This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Hey there, AI enthusiasts! Welcome to The AV Bytes, your friendly neighborhood source for all things AI. Buckle up, because this week has been a wild ride in the world of AI! We’ve got some mind-blowing stuff to share with you. Remember when we thought search engines couldn’t get any better? Well, OpenAI just […] The post AvBytes: Key Developments and Challenges in Generative AI appeared first on Analytics Vidhya.
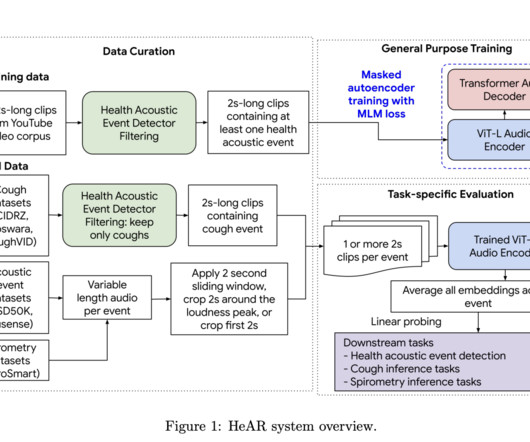
Health acoustics, encompassing sounds like coughs and breathing, hold valuable health information but must be utilized more in medical machine learning. Existing deep learning models for these acoustics are often task-specific, limiting their generalizability. Non-semantic speech attributes can aid in emotion recognition and detecting diseases like Parkinson’s and Alzheimer’s.
Introduction In artificial intelligence, a groundbreaking development has emerged that promises to reshape the very process of scientific discovery. In collaboration with the Foerster Lab for AI Research at the University of Oxford and researchers from the University of British Columbia, Sakana AI has introduced “The AI Scientist” – a comprehensive system designed for fully […] The post Sakana AI’s “AI Scientist”: The Next Einstein or Just a Tool?
The release of DocChat by Cerebras marks a major milestone in document-based conversational question-answering systems. Cerebras, known for its deep expertise in machine learning (ML) and large language models (LLMs), has introduced two new models under the DocChat series: Cerebras Llama3-DocChat and Cerebras Dragon-DocChat. These models are designed to deliver high-performance conversational AI, specifically tailored for document-based question-answering tasks, and were developed with unprecede
Start building the AI workforce of the future with our comprehensive guide to creating an AI-first contact center. Learn how Conversational and Generative AI can transform traditional operations into scalable, efficient, and customer-centric experiences. What is AI-First? Transition from outdated, human-first strategies to an AI-driven approach that enhances customer engagement and operational efficiency.
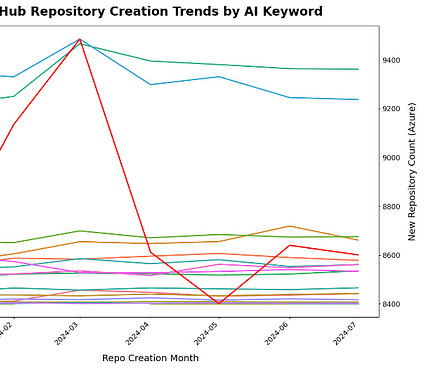
Last Updated on September 2, 2024 by Editorial Team Author(s): Jonathan Bennion Originally published on Towards AI. Cutting through the AI hype to query actual developer usage (as new repos, so with presumptions) for prioritization of safety tools and partnerships. TLDR (with caveats noted below): Public AI repos now appear as linear growth, not exponential (surge in March 2024 followed by rapid decline, now slower but steady).
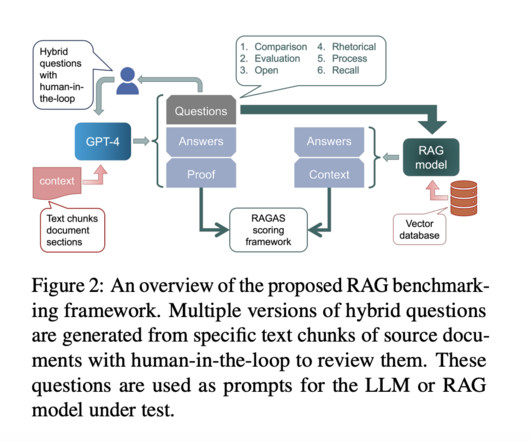
Natural Language Processing (NLP) has seen remarkable advancements, particularly in text generation techniques. Among these, Retrieval Augmented Generation (RAG) is a method that significantly improves the coherence, factual accuracy, and relevance of generated text by incorporating information retrieved from specific databases. This approach is especially crucial in specialized fields where precision and context are essential, such as renewable energy, nuclear policy, and environmental impact s
Natural Language Processing (NLP) has seen remarkable advancements, particularly in text generation techniques. Among these, Retrieval Augmented Generation (RAG) is a method that significantly improves the coherence, factual accuracy, and relevance of generated text by incorporating information retrieved from specific databases. This approach is especially crucial in specialized fields where precision and context are essential, such as renewable energy, nuclear policy, and environmental impact s
Are you searching for how to register google gemini ai? Here is the the simple step-by-step registration guide for Google gemini ai. The world of digital marketing is constantly evolving, and the challenge is to keep up with its pace. One game-changing innovation that has been making waves is Google Gemini AI. As a digital marketer, you may be intrigued about the Google Gemini AI sign up process and how it could boost your marketing campaigns.
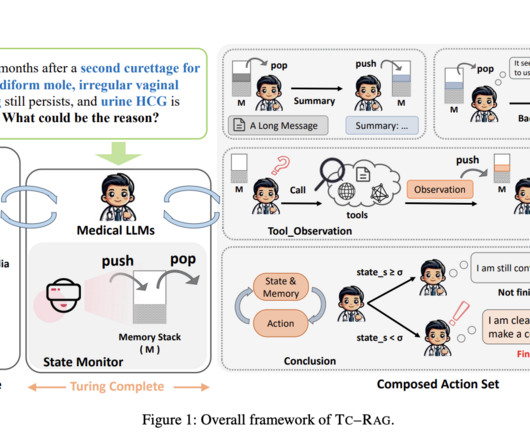
The field of large language models (LLMs) has rapidly evolved, particularly in specialized domains like medicine, where accuracy and reliability are crucial. In healthcare, these models promise to significantly enhance diagnostic accuracy, treatment planning, and the allocation of medical resources. However, the challenges inherent in managing the system state and avoiding errors within these models remain significant.
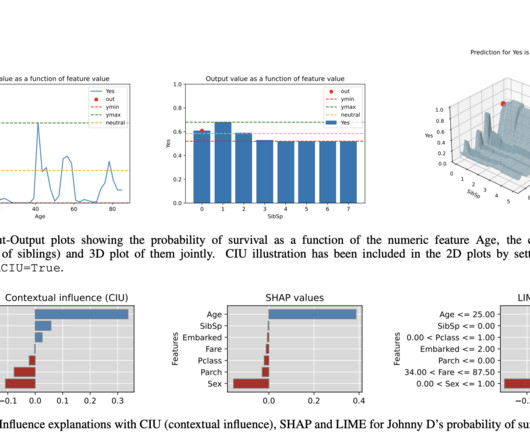
EXplainable AI (XAI) has become a critical research domain since AI systems have progressed to being deployed in essential sectors such as health, finance, and criminal justice. These systems have been making decisions that would largely affect the lives of human beings; thus, it’s necessary to understand why their output will end at such results.
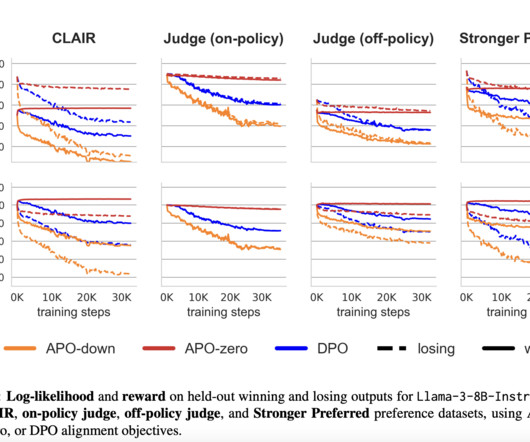
Artificial intelligence (AI) development, particularly in large language models (LLMs), focuses on aligning these models with human preferences to enhance their effectiveness and safety. This alignment is critical in refining AI interactions with users, ensuring that the responses generated are accurate and aligned with human expectations and values.
Today’s buyers expect more than generic outreach–they want relevant, personalized interactions that address their specific needs. For sales teams managing hundreds or thousands of prospects, however, delivering this level of personalization without automation is nearly impossible. The key is integrating AI in a way that enhances customer engagement rather than making it feel robotic.
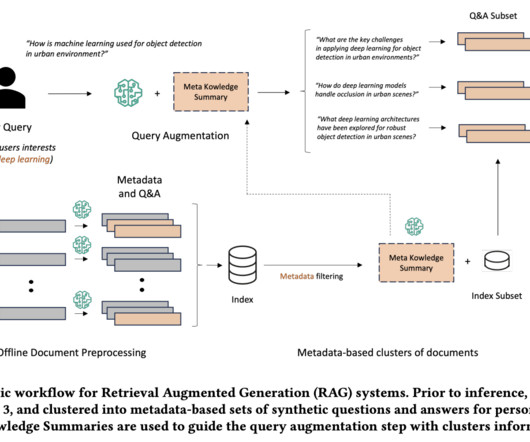
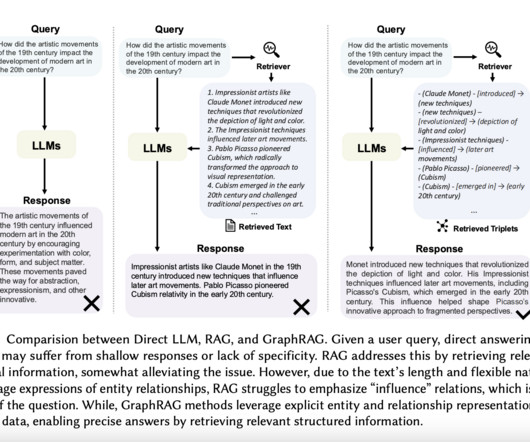
Retrieval Augmented Generation (RAG) represents a cutting-edge advancement in Artificial Intelligence, particularly in NLP and Information Retrieval (IR). This technique is designed to enhance the capabilities of Large Language Models (LLMs) by seamlessly integrating contextually relevant, timely, and domain-specific information into their responses.
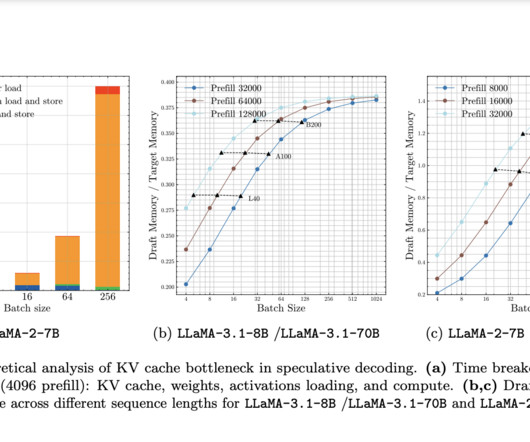
As Large Language Models (LLMs) become increasingly prevalent in long-context applications like interactive chatbots and document analysis, serving these models with low latency and high throughput has emerged as a significant challenge. Conventional wisdom suggests that techniques like speculative decoding (SD), while effective for reducing latency, are limited in improving throughput, especially for larger batch sizes.
Understanding spoken language for large language models (LLMs) is crucial for creating more natural and intuitive interactions with machines. While traditional models excel at text-based tasks, they struggle with comprehending human speech, limiting their potential in real-world applications like voice assistants, customer service, and accessibility tools.
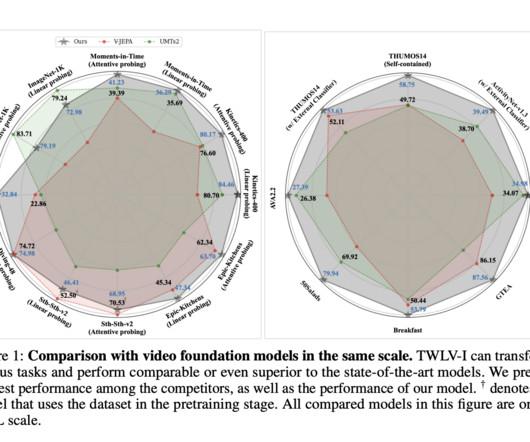
Language Foundation Models (LFMs) and Large Language Models (LLMs) have demonstrated their ability to handle multiple tasks efficiently with a single fixed model. This achievement has motivated the development of Image Foundation Models (IFMs) in computer vision, which aim to encode general information from images into embedding vectors. However, using these techniques poses a challenge in video analysis.
The guide for revolutionizing the customer experience and operational efficiency This eBook serves as your comprehensive guide to: AI Agents for your Business: Discover how AI Agents can handle high-volume, low-complexity tasks, reducing the workload on human agents while providing 24/7 multilingual support. Enhanced Customer Interaction: Learn how the combination of Conversational AI and Generative AI enables AI Agents to offer natural, contextually relevant interactions to improve customer exp
Large Language Models (LLMs) like GPT-4, Qwen2, and LLaMA have revolutionized artificial intelligence, particularly in natural language processing. These Transformer-based models, trained on vast datasets, have shown remarkable capabilities in understanding and generating human language, impacting healthcare, finance, and education sectors. However, LLMs need more domain-specific knowledge, real-time information, and proprietary data outside their training corpus.
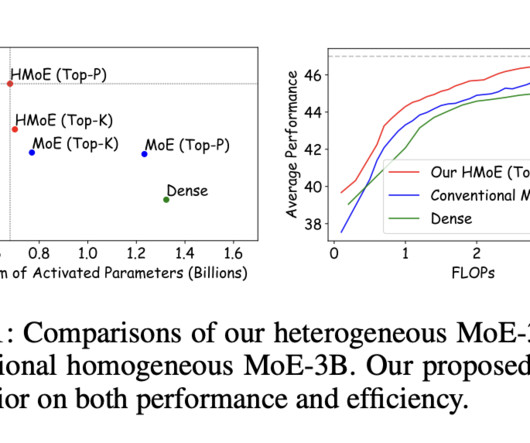
The Mixture of Experts (MoE) models enhance performance and computational efficiency by selectively activating subsets of model parameters. While traditional MoE models utilize homogeneous experts with identical capacities, this approach limits specialization and parameter utilization, especially when handling varied input complexities. Recent studies highlight that homogeneous experts tend to converge to similar representations, reducing their effectiveness.
Repeatedly switching back and forth between various AI tools and applications to perform simple tasks like grammar checks or content edits can be daunting. This constant back-and-forth often wastes time and interrupts workflow, which hinders the efficiency of the process. Users usually find themselves juggling multiple tabs and copying and pasting text, complicating straightforward tasks.
For optimal performance, AI models require top-notch data. Obtaining and organizing this data may be quite a challenge, unfortunately. There is a risk that publicly available datasets must be more adequate, too broad, or tainted to be useful for some purposes. It can be challenging to find domain experts, which is a problem for many datasets. There is a need for Golden Datasets and Frontier Benchmarking in a world where AI propels economic growth and promotes scientific research.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content