This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction In the previous article, we experimented with Cohere’s Command-R model and Rerank model to generate responses and rerank doc sources. We have implemented a simple RAG pipeline using them to generate responses to user’s questions on ingested documents. However, what we have implemented is very simple and unsuitable for the general user, as it […] The post Building RAG Application using Cohere Command-R and Rerank – Part 2 appeared first on Analytics Vidhya.
“Generative AI is reshaping industries and opening new opportunities for innovation and growth,” NVIDIA founder and CEO Jensen Huang said in an address ahead of this week’s COMPUTEX technology conference in Taipei. “Today, we’re at the cusp of a major shift in computing,” Huang told the audience, clad in his trademark black leather jacket. “The intersection of AI and accelerated computing is set to redefine the future.
In our latest episode of Leading with Data, we had the privilege of speaking with Ravit Dotan, a renowned expert in AI ethics. Ravit Dotan’s diverse background, including a PhD in philosophy from UC Berkeley and her leadership in AI ethics at Bria.ai, uniquely positions her to offer profound insights into responsible AI practices. Throughout […] The post Exploring Responsible AI: Insights, Frameworks & Innovations with Ravit Dotan appeared first on Analytics Vidhya.
Deploying generative AI in the enterprise is about to get easier than ever. NVIDIA NIM , a set of generative AI inference microservices, works with KServe , open-source software that automates putting AI models to work at the scale of a cloud computing application. The combination ensures generative AI can be deployed like any other large enterprise application.
Today’s buyers expect more than generic outreach–they want relevant, personalized interactions that address their specific needs. For sales teams managing hundreds or thousands of prospects, however, delivering this level of personalization without automation is nearly impossible. The key is integrating AI in a way that enhances customer engagement rather than making it feel robotic.
We are excited to announce a new data type called variant for semi-structured data. Variant provides an order of magnitude performance improvements compared.
Meta Llama 3, Meta’s openly available state-of-the-art large language model — trained and optimized using NVIDIA accelerated computing — is dramatically boosting healthcare and life sciences workflows, helping deliver applications that aim to improve patients’ lives. Now available as a downloadable NVIDIA NIM inference microservice at ai.nvidia.com , Llama 3 is equipping healthcare developers, researchers and companies to innovate responsibly across a wide variety of applications.
Meta Llama 3, Meta’s openly available state-of-the-art large language model — trained and optimized using NVIDIA accelerated computing — is dramatically boosting healthcare and life sciences workflows, helping deliver applications that aim to improve patients’ lives. Now available as a downloadable NVIDIA NIM inference microservice at ai.nvidia.com , Llama 3 is equipping healthcare developers, researchers and companies to innovate responsibly across a wide variety of applications.
AI is a fresh threat to recent grads and job applicants, as many fear they have wasted years of study for technology to replace them. What should companies do to acquire valuable talent in the age of advancing AI? Understanding the Modern Workforce’s Feelings About AI Those entering the workforce with AI have mixed feelings about its presence, depending on demographics.
Foxconn operates more than 170 factories around the world — the latest one a virtual plant pushing the state of the art in industrial automation. It’s the digital twin of a new factory in Guadalajara, hub of Mexico’s electronics industry. Foxconn’s engineers are defining processes and training robots in this virtual environment, so the physical plant can produce at high efficiency the next engine of accelerated computing, NVIDIA Blackwell HGX systems.
Taiwan’s leading medical centers — the National Health Research Institute (NHRI) and Chang Gung Memorial Hospital (CGMH) — are set to advance biomedical research and healthcare for patients. The centers are embracing accelerated computing and generative AI for everything from imaging to enhancing patient care, from streamlining clinical workflows to drug discovery research.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
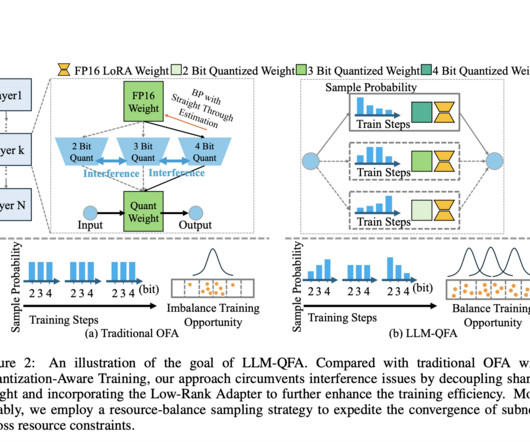
Large Language Models (LLMs) have made significant advancements in natural language processing but face challenges due to memory and computational demands. Traditional quantization techniques reduce model size by decreasing the bit-width of model weights, which helps mitigate these issues but often leads to performance degradation. This problem gets worse when LLMs are used in different situations with limited resources.
Weather forecasters in Taiwan had their hair blown back when they saw a typhoon up close, created on a computer that slashed the time and energy needed for the job. It’s a reaction that users in many fields are feeling as generative AI shows them how new levels of performance contribute to reductions in total cost of ownership. Inside the AI of the Storm Tracking a typhoon provided a great test case of generative AI’s prowess.
Created Using DALL-E Next Week in The Sequence: Mistral Codestral is the New Model for Code Generation Edge 401: We dive into reflection and refimenent planning for agents. Review the famous Reflextion paper and the AgentVerse framework for multi-agent task planning. Edge 402: We review UC Berkeley’s research about models that can understand one hour long videos.
Fueled by generative AI , enterprises globally are creating “AI factories,” where data comes in and intelligence comes out. Critical to this movement are validated systems and reference architectures that reduce the risk and time involved in deploying specialized infrastructure that can support complex, computationally intensive generative AI workloads.
The DHS compliance audit clock is ticking on Zero Trust. Government agencies can no longer ignore or delay their Zero Trust initiatives. During this virtual panel discussion—featuring Kelly Fuller Gordon, Founder and CEO of RisX, Chris Wild, Zero Trust subject matter expert at Zermount, Inc., and Principal of Cybersecurity Practice at Eliassen Group, Trey Gannon—you’ll gain a detailed understanding of the Federal Zero Trust mandate, its requirements, milestones, and deadlines.
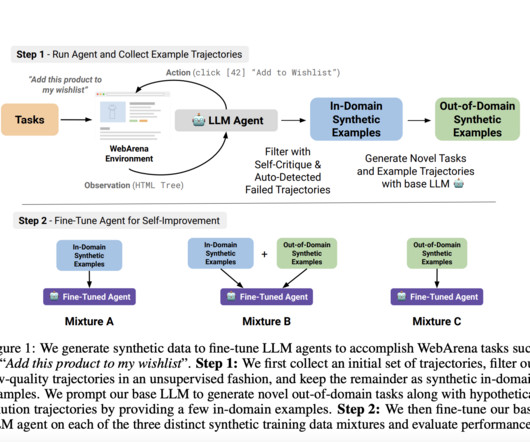
Large language models (LLMs) have shown their potential in many natural language processing (NLP) tasks, like summarization and question answering using zero-shot and few-shot prompting approaches. However, prompting alone is not enough to make LLMs work as agents who can navigate environments to solve complex and multi-step. Fine-tuning LLMs for these tasks is also impractical due to the unavailability of training data.
Articles Hazy Research from Stanford wrote an article on ThunderKittens which is an embedded DSL for GPUs, and post specifically talks about how TunderKittens applies in H100 GPUs. Article is talking about tensor operations used in machine learning workloads and explains how ThunderKittens is adding value on top of the existing solutions like Triton.
It’s official: One of the world’s richest and mightiest tech companies has turned to ChatGPT to bring AI to its smartphone. A major coup for ChatGPT’s maker OpenAI, the deal will bring ChatGPT to millions of iPhone users who are running — or will be running — iOS 18 software on their devices. The Times of India also reports that Apple may feature ChatGPT competitors on its iPhone as well — such as Google Gemini.
Speaker: Alexa Acosta, Director of Growth Marketing & B2B Marketing Leader
Marketing is evolving at breakneck speed—new tools, AI-driven automation, and changing buyer behaviors are rewriting the playbook. With so many trends competing for attention, how do you cut through the noise and focus on what truly moves the needle? In this webinar, industry expert Alexa Acosta will break down the most impactful marketing trends shaping the industry today and how to turn them into real, revenue-generating strategies.
I occasionally write blogs about what my students are doing, and thought I’d write about Barkavi Sundararajan, who is exploring using LLMs for data-to-text, and in particular trying to reduce hallucinations and other errors. Other people have looked at impact of models and prompts, Barkavi is looking at whether LLMs do a better job at data-to-text when the input data (which is being summarised) is well structured.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content