This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Data science’s abilities are so versatile that they open up various job alternatives. Quite independently of whether your focus is on business analysis, product management, or ethical issues, there is always a job that one would be eager to do and can do well. Thus, in the rapidly developing field of data science, such […] The post Top 10 Data Science Alternative Career Paths appeared first on Analytics Vidhya.
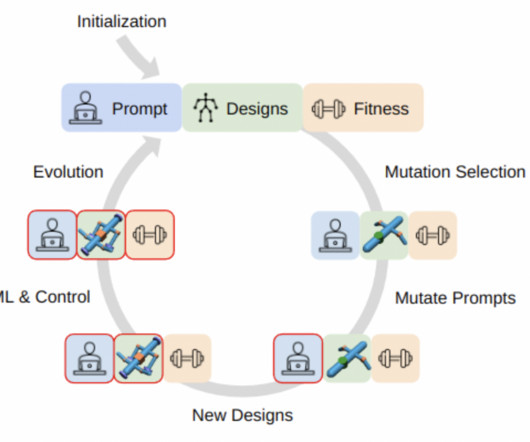
The field of robotics is seeing transformative changes with the integration of generative methods like large language models (LLMs). These advancements enable the developing of sophisticated systems that autonomously navigate and adapt to various environments. The application of LLMs in robot design and control processes represents a significant leap forward, offering the potential to create robots that are more efficient & capable of performing complex tasks with greater autonomy.
In this paper, we address the problem of estimating the rotational extrinsics, as well as the scale factors of two gyroscopes rigidly mounted on the same device. In particular, we formulate the problem as a least-squares minimization and introduce a direct algorithm that computes the estimated quantities without any iterations, hence avoiding local minima and improving efficiency.
Large Language Models (LLMs) have demonstrated remarkable proficiency in language generation tasks. However, their training process, which involves unsupervised learning from extensive datasets followed by supervised fine-tuning, presents significant challenges. The primary concern stems from the nature of pre-training datasets, such as Common Crawl, which often contain undesirable content.
Start building the AI workforce of the future with our comprehensive guide to creating an AI-first contact center. Learn how Conversational and Generative AI can transform traditional operations into scalable, efficient, and customer-centric experiences. What is AI-First? Transition from outdated, human-first strategies to an AI-driven approach that enhances customer engagement and operational efficiency.
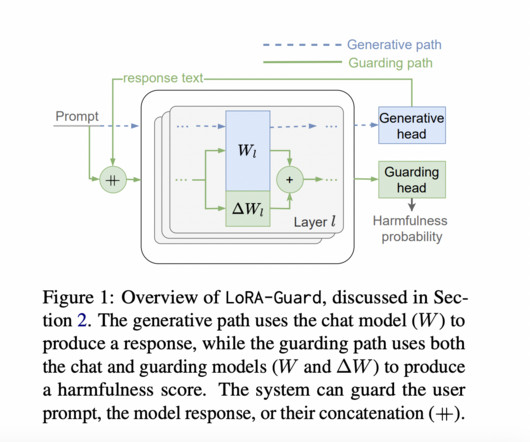
An important issue with Large Language Models (LLMs) is their undesired ability to generate toxic language. In this work, we show that the neurons responsible for toxicity can be determined by their power to discriminate toxic sentences, and that toxic language can be mitigated by reducing their activation levels proportionally to this power. We propose AUROC adaptation (AURA), an intervention that can be applied to any pre-trained LLM to mitigate toxicity.
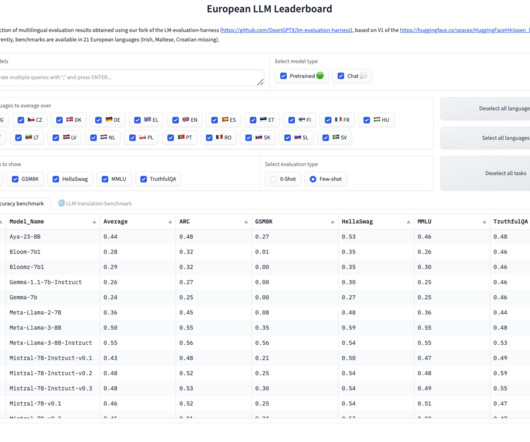
The release of the European LLM Leaderboard by the OpenGPT-X team presents a great milestone in developing and evaluating multilingual language models. The project, supported by TU Dresden and a consortium of ten partners from various sectors, aims to advance language models’ capabilities in handling multiple languages, thereby reducing digital language barriers and enhancing the versatility of AI applications across Europe.
The release of the European LLM Leaderboard by the OpenGPT-X team presents a great milestone in developing and evaluating multilingual language models. The project, supported by TU Dresden and a consortium of ten partners from various sectors, aims to advance language models’ capabilities in handling multiple languages, thereby reducing digital language barriers and enhancing the versatility of AI applications across Europe.
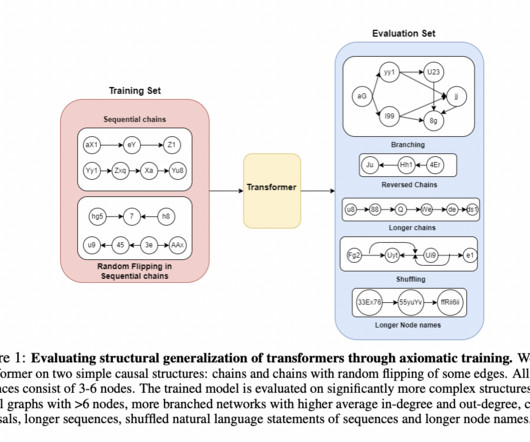
In this work, we study how well the learned weights of a neural network utilize the space available to them. This notion is related to capacity, but additionally incorporates the interaction of the network architecture with the dataset. Most learned weights appear to be full rank, and are therefore not amenable to low rank decomposition. This deceptively implies that the weights are utilizing the entire space available to them.
Artificial intelligence (AI) has transformed traditional research, propelling it to unprecedented heights. However, it has a ways to go regarding other spheres of its application. A critical issue in AI is training models to perform causal reasoning. Traditional methods heavily depend on large datasets with explicitly marked causal relationships, which are often expensive and challenging to obtain.
We investigate the out-of-domain generalization of random feature (RF) models and Transformers. We first prove that in the ‘generalization on the unseen (GOTU)’ setting, where training data is fully seen in some part of the domain but testing is made on another part, and for RF models in the small feature regime, the convergence takes place to interpolators of minimal degree as in the Boolean case (Abbe et al., 2023).
Large Language Models (LLMs) built on the Transformer architecture have recently attained important technological milestones. The remarkable skills of these models in comprehending and producing writing that resembles that of a human have had a significant impact on a variety of Artificial Intelligence (AI) applications. Although these models function admirably, there are many obstacles to successfully implementing them in low-resource contexts.
Today’s buyers expect more than generic outreach–they want relevant, personalized interactions that address their specific needs. For sales teams managing hundreds or thousands of prospects, however, delivering this level of personalization without automation is nearly impossible. The key is integrating AI in a way that enhances customer engagement rather than making it feel robotic.
Large Language Model (LLM) agents, capable of performing a broad range of actions, such as invoking tools and controlling robots, show great potential in tackling real-world challenges. LLM agents are typically prompted to produce actions by generating JSON or text in a pre-defined format, which is usually limited by constrained action space (e.g., the scope of pre-defined tools) and restricted flexibility (e.g., inability to compose multiple tools).
Large language models (LLMs) have shown exceptional capabilities in understanding and generating human language, making substantial contributions to applications such as conversational AI. Chatbots powered by LLMs can engage in naturalistic dialogues, providing a wide range of services. The effectiveness of these chatbots relies heavily on high-quality instruction-following data used in post-training, enabling them to assist and communicate effectively with humans.
Summary: This blog explores the different types of keys in DBMS, including Primary, Unique, Foreign, Composite, and Super Keys. It highlights their unique functionalities and applications, emphasising their roles in maintaining data integrity and facilitating efficient data retrieval in database design and management. Introduction In Database Management Systems (DBMS), keys are pivotal in maintaining data integrity and facilitating efficient data retrieval.
Transformer-based LLMs like ChatGPT and LLaMA excel in tasks requiring domain expertise and complex reasoning due to their large parameter sizes and extensive training data. However, their substantial computational and storage demands limit broader applications. Quantization addresses these challenges by converting 32-bit parameters to smaller bit sizes, enhancing storage efficiency and computational speed.
The guide for revolutionizing the customer experience and operational efficiency This eBook serves as your comprehensive guide to: AI Agents for your Business: Discover how AI Agents can handle high-volume, low-complexity tasks, reducing the workload on human agents while providing 24/7 multilingual support. Enhanced Customer Interaction: Learn how the combination of Conversational AI and Generative AI enables AI Agents to offer natural, contextually relevant interactions to improve customer exp
Says Microsoft: We’re going to help ourselves to your Web content, thank you Apparently, when it comes to copyright law, Microsoft never got the memo. According to Mustafa Suleyman, Microsoft’s CEO of AI, as reported by writer Sean Endicott: “With respect to content that is already on the open Web, the social contract of that content since the 90s has been that it is fair use. “Anyone can copy it, recreate with it, reproduce with it.
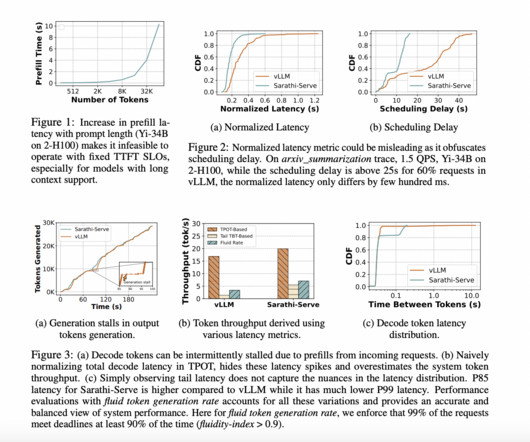
Evaluating the performance of large language model (LLM) inference systems using conventional metrics presents significant challenges. Metrics such as Time To First Token (TTFT) and Time Between Tokens (TBT) do not capture the complete user experience during real-time interactions. This gap is critical in applications like chat and translation, where responsiveness directly affects user satisfaction.
Created Using Ideogram Next Week in The Sequence: Edge 413: Our series about autonomous agents continues with an exploration of semantic memory. We review Meta AI’s MM-LLM research to augment video models with memory and we dive into the Qdrant vector DB stack. Edge 414: We dive into HUSKY, a new agent optimized for multi-step reasoning. You can subscribe to The Sequence below: TheSequence is a reader-supported publication.
Language model adaptation is a crucial area in artificial intelligence, focusing on enhancing large pre-trained language models to work effectively across various languages. This research is vital for enabling these models to understand and generate text in multiple languages, which is essential for global AI applications. Despite the impressive performance of LLMs in English, their capabilities significantly drop when adapted to less prevalent languages, making additional adaptation techniques
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
In 2023, Meta AI proposed training its large language models (LLMs) on user data from Europe. This proposal aims to improve LLMs’ capability to understand the dialect, geography, and cultural references of European users. Meta wished to expand into Europe to optimize the accuracy of its artificial intelligence (AI) technology systems by training them to use user data.
Collecting, monitoring, and maintaining a web data pipeline can be daunting and time-consuming when dealing with large amounts of data. Traditional approaches’ struggles can compromise data quality and availability with pagination, dynamic content, bot detection, and site modifications. Building an in-house technical staff or outsourcing to a low-cost nation are two common options for companies looking to meet their web data needs.
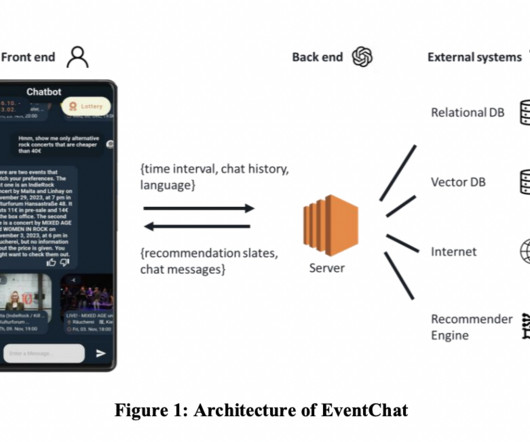
Conversational Recommender Systems (CRS) are revolutionizing how users make decisions by offering personalized suggestions through interactive dialogue interfaces. Unlike traditional systems that present predetermined options, CRS allows users to dynamically input and refine their preferences, significantly reducing information overload. By incorporating feedback loops and advanced machine learning techniques, CRS provides an engaging and intuitive user experience.
Scaling Transformer-based models to over 100 billion parameters has led to groundbreaking results in natural language processing. These large language models excel in various applications, but deploying them efficiently poses challenges due to the sequential nature of generative inference, where each token’s computation relies on the preceding tokens.
The DHS compliance audit clock is ticking on Zero Trust. Government agencies can no longer ignore or delay their Zero Trust initiatives. During this virtual panel discussion—featuring Kelly Fuller Gordon, Founder and CEO of RisX, Chris Wild, Zero Trust subject matter expert at Zermount, Inc., and Principal of Cybersecurity Practice at Eliassen Group, Trey Gannon—you’ll gain a detailed understanding of the Federal Zero Trust mandate, its requirements, milestones, and deadlines.
Input your email to sign up, or if you already have an account, log in here!
Enter your email address to reset your password. A temporary password will be e‑mailed to you.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content