This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Wow, it’s that time of the year again—placement season! Are you experiencing a sense of being trapped or feeling inundated while trying to find your way to your ideal data science job? Do not fret; you are not by yourself. Securing that ideal position may seem overwhelming, but using the right strategy can leave […] The post Tips and Tricks to Crack Campus Placement in Data Science appeared first on Analytics Vidhya.
Maintaining strict temperature controls is paramount in cold chain logistics. The integrity of perishable goods, including food and pharmaceuticals, hinges on precise temperature management throughout the supply chain. However, traditional monitoring methods often fall short, leaving gaps that can lead to spoilage, financial losses and regulatory noncompliance.
The European Artificial Intelligence Act came into force on August 1, 2024. It is a significant milestone in the global regulation of artificial intelligence all over the world. It is the world’s first comprehensive milestone in terms of regulation of AI and reflects EU’s ambitions to establish itself as a leader in safe and trustworthy AI development The Genesis and Objectives of the AI Act The Act was first proposed by the EU Commission in April 2021 in the midst of growing concerns about the
With consumer demand climbing, regulations tightening and the cost of doing business rising, facilities must optimize their packaging line efficiency or face losing to their competition. Could automation powered by artificial intelligence be the solution they’re searching for? Why Facilities Need to Optimize Packaging Lines Online shopping’s popularity surged exceptionally high during COVID-19.
Today’s buyers expect more than generic outreach–they want relevant, personalized interactions that address their specific needs. For sales teams managing hundreds or thousands of prospects, however, delivering this level of personalization without automation is nearly impossible. The key is integrating AI in a way that enhances customer engagement rather than making it feel robotic.
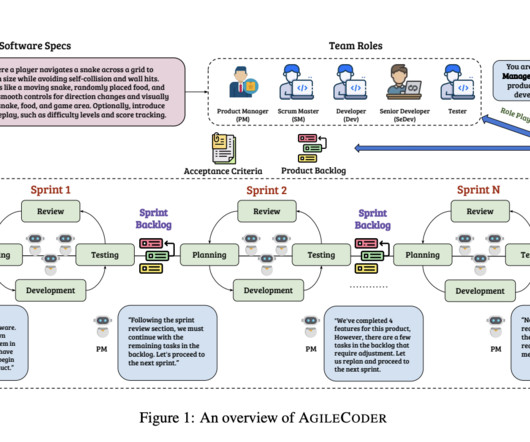
Introduction: Code Large Language Models (CodeLLMs) have demonstrated remarkable proficiency in generating code. However, they struggle with complex software engineering tasks, such as developing an entire software system based on intricate specifications. Recent works, including ChatDev and MetaGPT, have introduced multi-agent frameworks for software development, where agents collaborate to achieve complex goals.
Articles Quantization in deep learning refers to the process of reducing the precision of the numbers used to represent the model's parameters and activations. Typically, deep learning models use 32-bit floating-point numbers (float32) for computations. Quantization aims to use lower precision formats, such as 16-bit floating-point (float16), 8-bit integers (int8), or even lower bit-widths.
Articles Quantization in deep learning refers to the process of reducing the precision of the numbers used to represent the model's parameters and activations. Typically, deep learning models use 32-bit floating-point numbers (float32) for computations. Quantization aims to use lower precision formats, such as 16-bit floating-point (float16), 8-bit integers (int8), or even lower bit-widths.
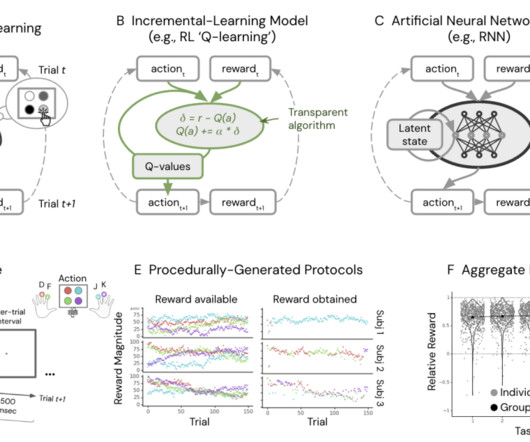
Human reward-guided learning is often modeled using simple RL algorithms that summarize past experiences into key variables like Q-values, representing expected rewards. However, recent findings suggest that these models oversimplify the complexity of human memory and decision-making. For instance, individual events and global reward statistics can significantly influence behavior, indicating that memory involves more than just summary statistics.
Small and large language models represent two approaches to natural language processing (NLP) and have distinct advantages and challenges. Understanding and analyzing the differences between these models is essential for anyone working in AI and machine learning. Small Language Models: Precision and Efficiency Small language models, often characterized by fewer parameters and lower computational requirements, offer several advantages in terms of efficiency and practicality.
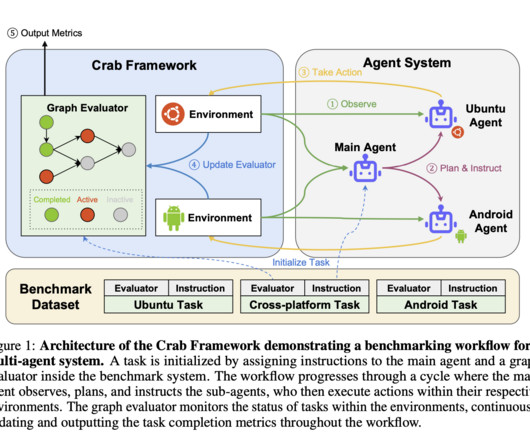
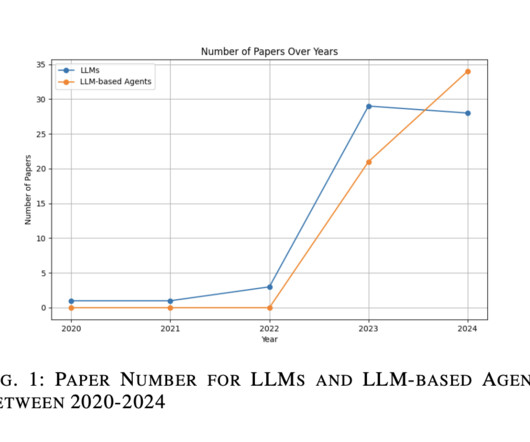
The development of autonomous agents capable of performing complex tasks across various environments has gained significant traction in artificial intelligence research. These agents are designed to interpret and execute natural language instructions within graphical user interface (GUI) environments, such as websites, desktop operating systems, and mobile devices.
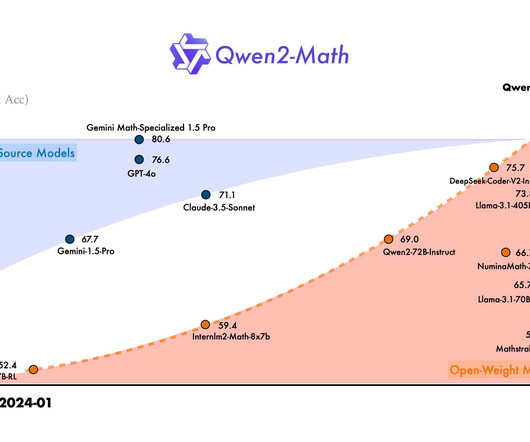
The Qwen Team has recently released the Qwen 2-Math series. This release, encompassing several model variants tailored for distinct applications, demonstrates the team’s commitment to enhancing AI’s proficiency in handling complex mathematical tasks. The Qwen 2-Math series is a comprehensive set of models, each designed to cater to different computational needs.
Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m
Large Language Models (LLMs) have significantly impacted software engineering, primarily in code generation and bug fixing. These models leverage vast training data to understand and complete code based on user input. However, their application in requirement engineering, a crucial aspect of software development, remains underexplored. Software engineers have shown reluctance to use LLMs for higher-level design tasks due to concerns about complex requirement comprehension.
Parler-TTS has emerged as a robust text-to-speech (TTS) library, offering two powerful models: Parler-TTS Large v1 and Parler-TTS Mini v1. Both models are trained on an impressive 45,000 hours of audio data, enabling them to generate high-quality, natural-sounding speech with remarkable control over various features. Users can manipulate aspects such as gender, background noise, speaking rate, pitch, and reverberation through simple text prompts, providing unprecedented flexibility in speech gen
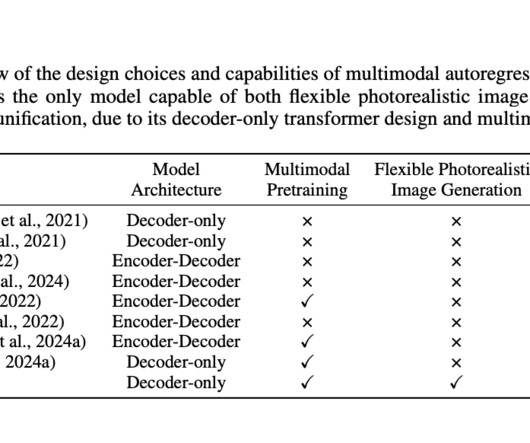
Multimodal generative models represent an exciting frontier in artificial intelligence, focusing on integrating visual and textual data to create systems capable of various tasks. These tasks range from generating highly detailed images from textual descriptions to understanding and reasoning across different data types. The advancements in this field are opening new possibilities for more interactive and intelligent AI systems that can seamlessly combine vision and language.
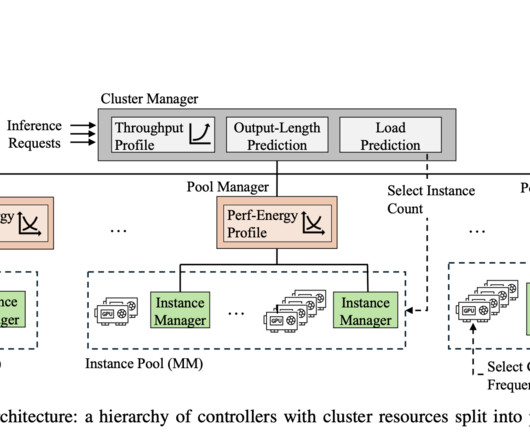
Generative Large Language Models (LLMs) have become an essential part of many applications due to their quick growth and widespread use. LLM inference clusters manage a massive stream of queries, each with strict Service Level Objectives (SLOs) that must be fulfilled to guarantee adequate performance, as these models have become more integrated into different services.
The DHS compliance audit clock is ticking on Zero Trust. Government agencies can no longer ignore or delay their Zero Trust initiatives. During this virtual panel discussion—featuring Kelly Fuller Gordon, Founder and CEO of RisX, Chris Wild, Zero Trust subject matter expert at Zermount, Inc., and Principal of Cybersecurity Practice at Eliassen Group, Trey Gannon—you’ll gain a detailed understanding of the Federal Zero Trust mandate, its requirements, milestones, and deadlines.
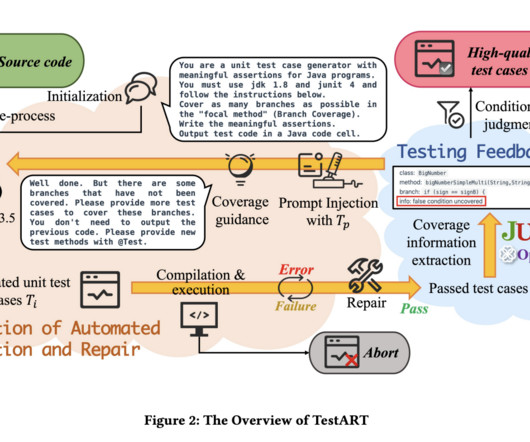
Unit testing aims to identify and resolve bugs at the earliest stages by testing individual components or units of code. This process ensures software reliability and quality before the final product is delivered. Traditional methods of unit test generation, such as search-based, constraint-based, and random-based techniques, have been utilized to automate the creation of unit tests.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content