This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Docker is a DevOps tool and is very popular in the DevOps and MLOPS world. The post A Complete Guide for Deploying ML Models in Docker appeared first on Analytics Vidhya. Introduction on Docker Docker is everywhere in the world of the software industry today.
This is both frustrating for companies that would prefer making ML an ordinary, fuss-free value-generating function like software engineering, as well as exciting for vendors who see the opportunity to create buzz around a new category of enterprise software. Can’t we just fold it into existing DevOps best practices?
This year, generative AI and machine learning (ML) will again be in focus, with exciting keynote announcements and a variety of sessions showcasing insights from AWS experts, customer stories, and hands-on experiences with AWS services. Visit the session catalog to learn about all our generative AI and ML sessions.
The solution described in this post is geared towards machine learning (ML) engineers and platform teams who are often responsible for managing and standardizing custom environments at scale across an organization. This approach helps you achieve machine learning (ML) governance, scalability, and standardization.
In world of Artificial Intelligence (AI) and Machine Learning (ML), a new professionals has emerged, bridging the gap between cutting-edge algorithms and real-world deployment. Meet the MLOps Engineer: the orchestrating the seamless integration of ML models into production environments, ensuring scalability, reliability, and efficiency.
With that, the need for data scientists and machine learning (ML) engineers has grown significantly. Data scientists and ML engineers require capable tooling and sufficient compute for their work. Data scientists and ML engineers require capable tooling and sufficient compute for their work.
In this post, we dive into how organizations can use Amazon SageMaker AI , a fully managed service that allows you to build, train, and deploy ML models at scale, and can build AI agents using CrewAI, a popular agentic framework and open source models like DeepSeek-R1. Having access to a JupyterLab IDE with Python 3.9, 3.10, or 3.11
Hence for an individual who wants to excel as a data scientist, learning Python is a must. The role of Python is not just limited to Data Science. In fact, Python finds multiple applications. It’s a universal programming language that finds application in different technologies like AI, ML, Big Data and others.
Machine learning (ML), a subset of artificial intelligence (AI), is an important piece of data-driven innovation. Today, 35% of companies report using AI in their business, which includes ML, and an additional 42% reported they are exploring AI, according to the IBM Global AI Adoption Index 2022. What is MLOps? Where they are deployed.
In this post I want to talk about using generative AI to extend one of my academic software projectsthe Python Tutor tool for learning programmingwith an AI chat tutor. Python Tutor is mainly used by students to understand and debug their homework assignment code step-by-step by seeing its call stack and data structures.
Real-world applications vary in inference requirements for their artificial intelligence and machine learning (AI/ML) solutions to optimize performance and reduce costs. SageMaker Model Monitor monitors the quality of SageMaker ML models in production. Your client applications invoke this endpoint to get inferences from the model.
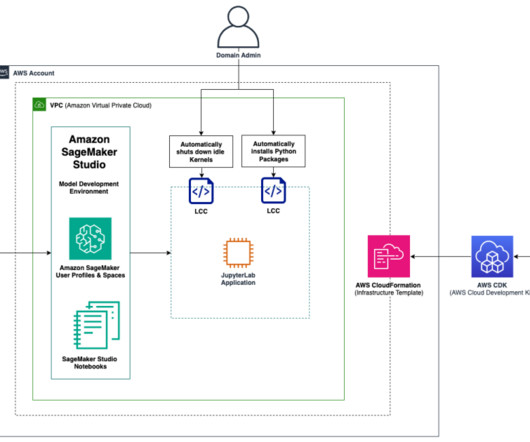
Amazon SageMaker Studio is the first integrated development environment (IDE) purposefully designed to accelerate end-to-end machine learning (ML) development. These automations can greatly decrease overhead related to ML project setup, facilitate technical consistency, and save costs related to running idle instances.
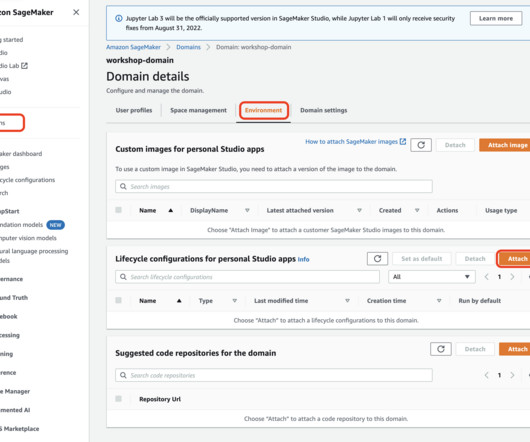
This post presents and compares options and recommended practices on how to manage Python packages and virtual environments in Amazon SageMaker Studio notebooks. Amazon SageMaker Studio is a web-based, integrated development environment (IDE) for machine learning (ML) that lets you build, train, debug, deploy, and monitor your ML models.
Its scalability and load-balancing capabilities make it ideal for handling the variable workloads typical of machine learning (ML) applications. Amazon SageMaker provides capabilities to remove the undifferentiated heavy lifting of building and deploying ML models. This entire workflow is shown in the following solution diagram.
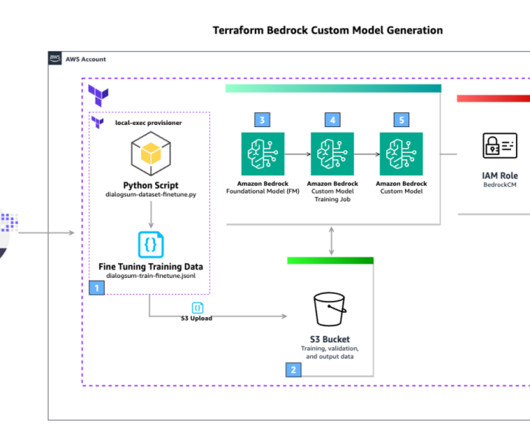
In this post, we show you how to convert Python code that fine-tunes a generative AI model in Amazon Bedrock from local files to a reusable workflow using Amazon SageMaker Pipelines decorators. You can use Amazon SageMaker Model Building Pipelines to collaborate between multiple AI/ML teams. Create and run the SageMaker pipeline.
Machine learning (ML) projects are inherently complex, involving multiple intricate steps—from data collection and preprocessing to model building, deployment, and maintenance. To start our ML project predicting the probability of readmission for diabetes patients, you need to download the Diabetes 130-US hospitals dataset.
By taking care of the undifferentiated heavy lifting, SageMaker allows you to focus on working on your machine learning (ML) models, and not worry about things such as infrastructure. Prior to working at Amazon Music, Siddharth was working at companies like Meta, Walmart Labs, Rakuten on E-Commerce centric ML Problems.
Hugging Face is an open-source machine learning (ML) platform that provides tools and resources for the development of AI projects. Prerequisites To follow along with this post, you should have the following prerequisites: Python version greater than 3.9 AWS CDK version 2.0
Right now, most deep learning frameworks are built for Python, but this neglects the large number of Java developers and developers who have existing Java code bases they want to integrate the increasingly powerful capabilities of deep learning into. Business requirements We are the US squad of the Sportradar AI department.
Artificial intelligence (AI) and machine learning (ML) are becoming an integral part of systems and processes, enabling decisions in real time, thereby driving top and bottom-line improvements across organizations. However, putting an ML model into production at scale is challenging and requires a set of best practices.
In this comprehensive guide, we’ll explore the key concepts, challenges, and best practices for ML model packaging, including the different types of packaging formats, techniques, and frameworks. These teams may include but are not limited to data scientists, software developers, machine learning engineers, and DevOps engineers.
It combines principles from DevOps, such as continuous integration, continuous delivery, and continuous monitoring, with the unique challenges of managing machine learning models and datasets. As the adoption of machine learning in various industries continues to grow, the demand for robust MLOps tools has also increased. What is MLOps?
As industries begin adopting processes dependent on machine learning (ML) technologies, it is critical to establish machine learning operations (MLOps) that scale to support growth and utilization of this technology. There were noticeable challenges when running ML workflows in the cloud.
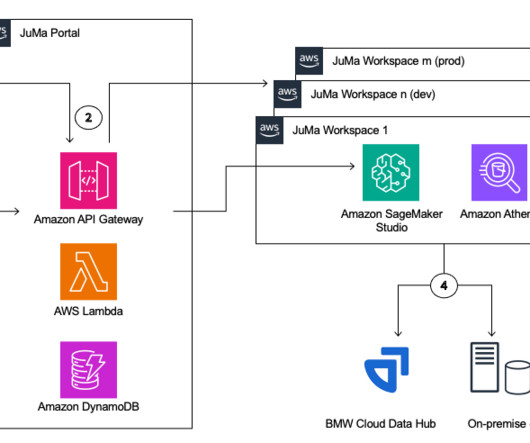
The solution uses AWS AI and machine learning (AI/ML) services, including Amazon Transcribe , Amazon SageMaker , Amazon Bedrock , and FMs. API Gateway instantiates an AWS Step Functions The state machine orchestrates the AI/ML services Amazon Transcribe and Amazon Bedrock and the NoSQL data store Amazon DynamoDB using AWS Lambda functions.
The Falcon 2 11B model is available on SageMaker JumpStart, a machine learning (ML) hub that provides access to built-in algorithms, FMs, and pre-built ML solutions that you can deploy quickly and get started with ML faster. strip() print(response) The code uses Falcon 2 11B to generate a Python function that writes a JSON file.
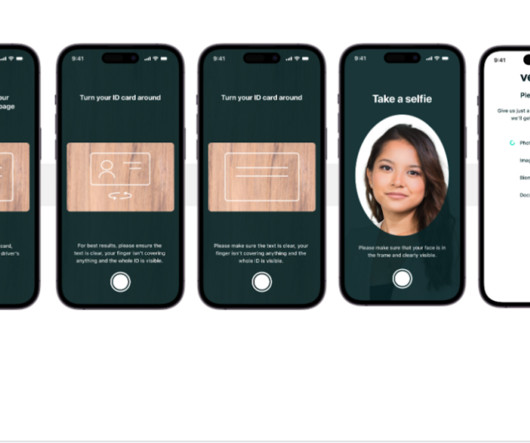
As an AI-powered solution, Veriff needs to create and run dozens of machine learning (ML) models in a cost-effective way. This approach was initially used for all company services, including microservices that run expensive computer vision ML models. Some of these models required deployment on GPU instances.
When machine learning (ML) models are deployed into production and employed to drive business decisions, the challenge often lies in the operation and management of multiple models. That is where Provectus , an AWS Premier Consulting Partner with competencies in Machine Learning, Data & Analytics, and DevOps, stepped in.
This post, part of the Governing the ML lifecycle at scale series ( Part 1 , Part 2 , Part 3 ), explains how to set up and govern a multi-account ML platform that addresses these challenges. An enterprise might have the following roles involved in the ML lifecycles. This ML platform provides several key benefits.
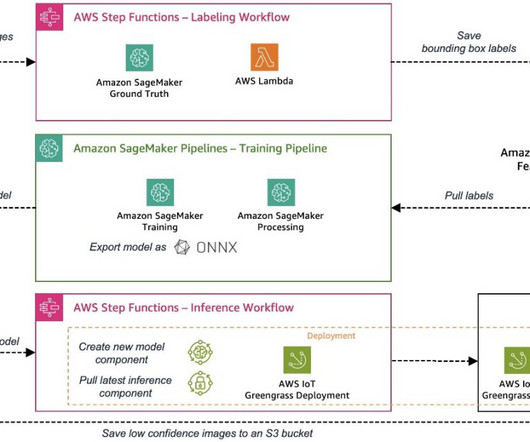
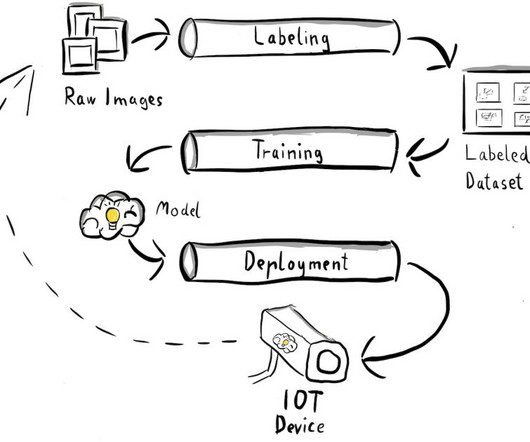
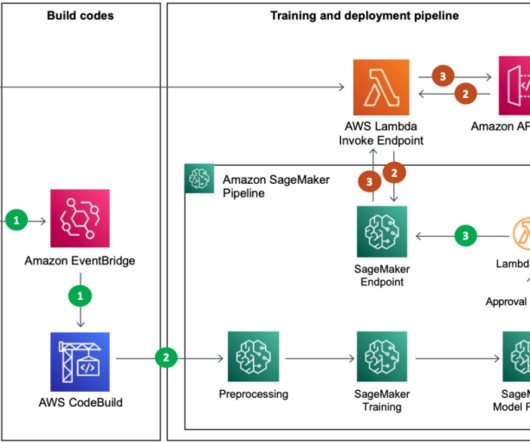
Solution overview In Part 1 of this series, we laid out an architecture for our end-to-end MLOps pipeline that automates the entire machine learning (ML) process, from data labeling to model training and deployment at the edge. In Part 2 , we showed how to automate the labeling and model training parts of the pipeline.
A successful deployment of a machine learning (ML) model in a production environment heavily relies on an end-to-end ML pipeline. Although developing such a pipeline can be challenging, it becomes even more complex when dealing with an edge ML use case. This helps avoid costly defects at later stages of the production process.
Amazon SageMaker Studio is the first fully integrated development environment (IDE) for machine learning (ML). Studio provides a single web-based visual interface where you can perform all ML development steps required to prepare data, as well as build, train, and deploy models. For more information, refer to Working with the AWS CDK.
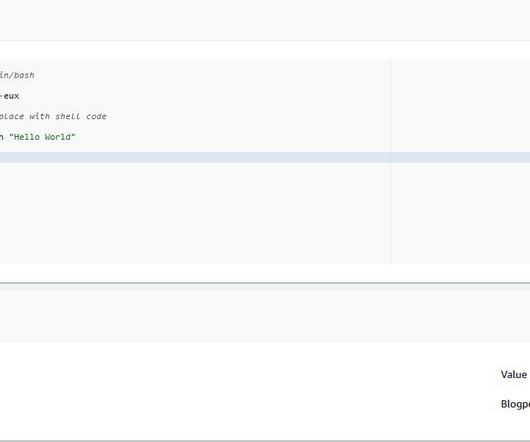
The workflow includes the following steps: The user runs the terraform apply The Terraform local-exec provisioner is used to run a Python script that downloads the public dataset DialogSum from the Hugging Face Hub. Configure your local Python virtual environment. python v3.8 Upload the converted dataset to Amazon S3.
To achieve this effectively, Aviva harnesses the power of machine learning (ML) across more than 70 use cases. Previously, ML models at Aviva were developed using a graphical UI-driven tool and deployed manually. Therefore, developing and deploying more ML models is crucial to support their growing workload.
Knowledge and skills in the organization Evaluate the level of expertise and experience of your ML team and choose a tool that matches their skill set and learning curve. For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc.,
The Coursera class is direct to the point and gives concrete instructions about how to use the Azure Portal interface, Databricks, and the Python SDK; if you know nothing about Azure and need to use the service platform right away I highly recommend this course. Be sure to create an Environment for the ML workspace.
Data scientists and machine learning (ML) engineers use pipelines for tasks such as continuous fine-tuning of large language models (LLMs) and scheduled notebook job workflows. Create a complete AI/ML pipeline for fine-tuning an LLM using drag-and-drop functionality. In this example, you will use a Python function.
The MLOps Process We can see some of the differences with MLOps which is a set of methods and techniques to deploy and maintain machine learning (ML) models in production reliably and efficiently. MLOps is the intersection of Machine Learning, DevOps, and Data Engineering. Norvig, Artificial Intelligence: A Modern Approach, 4th ed.
Machine learning (ML) models do not operate in isolation. To deliver value, they must integrate into existing production systems and infrastructure, which necessitates considering the entire ML lifecycle during design and development. GitHub serves as a centralized location to store, version, and manage your ML code base.
It is architected to automate the entire machine learning (ML) process, from data labeling to model training and deployment at the edge. The quality of our labels will affect the quality of our ML model. This three-step process is generic and can be used for any model architecture and ML framework of your choice.
This article was originally an episode of the ML Platform Podcast , a show where Piotr Niedźwiedź and Aurimas Griciūnas, together with ML platform professionals, discuss design choices, best practices, example tool stacks, and real-world learnings from some of the best ML platform professionals. Stefan: Yeah.
It provides a collection of pre-trained models that you can deploy quickly, accelerating the development and deployment of ML applications. One of the key components of SageMaker JumpStart is model hubs, which offer a vast catalog of pre-trained models, such as Mistral, for a variety of tasks.
This article was originally an episode of the ML Platform Podcast , a show where Piotr Niedźwiedź and Aurimas Griciūnas, together with ML platform professionals, discuss design choices, best practices, example tool stacks, and real-world learnings from some of the best ML platform professionals.
TL;DR This series explain how to implement intermediate MLOps with simple python code, without introducing MLOps frameworks (MLflow, DVC …). My interpretation to MLOps is similar to my interpretation of DevOps. As an ML engineer you’re in charge of some code/model. Replace MLOps with program .Source Why is this a requirement?
SageMaker pipeline for training SageMaker Pipelines helps you define the steps required for ML services, such as preprocessing, training, and deployment, using the SDK. Make sure to enter the same PyTorch framework, Python version, and other details that you used to train the model. Provide the inference.py
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content