Orthogonal Paths: Simplifying Jailbreaks in Language Models
Marktechpost
JUNE 22, 2024
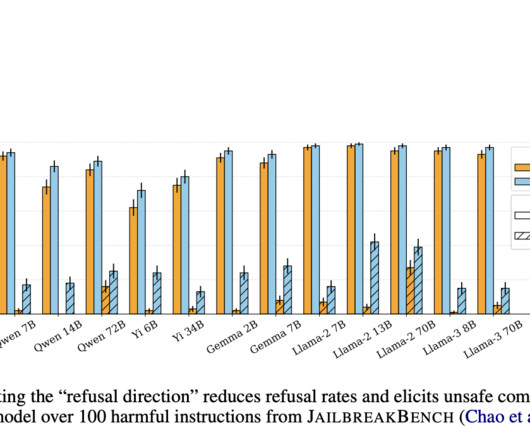
Ensuring the safety and ethical behavior of large language models (LLMs) in responding to user queries is of paramount importance. Problems arise from the fact that LLMs are designed to generate text based on user input, which can sometimes lead to harmful or offensive content. This paper investigates the mechanisms by which LLMs refuse to generate certain types of content and develops methods to improve their refusal capabilities.















Let's personalize your content