This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This is both frustrating for companies that would prefer making ML an ordinary, fuss-free value-generating function like software engineering, as well as exciting for vendors who see the opportunity to create buzz around a new category of enterprise software. Can’t we just fold it into existing DevOps best practices?
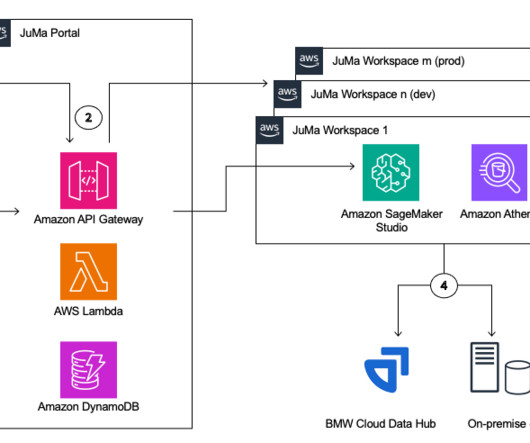
The solution described in this post is geared towards machine learning (ML) engineers and platform teams who are often responsible for managing and standardizing custom environments at scale across an organization. This approach helps you achieve machine learning (ML) governance, scalability, and standardization.
Understanding MLOps Before delving into the intricacies of becoming an MLOps Engineer, it's crucial to understand the concept of MLOps itself. Essential Skills for Becoming an MLOps Engineer To thrive as an MLOps Engineer, you'll need to cultivate a diverse set of skills spanning multiple domains.
Hence for an individual who wants to excel as a data scientist, learning Python is a must. The role of Python is not just limited to Data Science. In fact, Python finds multiple applications. It’s a universal programming language that finds application in different technologies like AI, ML, Big Data and others.
Because ML systems require significant resources and hands-on time from often disparate teams, problems arose from lack of collaboration and simple misunderstandings between data scientists and IT teams about how to build out the best process. How to use ML to automate the refining process into a cyclical ML process.
Its scalability and load-balancing capabilities make it ideal for handling the variable workloads typical of machine learning (ML) applications. In this post, we introduce an example to help DevOpsengineers manage the entire ML lifecycle—including training and inference—using the same toolkit.
With that, the need for data scientists and machine learning (ML) engineers has grown significantly. Data scientists and MLengineers require capable tooling and sufficient compute for their work. It is powered by Amazon SageMaker Studio and provides JupyterLab for Python and Posit Workbench for R.
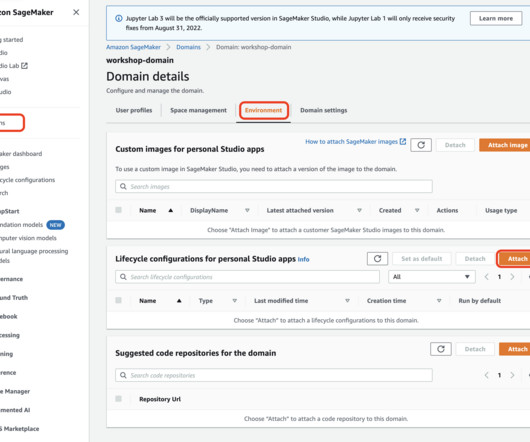
This post presents and compares options and recommended practices on how to manage Python packages and virtual environments in Amazon SageMaker Studio notebooks. Amazon SageMaker Studio is a web-based, integrated development environment (IDE) for machine learning (ML) that lets you build, train, debug, deploy, and monitor your ML models.
Many businesses already have data scientists and MLengineers who can build state-of-the-art models, but taking models to production and maintaining the models at scale remains a challenge. Machine learning operations (MLOps) applies DevOps principles to ML systems.
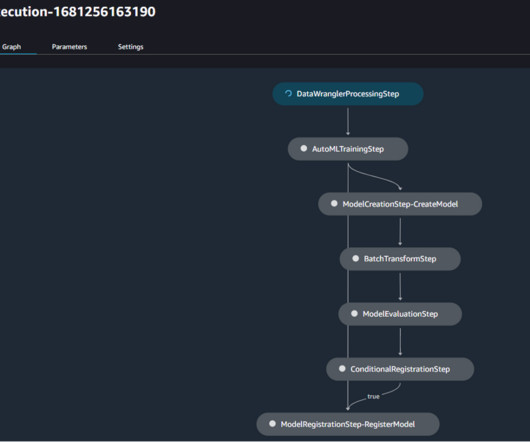
TWCo data scientists and MLengineers took advantage of automation, detailed experiment tracking, integrated training, and deployment pipelines to help scale MLOps effectively. ML model experimentation is one of the sub-components of the MLOps architecture. For this proof of concept, pipelines were set up using this SDK.
Create a SageMaker Model Monitor schedule Next, you use the Amazon SageMaker Python SDK to create a model monitoring schedule. You can use this framework as a starting point to monitor your custom metrics or handle other unique requirements for model quality monitoring in your AI/ML applications. About the Authors Joe King is a Sr.
In this post, we show you how to convert Python code that fine-tunes a generative AI model in Amazon Bedrock from local files to a reusable workflow using Amazon SageMaker Pipelines decorators. You can use Amazon SageMaker Model Building Pipelines to collaborate between multiple AI/ML teams. We use Python to do this.
They needed a cloud platform and a strategic partner with proven expertise in delivering production-ready AI/ML solutions, to quickly bring EarthSnap to the market. That is where Provectus , an AWS Premier Consulting Partner with competencies in Machine Learning, Data & Analytics, and DevOps, stepped in.
Data scientists and machine learning (ML) engineers use pipelines for tasks such as continuous fine-tuning of large language models (LLMs) and scheduled notebook job workflows. In this example, you will use a Python function. Download the complete Python file , including the function and all imported libraries.
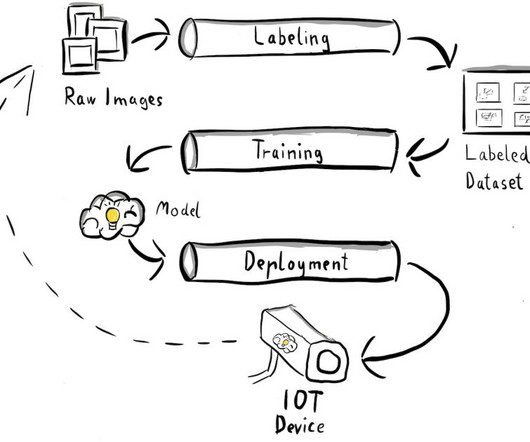
Use case: Inspecting the quality of metal tags As an MLengineer, it’s important to understand the business case you are working on. In this example, we’re using the Ultralytics YOLOv8 Python package and model architecture to train and export an object detection model to the ONNX ML model format for portability.
TL;DR This series explain how to implement intermediate MLOps with simple python code, without introducing MLOps frameworks (MLflow, DVC …). My interpretation to MLOps is similar to my interpretation of DevOps. As a software engineer your role is to write code for a certain cause. Replace MLOps with program .Source
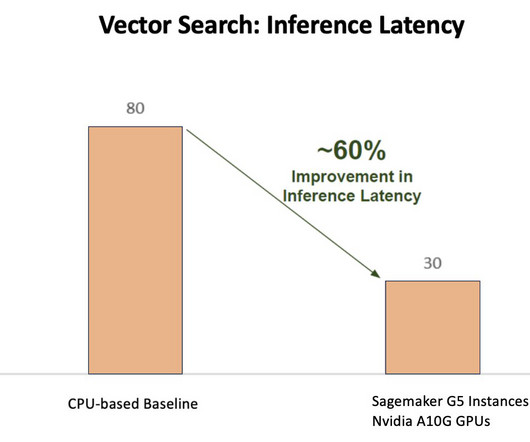
NVIDIA Triton Inference Server provides two different kind backends: one for hosting models on GPU, and a Python backend where you can bring your own custom code to be used in preprocessing and postprocessing steps. This includes overheads like load balancing, preprocessing, model inferencing, and postprocessing times.
ML operations, known as MLOps, focus on streamlining, automating, and monitoring ML models throughout their lifecycle. Data scientists, MLengineers, IT staff, and DevOps teams must work together to operationalize models from research to deployment and maintenance.
Throughout this exercise, you use Amazon Q Developer in SageMaker Studio for various stages of the development lifecycle and experience firsthand how this natural language assistant can help even the most experienced data scientists or MLengineers streamline the development process and accelerate time-to-value.
MLengineers Develop model deployment pipelines and control the model deployment processes. MLengineers create the pipelines in Github repositories, and the platform engineer converts them into two different Service Catalog portfolios: ML Admin Portfolio and SageMaker Project Portfolio.
Knowledge and skills in the organization Evaluate the level of expertise and experience of your ML team and choose a tool that matches their skill set and learning curve. For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc.,
Machine Learning Operations (MLOps) can significantly accelerate how data scientists and MLengineers meet organizational needs. A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team.
This situation is not different in the ML world. Data Scientists and MLEngineers typically write lots and lots of code. Related post MLOps Is an Extension of DevOps. These combinations of Python code and SQL play a crucial role but can be challenging to keep them robust for their entire lifetime. Aside neptune.ai
She is passionate about developing, deploying, and explaining AI/ ML solutions across various domains. Prior to this role, she led multiple initiatives as a data scientist and MLengineer with top global firms in the financial and retail space. Saswata Dash is a DevOps Consultant with AWS Professional Services.
This is your Custom Python Hook speaking!" Ryan Gomes is a Data & MLEngineer with the AWS Professional Services Intelligence Practice. Solutions Architect at Amazon Web Services with specialization in DevOps and Observability. He leads the NYC machine learning and AI meetup. Mahesh Birardar is a Sr.
MLflow is an open-source platform designed to manage the entire machine learning lifecycle, making it easier for MLEngineers, Data Scientists, Software Developers, and everyone involved in the process. MLflow can be seen as a tool that fits within the MLOps (synonymous with DevOps) framework.
This is Piotr Niedźwiedź and Aurimas Griciūnas from neptune.ai , and you’re listening to ML Platform Podcast. Stefan is a software engineer, data scientist, and has been doing work as an MLengineer. You could almost think of Hamilton as DBT for Python functions. Piotr: This is procedural Python code.
How did you manage to jump from a more analytical, scientific type of role to a more engineering one? I actually did not pick up Python until about a year before I made the transition to a data scientist role. I switched from analytics to data science, then to machine learning, then to data engineering, then to MLOps.
Amazon SageMaker is a fully managed service to prepare data and build, train, and deploy machine learning (ML) models for any use case with fully managed infrastructure, tools, and workflows. You can also add your own Python scripts and transformations to customize workflows. Python code file.
One of the most prevalent complaints we hear from MLengineers in the community is how costly and error-prone it is to manually go through the ML workflow of building and deploying models. Building end-to-end machine learning pipelines lets MLengineers build once, rerun, and reuse many times.
As the number of ML-powered apps and services grows, it gets overwhelming for data scientists and MLengineers to build and deploy models at scale. In this comprehensive guide, we’ll explore everything you need to know about machine learning platforms, including: Components that make up an ML platform.
Data scientists collaborate with MLengineers to transition code from notebooks to repositories, creating ML pipelines using Amazon SageMaker Pipelines, which connect various processing steps and tasks, including pre-processing, training, evaluation, and post-processing, all while continually incorporating new production data. .
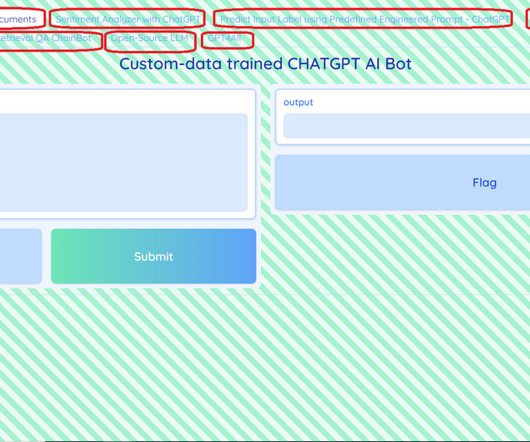
An open-source, low-code Python wrapper for easy usage of the Large Language Models such as ChatGPT, AutoGPT, LLaMa, GPT-J, and GPT4All An introduction to “ pychatgpt_gui” — A GUI-based APP for LLM’s with custom-data training and pre-trained inferences. It is an open-source python package. The launched APP snapshot is as seen below.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content