This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This involves doubling down on access controls and privilege creep, and keeping data away from publicly-hosted LLMs. ” Boost transparency and explainability Another serious obstacle to AI adoption is a lack of trust in its results. The best way to combat this fear is to increase explainability and transparency.
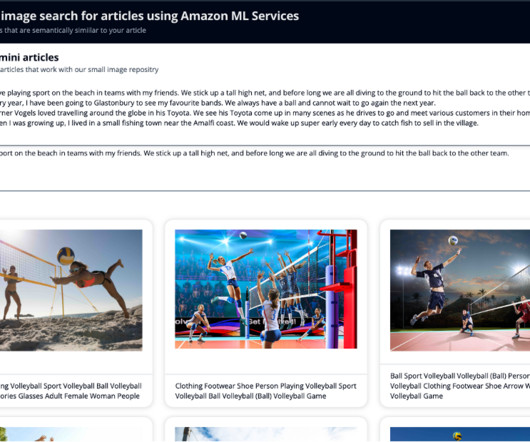
This is where LLMs come into play with their capabilities to interpret customer feedback and present it in a structured way that is easy to analyze. This article will focus on LLM capabilities to extract meaningful metadata from product reviews, specifically using OpenAI API. Data We decided to use the Amazon reviews dataset.
With the release of DeepSeek, a highly sophisticated large language model (LLM) with controversial origins, the industry is currently gripped by two questions: Is DeepSeek real or just smoke and mirrors? Why AI-native infrastructure is mission-critical Each LLM excels at different tasks.
That said, AgentOps (the tool) offers developers insight into agent workflows with features like session replays, LLM cost tracking, and compliance monitoring. Observability and Tracing AgentOps captures detailed execution logs: Traces: Record every step in the agent's workflow, from LLM calls to tool usage. What is AgentOps?
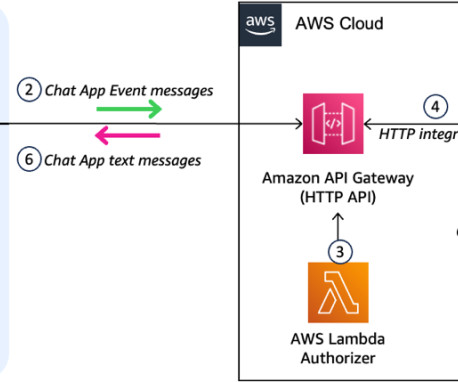
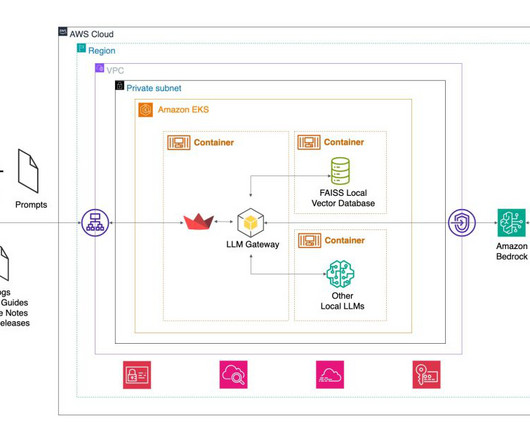
Agent architecture The following diagram illustrates the serverless agent architecture with standard authorization and real-time interaction, and an LLM agent layer using Amazon Bedrock Agents for multi-knowledge base and backend orchestration using API or Python executors. Domain-scoped agents enable code reuse across multiple agents.
The platform automatically analyzes metadata to locate and label structured data without moving or altering it, adding semantic meaning and aligning definitions to ensure clarity and transparency. Can you explain the core concept and what motivated you to tackle this specific challenge in AI and data analytics?
I don’t need any other information for now We get the following response from the LLM: Based on the image provided, the class of this document appears to be an ID card or identification document. The LLM has filled in the table based on the graph and its own knowledge about the capital of each country.
Deep learning (DL), the most advanced form of AI, is the only technology capable of preventing and explaining known and unknown zero-day threats. Can you explain the inspiration behind DIANNA and its key functionalities? Not all AI is equal. Deep Instinct is the only provider on the market that can predict and prevent zero-day attacks.
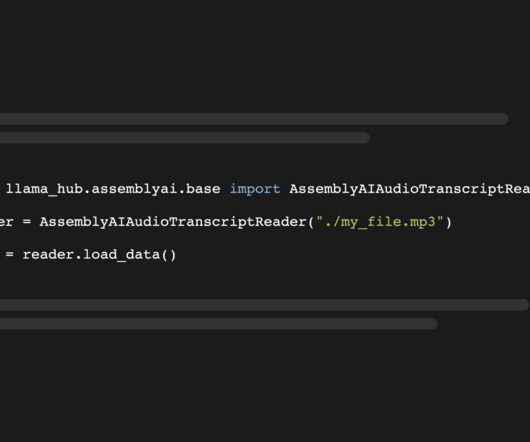
For this, we create a small demo application that lets you load audio data and apply an LLM that can answer questions about your spoken data. The metadata contains the full JSON response of our API with more meta information: print(docs[0].metadata) page_content) # Runner's knee. Runner's knee is a condition.
For this, we create a small demo application with an LLM-powered query engine that lets you load audio data and ask questions about your data. The metadata contains the full JSON response of our API with more meta information: print(docs[0].metadata) Getting Started Create a new virtual environment: # Mac/Linux: python3 -m venv venv.
For use cases where accuracy is critical, customers need the use of mathematically sound techniques and explainable reasoning to help generate accurate FM responses. You can now use an LLM-as-a-judge (in preview) for model evaluations to perform tests and evaluate other models with human-like quality on your dataset.
Tracing provides a way to record the inputs, outputs, and metadata associated with each intermediate step of a request, enabling you to easily pinpoint the source of bugs and unexpected behaviors. Explainability: Tracing provides insights into the agents decision-making process, helping you to understand the reasoning behind its actions.
the router would direct the query to a text-based RAG that retrieves relevant documents and uses an LLM to generate an answer based on textual information. For instance, analyzing large tables might require prompting the LLM to generate Python or SQL and running it, rather than passing the tabular data to the LLM.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. The development and use of these models explain the enormous amount of recent AI breakthroughs. AI governance refers to the practice of directing, managing and monitoring an organization’s AI activities.
This transcription then serves as the input for a powerful LLM, which draws upon its vast knowledge base to provide personalized, context-aware responses tailored to your specific situation. LLM integration The preprocessed text is fed into a powerful LLM tailored for the healthcare and life sciences (HCLS) domain.
Large language models (LLMs) have achieved remarkable success in various natural language processing (NLP) tasks, but they may not always generalize well to specific domains or tasks. You may need to customize an LLM to adapt to your unique use case, improving its performance on your specific dataset or task.
While single models are suitable in some scenarios, acting as co-pilots, agentic architectures open the door for LLMs to become active components of business process automation. As such, enterprises should consider leveraging LLM-based multi-agent (LLM-MA) systems to streamline complex business processes and improve ROI.
Thats a problem, especially given that an LLM cant be fired or held accountable. It is important to do it right, with all required metadata about the information structure and attributes. The general idea is to ask the model to think in steps and explain/validate its conclusions and intermediate steps, so it can catch its errors.
Technologies and Tools Used To build this Resume Chatbot, I leveraged the following technologies and libraries: OpenAI API: Used to power the chatbot with a state-of-the-art LLM. LangChain: This framework was instrumental in interacting with the LLM and integrating various tools to enhance the chatbots functionality.
Thats a problem, especially given that an LLM cant be fired or held accountable. It is important to do it right, with all required metadata about the information structure and attributes. The general idea is to ask the model to think in steps and explain/validate its conclusions and intermediate steps, so it can catch its errors.
Thats a problem, especially given that an LLM cant be fired or held accountable. It is important to do it right, with all required metadata about the information structure and attributes. The general idea is to ask the model to think in steps and explain/validate its conclusions and intermediate steps, so it can catch its errors.
Thats a problem, especially given that an LLM cant be fired or held accountable. It is important to do it right, with all required metadata about the information structure and attributes. The general idea is to ask the model to think in steps and explain/validate its conclusions and intermediate steps, so it can catch its errors.
To create AI assistants that are capable of having discussions grounded in specialized enterprise knowledge, we need to connect these powerful but generic LLMs to internal knowledge bases of documents. The search precision can also be improved with metadata filtering.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Third, despite the larger adoption of centralized analytics solutions like data lakes and warehouses, complexity rises with different table names and other metadata that is required to create the SQL for the desired sources.
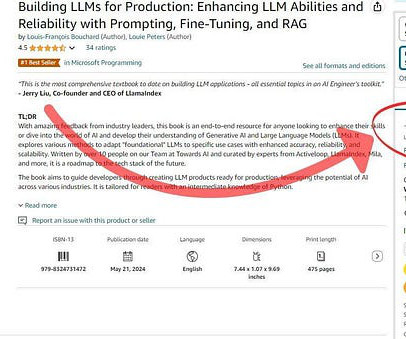
Take advantage of the current deal offered by Amazon (depending on location) to get our recent book, “Building LLMs for Production,” with 30% off right now! Featured Community post from the Discord Arwmoffat just released Manifest, a tool that lets you write a Python function and have an LLM execute it. Our must-read articles 1.
This request contains the user’s message and relevant metadata. The Lambda function interacts with Amazon Bedrock through its runtime APIs, using either the RetrieveAndGenerate API that connects to a knowledge base, or the Converse API to chat directly with an LLM available on Amazon Bedrock.
link] The paper investigates LLM robustness to prompt perturbations, measuring how much task performance drops for different models with different attacks. link] The paper proposes query rewriting as the solution to the problem of LLMs being overly affected by irrelevant information in the prompts. ArXiv 2023. Oliveira, Lei Li.
Participants learn to build metadata for documents containing text and images, retrieve relevant text chunks, and print citations using Multimodal RAG with Gemini. Introduction to Generative AI This introductory microlearning course explains Generative AI, its applications, and its differences from traditional machine learning.
Our agent-based solution offers two key strengths: Automated scalable schema discovery The schema and table metadata can be dynamically updated to generate SQL when the initial attempt to execute the query fails. In the next section, we explain how Lambda processes the errors and passes them to the agent.
The new SageMaker JumpStart Foundation Hub allows you to easily deploy large language models (LLM) and integrate them with your applications. First, you extract label and celebrity metadata from the images, using Amazon Rekognition. You then generate an embedding of the metadata using a LLM.
It allows users to explain and generate code, fix errors, summarize content, and even generate entire notebooks from natural language prompts. The tool connects Jupyter with large language models (LLMs) from various providers, including AI21, Anthropic, AWS, Cohere, and OpenAI, supported by LangChain.
In order to update this knowledge, we must retrain the LLM, which takes a lot of time and money. Fortunately, we can also use source knowledge to inform our LLMs. Source knowledge is information fed into the LLM through an input prompt. Deploying an LLM In this post, we discuss two approaches to deploying an LLM.
Can you explain how HeavyIQ leverages natural language processing to facilitate data exploration and visualization? What measures are in place to prevent metadata leakage when using HeavyIQ? This includes not only data but also several kinds of metadata. Lastly, the language models themselves generate further metadata.
In this post, we use a Hugging Face BERT-Large model pre-training workload as a simple example to explain how to useTrn1 UltraClusters. results.json captures the metadata of this particular job run, such as the model’s configuration, batch size, total steps, gradient accumulation steps, and training dataset name.
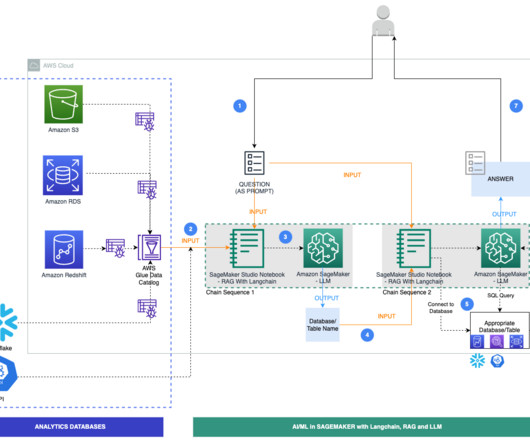
An AWS Glue crawler is scheduled to run at frequent intervals to extract metadata from databases and create table definitions in the AWS Glue Data Catalog. LangChain, a tool to work with LLMs and prompts, is used in Studio notebooks. LangChain requires an LLM to be defined.
In this first step, the AI model, in this case an LLM, is acting as an interpreter and user experience interface between your natural language input and the structured information needed by the travel planning system. The broker agent determines where to send each message based on its content or metadata, making routing decisions at runtime.
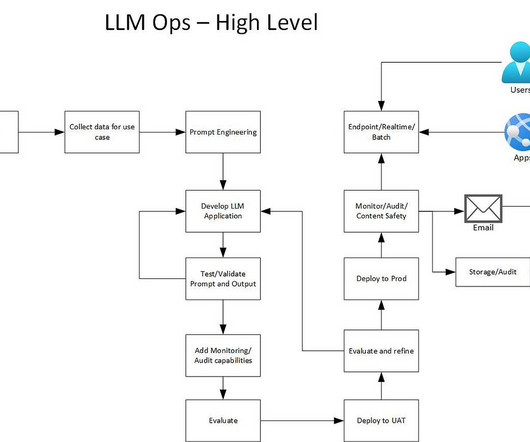
High level process and flow LLM Ops is people, process and technology. LLM Ops flow — Architecture Architecture explained. Develop the LLM application using existing models or train a new model. Storage all prompts and completions in a data lake for future use and also metadata about api, configurations etc.
They guide the LLM to generate text in a specific tone, style, or adhering to a logical reasoning pattern, etc. For example, an LLM trained on predominantly European data might overrepresent those perspectives, unintentionally narrowing the scope of information or viewpoints it offers. Lets see how to use them in a simple example.
For the instruction, VerbaGPT tells the LLM to create content based on the specified template, evaluate the context to see if it’s applicable, and revise the draft accordingly. This repeats until all context is considered and the LLM outputs a draft matching the included template. Build an LLM gateway abstraction layer.
We dive into the technical aspects of our implementation and explain our decision to choose Amazon Bedrock as our foundation model provider. However, when the article is complete, supporting information and metadata must be defined, such as an article summary, categories, tags, and related articles.
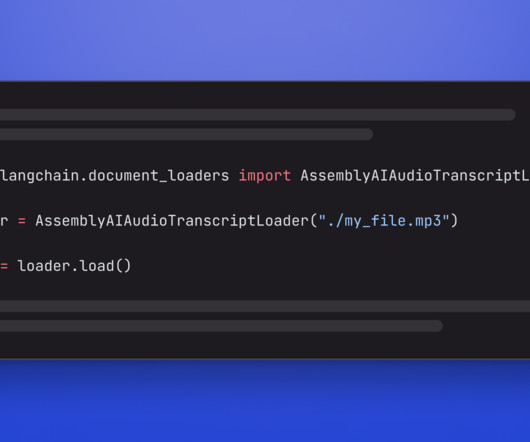
Solution overview The following diagram is a high-level reference architecture that explains how you can further enhance an IDP workflow with foundation models. You can use LLMs in one or all phases of IDP depending on the use case and desired outcome. LangChain offers document loaders that can load and transform data from documents.
This includes features for model explainability, fairness assessment, privacy preservation, and compliance tracking. When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Is it fast and reliable enough for your workflow?
How do multimodal LLMs work? A typical multimodal LLM has three primary modules: The input module comprises specialized neural networks for each specific data type that output intermediate embeddings. Basic structure of a multimodal LLM. The modal can explain an image (1, 2) or answer questions based on an image (3, 4).
Explainability Provides explanations for its predictions through generated text, offering insights into its decision-making process. The raw data is processed by an LLM using a preconfigured user prompt. The LLM generates output based on the user prompt. The Step Functions workflow starts.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content