This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The use of multiple external cloud providers complicated DevOps, support, and budgeting. This includes file type verification, size validation, and metadata extraction before routing to Amazon Textract. Each processed document maintains references to its source file, extraction timestamp, and processing metadata.
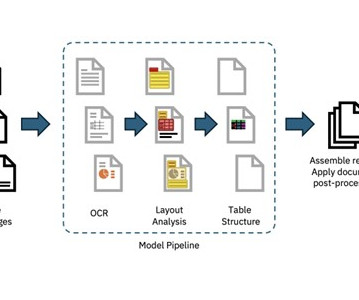
Solving this for traditional NLP problems or retrieval systems, or extracting knowledge from the documents to train models, continues to be challenging. The richness of the metadata and layout that docling captured as a structured output when processing a document sets it apart.
Voice-based queries use natural language processing (NLP) and sentiment analysis for speech recognition so their conversations can begin immediately. With text to speech and NLP, AI can respond immediately to texted queries and instructions. Humanize HR AI can attract, develop and retain a skills-first workforce.
Amazon Comprehend is a fully managed and continuously trained natural language processing (NLP) service that can extract insight about the content of a document or text. Furthermore, metadata being redacted is being reported back to the business through an Elasticsearch dashboard, enabling alerts and further action.
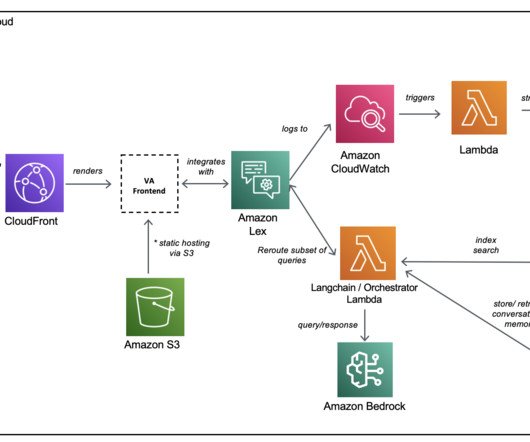
Each request/response interaction is facilitated by the AWS SDK and sends network traffic to Amazon Lex (the NLP component of the bot). Metadata about the request/response pairings are logged to Amazon CloudWatch. The CloudWatch log group is configured with a subscription filter that sends logs into Amazon OpenSearch Service.
They have deep end-to-end ML and natural language processing (NLP) expertise and data science skills, and massive data labeler and editor teams. Therefore, DevOps and AppDevs (application developers on the cloud) personas need to follow best development practices to implement the functionality of input/output and rating.
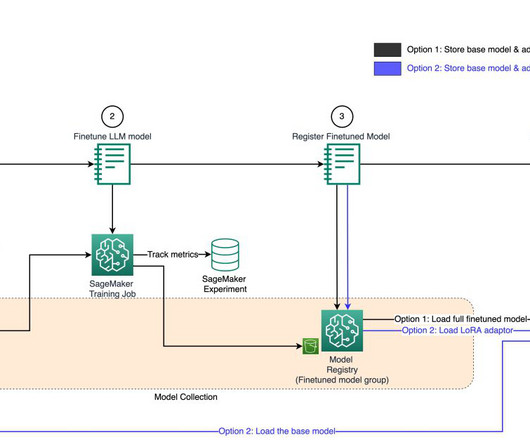
Source Model packaging is a process that involves packaging model artifacts, dependencies, configuration files, and metadata into a single format for effortless distribution, installation, and reuse. These teams may include but are not limited to data scientists, software developers, machine learning engineers, and DevOps engineers.
LLMs, like Llama2, have shown state-of-the-art performance on natural language processing (NLP) tasks when fine-tuned on domain-specific data. He previously worked in the semiconductor industry developing large computer vision (CV) and natural language processing (NLP) models to improve semiconductor processes.
It performs well on various natural language processing (NLP) tasks, including text generation. A session stores metadata and application-specific data known as session attributes. Solutions Architect at Amazon Web Services with specialization in DevOps and Observability. This enables you to begin machine learning (ML) quickly.
For me, it was a little bit of a longer journey because I kind of had data engineering and cloud engineering and DevOps engineering in between. There’s no component that stores metadata about this feature store? Mikiko Bazeley: In the case of the literal feature store, all it does is store features and metadata.
When the job is finished, you can remove the Helm chart: helm uninstall download-gpt3-pile You can see the downloaded the data in the /fsx-shared folder by running in one of the pods as kubectl exec -it nlp-worker-0 bash. Training Now that our data preparation is complete, we’re ready to train our model with the created dataset.
To make that possible, your data scientists would need to store enough details about the environment the model was created in and the related metadata so that the model could be recreated with the same or similar outcomes. Collaboration The principles you have learned in this guide are mostly born out of DevOps principles.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content