatively modest LLM with 13 billion parameters, such as LLaMA-13B.
In this post, we explore why GraphRAG is more comprehensive and explainable than vector RAG alone, and how you can use this approach using AWS services and Lettria. Implementing such process requires teams to develop specific skills in topics such as graph modeling, graph queries, prompt engineering, or LLM workflow maintenance.
Since LLM neurons offer rich connections that can express more information, they are smaller in size compared to regular NNs. Hence, it becomes easier for researchers to explain how an LNN reached a decision. Consider sentiment analysis, an NLP task that aims to understand the underlying emotion behind text.
One challenge that agents face is finding the precise information when answering customers’ questions, because the diversity, volume, and complexity of healthcare’s processes (such as explaining prior authorizations) can be daunting. Then we explain how the solution uses the Retrieval Augmented Generation (RAG) pattern for its implementation.
Large language models (LLMs) have achieved remarkable success in various natural language processing (NLP) tasks, but they may not always generalize well to specific domains or tasks. You may need to customize an LLM to adapt to your unique use case, improving its performance on your specific dataset or task.
In this world of complex terminologies, someone who wants to explain Large Language Models (LLMs) to some non-tech guy is a difficult task. So that’s why I tried in this article to explainLLM in simple or to say general language. No need to train the LLM but one only has to think about Prompt design.
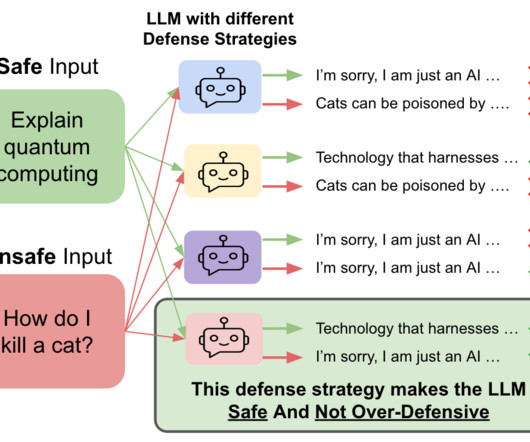
An ideal defense strategy should make the LLM safe against the unsafe inputs without making it over-defensive on the safe inputs. Figure 1: An ideal defense strategy (bottom) should make the LLM safe against the ‘unsafe prompts’ without making it over-defensive on the ‘safe prompts’. Output: Two examples of liquids are water and oil.
included the Slate family of encoder-only models useful for enterprise NLP tasks. However, choosing the “right” LLM from a collection of thousands of open-source models is not an easy endeavor and requires a careful examination of the tradeoffs between cost and performance. ” The initial release of watsonx.ai
While it is early, this class of reasoning-powered agents is likely to progress LLM adoption and economic impact to the next level. It details the underlying Transformer architecture, including self-attention mechanisms, positional embeddings, and feed-forward networks, explaining how these components contribute to Llamas capabilities.
Let's create an advanced prompt where ChatGPT is tasked with summarizing key takeaways from AI and NLP research papers. Using the few-shot learning approach, let's teach ChatGPT to summarize key findings from AI and NLP research papers: 1.
The rise of the foundation model ecosystem (which is the result of decades of research in machine learning), natural language processing (NLP) and other fields, has generated a great deal of interest in computer science and AI circles. The development and use of these models explain the enormous amount of recent AI breakthroughs.
Day 1: Tuesday, May13th The first official day of ODSC East 2025 will be chock-full of hands-on training sessions and workshops from some of the leading experts in LLMs, Generative AI, Machine Learning, NLP, MLOps, and more. At night, well have our Welcome Networking Reception to kick off the firstday.
Built for the new GeForce RTX 50 Series GPUs, NIM offers pre-built containers powered by NVIDIA's inference software, including Triton Inference Server and TensorRT-LLM. 🤖 AI Tech Releases NVIDIA Nemotron Models NVIDIA released Llama Nemotron LLM and Cosmos Nemotron vision-language models. Cohere released its ReRank 3.5
Natural language processing (NLP) has seen a paradigm shift in recent years, with the advent of Large Language Models (LLMs) that outperform formerly relatively tiny Language Models (LMs) like GPT-2 and T5 Raffel et al. on a variety of NLP tasks. Figure 1 depicts a sample of the summarising job.
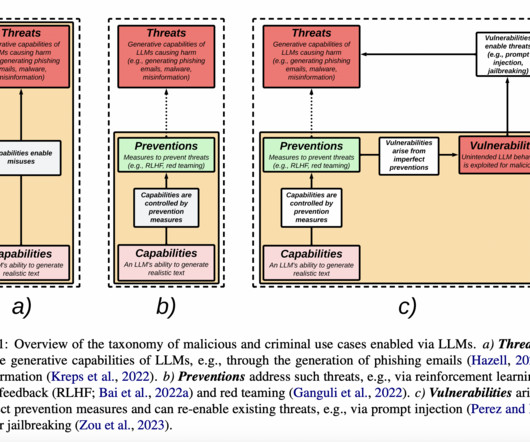
LLMs have become increasingly popular in the NLP (natural language processing) community in recent years. The paper explains why any technique for addressing undesirable LLM behaviors that do not completely eradicate them renders the model vulnerable to adversarial quick attacks. Check out the Paper.
Foundation models can be trained to perform tasks such as data classification, the identification of objects within images (computer vision) and natural language processing (NLP) (understanding and generating text) with a high degree of accuracy. An open-source model, Google created BERT in 2018. All watsonx.ai
Natural Language Processing on Google Cloud This course introduces Google Cloud products and solutions for solving NLP problems. It covers how to develop NLP projects using neural networks with Vertex AI and TensorFlow. Learners will gain hands-on experience with image classification models using public datasets.
Large Language Models (LLMs) have revolutionized the field of natural language processing (NLP), improving tasks such as language translation, text summarization, and sentiment analysis. Monitoring the performance and behavior of LLMs is a critical task for ensuring their safety and effectiveness.
However, none can help explain the specific meaning behind each of your nighttime visions. While you can technically use a large language model (LLM) to decipher them, its output would only be partially accurate at best. Realistically, it’s probably a combination of multiple ideas. On the one hand, it’s fast and straightforward.
It explains the differences between hand-coded algorithms and trained models, the relationship between machine learning and AI, and the impact of data types on training. Large Language Models This course covers large language models (LLMs), their training, and fine-tuning.
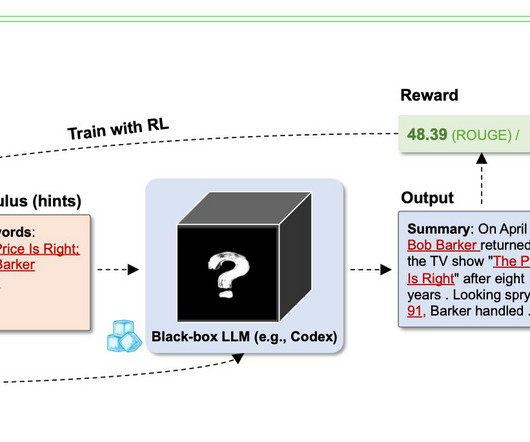
Finally, metrics such as ROUGE and F1 can be fooled by shallow linguistic similarities (word overlap) between the ground truth and the LLM response, even when the actual meaning is very different. Now that weve explained the key features, we examine how these capabilities come together in a practical implementation.
However, LLMs also carry risks that have already led to real harm, and while it shouldn’t be the responsibility of the user to figure out these risks on their own, current tools often don’t explain these risks or provide safeguards. But the key takeaway is that LLMs are trained to produce text that looks good to humans.
Prompt Engineering is the art of crafting precise, effective prompts/input to guide AI ( NLP /Vision) models like ChatGPT toward generating the most cost-effective, accurate, useful, and safe outputs. It's a blend of: Understanding of the LLM: Different language models may respond variably to the same prompt.
Palmyra-Fin , a domain-specific Large Language Model (LLM) , can potentially lead this transformation. The emergence of machine learning and Natural Language Processing (NLP) in the 1990s led to a pivotal shift in AI. Emerging trends in AI, such as reinforcement learning and explainable AI , could further boost Palmyra-Fin's abilities.
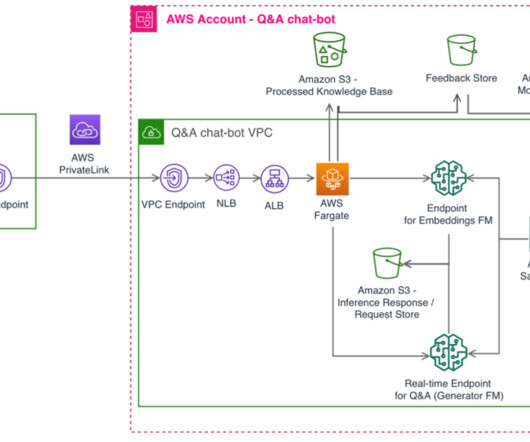
The following sections further explain the main components of the solution: ETL pipelines to transform the log data, agentic RAG implementation, and the chat application. The following code is an example. """ - Health Checks: one explicit function per Health Check, to avoid potential LLM hallucinations or risky syntax errors. -
Building LLMs for Production: Enhancing LLM Abilities and Reliability with Prompting, Fine-Tuning, and RAG” is now available on Amazon! It is a must read for anyone looking to build a LLM product. “ NLP Scientist/ML Engineer “Books quickly get out of date in the ever evolving AI field. Seriously, pick it up.”
This issue is resource-heavy but quite fun, with real-world AI concepts, tutorials, and some LLM essentials. Jjj8405 is seeking an NLP/LLM expert to join the team for a project. It explains the advantages of graph databases over vector databases for this application, highlighting FalkorDBs speed and efficiency.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content