This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Cisco’s 2024 Data Privacy Benchmark Study revealed that 48% of employees admit to entering non-public company information into GenAI tools (and an unknown number have done so and won’t admit it), leading 27% of organisations to ban the use of such tools. The best way to reduce the risks is to limit access to sensitive data.
OpenAI is joining the Coalition for Content Provenance and Authenticity (C2PA) steering committee and will integrate the open standard’s metadata into its generative AI models to increase transparency around generated content.
Research papers and engineering documents often contain a wealth of information in the form of mathematical formulas, charts, and graphs. Navigating these unstructured documents to find relevant information can be a tedious and time-consuming task, especially when dealing with large volumes of data. Generate metadata for the page.
This conversational agent offers a new intuitive way to access the extensive quantity of seed product information to enable seed recommendations, providing farmers and sales representatives with an additional tool to quickly retrieve relevant seed information, complementing their expertise and supporting collaborative, informed decision-making.
An AI-native data abstraction layer acts as a controlled gateway, ensuring your LLMs only access relevant information and follow proper security protocols. It can also enable consistent access to metadata and context no matter what models you are using. This enhances trust and ensures repeatable, consistent results.
The platform automatically analyzes metadata to locate and label structured data without moving or altering it, adding semantic meaning and aligning definitions to ensure clarity and transparency. Can you explain the core concept and what motivated you to tackle this specific challenge in AI and data analytics?
The evolution of Large Language Models (LLMs) allowed for the next level of understanding and information extraction that classical NLP algorithms struggle with. This article will focus on LLM capabilities to extract meaningful metadata from product reviews, specifically using OpenAI API. Just in case they are present in your dataset.
in Information Systems Engineering from Ben Gurion University and an MBA from the Technion, Israel Institute of Technology. Along the way, I’ve learned different best practices – from how to manage a team to how to inform the proper strategy – that have shaped how I lead at Deep Instinct. He holds a B.Sc Not all AI is equal.
To equip FMs with up-to-date and proprietary information, organizations use Retrieval Augmented Generation (RAG), a technique that fetches data from company data sources and enriches the prompt to provide more relevant and accurate responses. However, information about one dataset can be in another dataset, called metadata.
Database metadata can be expressed in various formats, including schema.org and DCAT. ML data has unique requirements, like combining and extracting data from structured and unstructured sources, having metadata allowing for responsible data use, or describing ML usage characteristics like training, test, and validation sets.
In this post, we discuss how to use LLMs from Amazon Bedrock to not only extract text, but also understand information available in images. Solution overview In this post, we demonstrate how to use models on Amazon Bedrock to retrieve information from images, tables, and scanned documents. 90B Vision model.
The graph, stored in Amazon Neptune Analytics, provides enriched context during the retrieval phase to deliver more comprehensive, relevant, and explainable responses tailored to customer needs. By linking this contextual information, the generative AI system can provide responses that are more complete, precise, and grounded in source data.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services. versions, catering to different programming preferences.
The metadata contains the full JSON response of our API with more meta information: print(docs[0].metadata) The metadata needs to be smaller than the text chunk size, and since it contains the full JSON response with extra information, it is quite large. print(docs[0].text) text) # Runner's knee.
In the following sections, we explain how AI Workforce enables asset owners, maintenance teams, and operations managers in industries such as energy and telecommunications to enhance safety, reduce costs, and improve efficiency in infrastructure inspections. In this post, we introduce the concept and key benefits.
Among the tasks necessary for internal and external compliance is the ability to report on the metadata of an AI model. Metadata includes details specific to an AI model such as: The AI model’s creation (when it was created, who created it, etc.) But the implementation of AI is only one piece of the puzzle.
IBM ® created an AI assistant named OLGA that offered case categorization, extracted metadata and could help bring cases to faster resolution. With OLGA, judges and clerks can sift through thousands of documents faster and use specific search criteria to find relevant information from various documents.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. The development and use of these models explain the enormous amount of recent AI breakthroughs. AI governance refers to the practice of directing, managing and monitoring an organization’s AI activities.
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset data model. Unstructured information may have a little or a lot of structure but in ways that are unexpected or inconsistent. A metadata layer helps build the relationship between the raw data and AI extracted output.
These indexes enable efficient searching and retrieval of part data and vehicle information, providing quick and accurate results. The agents also automatically call APIs to perform actions and access knowledge bases to provide additional information. The embeddings are stored in the Amazon OpenSearch Service owner manuals index.
Building a robust data foundation is critical, as the underlying data model with proper metadata, data quality, and governance is key to enabling AI to achieve peak efficiencies. For example, attributing financial loss or compliance risk to specific entities or individuals without properly explaining why it’s appropriate to do so.
It will help them operationalize and automate governance of their models to ensure responsible, transparent and explainable AI workflows, identify and mitigate bias and drift, capture and document model metadata and foster a collaborative environment.
For use cases where accuracy is critical, customers need the use of mathematically sound techniques and explainable reasoning to help generate accurate FM responses. Encoding your domain knowledge into structured policies helps your conversational AI applications provide reliable and trustworthy information to your users.
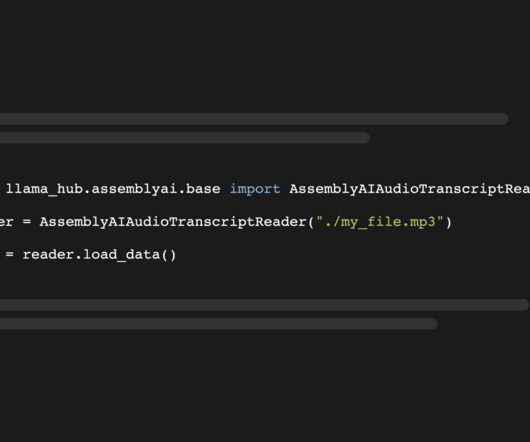
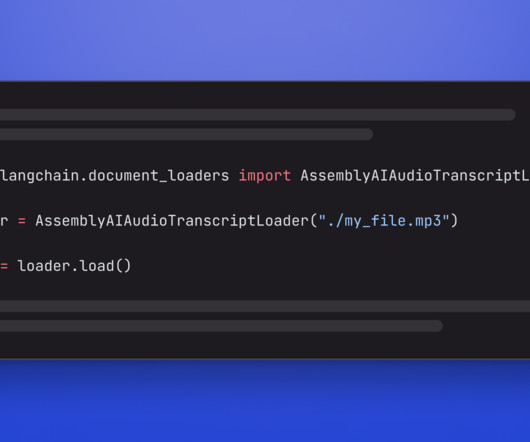
The metadata contains the full JSON response of our API with more meta information: print(docs[0].metadata) "), ] result = transcript.lemur.question(questions) Conclusion This tutorial explained how to use the AssemblyAI integration that was added to the LangChain Python framework in version 0.0.272.
of a company’s total worldwide annual turnover (whichever is higher) for the supply of incorrect information. watsonx.governance drives model transparency, explainability and documentation in 3 key areas: Regulatory compliance – manage AI to meet the upcoming safety and transparency regulations, policies and standards worldwide.
For each flight, the dataset has information such as the flight’s origin airport, departure time, flying time, and arrival time. Now I’ll not gain any further insights from the entire dataset, as this can leak information to the modeling phase. Db2 Warehouse on cloud also supports these ML features.
In the rapidly evolving healthcare landscape, patients often find themselves navigating a maze of complex medical information, seeking answers to their questions and concerns. However, accessing accurate and comprehensible information can be a daunting task, leading to confusion and frustration.
By implementing this architectural pattern, organizations that use Google Workspace can empower their workforce to access groundbreaking AI solutions powered by Amazon Web Services (AWS) and make informed decisions without leaving their collaboration tool. This request contains the user’s message and relevant metadata.
So, instead of wandering the aisles in hopes you’ll stumble across the book, you can walk straight to it and get the information you want much faster. It uses metadata and data management tools to organize all data assets within your organization. Weeks pass by until the IT team locates and masks the data. Speed and self-service.
For more information about version updates, see Shut down and Update Studio Classic Apps. Each model card shows key information, including: Model name Provider name Task category (for example, Text Generation) Select the model card to view the model details page. Search for Meta to view the Meta model card.
A key advancement in AI capabilities is the development and use of chain-of-thought (CoT) reasoning, where models explain their steps before reaching an answer. If models explain their reasoning in natural language, developers can trace the logic and detect faulty assumptions or unintended behaviors.
For more information, see Use quick setup for Amazon SageMaker AI. For more information, see the instructions for setting up a new MLflow tracking server. MLflow tracing is a feature that enhances observability in your generative AI agent by capturing detailed information about the execution of the agent services, nodes, and tools.
Multimodal Capabilities in Detail Configuring Your Development Environment Project Structure Implementing the Multimodal Chatbot Setting Up the Utilities (utils.py) Designing the Chatbot Logic (chatbot.py) Building the Interface (app.py) Summary Citation Information Building a Multimodal Gradio Chatbot with Llama 3.2 Introducing Llama 3.2
Dynamic Content: Unlike static resumes, the chatbot can provide tailored responses based on the recruiters queries, ensuring relevant and up-to-date information. Real-Time Updates: You can instantly update your skills, experiences, or achievements, ensuring recruiters always have access to the most current information.
It processes natural language queries to understand the issue context and manages conversation flow to gather required information. If essential information is missing, such as a cluster name or instance ID, the agent engages in a natural conversation to gather the required parameters. The agent uses Anthropics Claude 3.5
They aim to decrypt or recover as much hidden or deleted information as possible. Since devices store information every time their user downloads something, visits a website or creates a post, a sort of electronic paper trail exits. Investigators can train or prompt it to seek case-specific information.
The challenge here is to retrieve the relevant data source to answer the question and correctly extract information from that data source. Use cases we have worked on include: Technical assistance for field engineers – We built a system that aggregates information about a company’s specific products and field expertise.
Inspect Rich Documents with Gemini Multimodality and Multimodal RAG This course covers using multimodal prompts to extract information from text and visual data and generate video descriptions with Gemini. Introduction to Responsible AI This course explains what responsible AI is, its importance, and how Google implements it in its products.
It allows users to explain and generate code, fix errors, summarize content, and even generate entire notebooks from natural language prompts. Moreover, it saves metadata about model-generated content, facilitating tracking of AI-generated code within the workflow. The AI then responds based on the stored information.
A significant challenge in AI applications today is explainability. This enhances transparency and reliability, enabling businesses to make informed decisions with confidence. How does the knowledge graph architecture of the AI Context Engine enhance the accuracy and explainability of LLMs compared to SQL databases alone?
This method of enriching the LLM generation context with information retrieved from your internal data sources is called Retrieval Augmented Generation (RAG), and produces assistants that are domain specific and more trustworthy, as shown by Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
Can you explain how HeavyIQ leverages natural language processing to facilitate data exploration and visualization? What measures are in place to prevent metadata leakage when using HeavyIQ? This includes not only data but also several kinds of metadata. Lastly, the language models themselves generate further metadata.
First, you extract label and celebrity metadata from the images, using Amazon Rekognition. You then generate an embedding of the metadata using a LLM. You store the celebrity names, and the embedding of the metadata in OpenSearch Service. Overview of solution The solution is divided into two main sections.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content