This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This post is part of an ongoing series about governing the machine learning (ML) lifecycle at scale. The data mesh architecture aims to increase the return on investments in data teams, processes, and technology, ultimately driving business value through innovative analytics and ML projects across the enterprise.
This enables the efficient processing of content, including scientific formulas and data visualizations, and the population of Amazon Bedrock Knowledge Bases with appropriate metadata. JupyterLab applications flexible and extensive interface can be used to configure and arrange machine learning (ML) workflows.
Real-world applications vary in inference requirements for their artificial intelligence and machine learning (AI/ML) solutions to optimize performance and reduce costs. SageMaker Model Monitor monitors the quality of SageMaker ML models in production. Your client applications invoke this endpoint to get inferences from the model.
The use of multiple external cloud providers complicated DevOps, support, and budgeting. This includes file type verification, size validation, and metadata extraction before routing to Amazon Textract. Each processed document maintains references to its source file, extraction timestamp, and processing metadata.
Emerging technologies and trends, such as machine learning (ML), artificial intelligence (AI), automation and generative AI (gen AI), all rely on good data quality. Proactive change management Proactive change management involves the strategies organizations use to manage changes in reference data, master data and metadata.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. Recent developments in generative AI models have further sped up the need of ML adoption across industries.
Lived through the DevOps revolution. Came to ML from software. Founded neptune.ai , a modular MLOps component for MLmetadata store , aka “experiment tracker + model registry”. Most of our customers are doing ML/MLOps at a reasonable scale, NOT at the hyperscale of big-tech FAANG companies. Ok, let me explain.
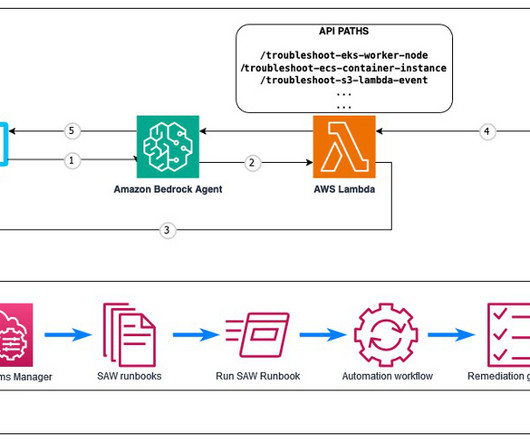
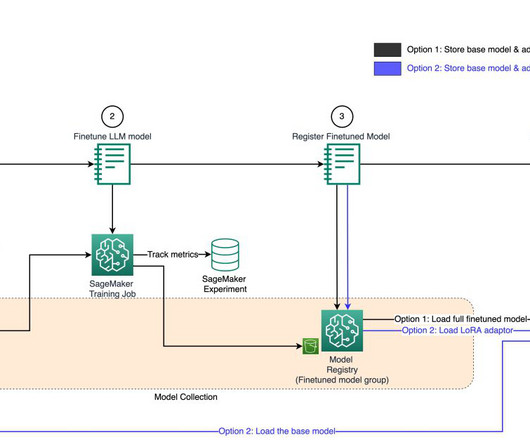
Its scalability and load-balancing capabilities make it ideal for handling the variable workloads typical of machine learning (ML) applications. Amazon SageMaker provides capabilities to remove the undifferentiated heavy lifting of building and deploying ML models. This entire workflow is shown in the following solution diagram.
You can use Amazon SageMaker Model Building Pipelines to collaborate between multiple AI/ML teams. SageMaker Pipelines You can use SageMaker Pipelines to define and orchestrate the various steps involved in the ML lifecycle, such as data preprocessing, model training, evaluation, and deployment.
Using machine learning (ML), AI can understand what customers are saying as well as their tone—and can direct them to customer service agents when needed. When someone asks a question via speech or text, ML searches for the answer or recalls similar questions the person has asked before.
Knowledge and skills in the organization Evaluate the level of expertise and experience of your ML team and choose a tool that matches their skill set and learning curve. Model monitoring and performance tracking : Platforms should include capabilities to monitor and track the performance of deployed ML models in real-time.
In this comprehensive guide, we’ll explore the key concepts, challenges, and best practices for ML model packaging, including the different types of packaging formats, techniques, and frameworks. These teams may include but are not limited to data scientists, software developers, machine learning engineers, and DevOps engineers.
Artificial intelligence (AI) and machine learning (ML) are becoming an integral part of systems and processes, enabling decisions in real time, thereby driving top and bottom-line improvements across organizations. However, putting an ML model into production at scale is challenging and requires a set of best practices.
When machine learning (ML) models are deployed into production and employed to drive business decisions, the challenge often lies in the operation and management of multiple models. That is where Provectus , an AWS Premier Consulting Partner with competencies in Machine Learning, Data & Analytics, and DevOps, stepped in.
IDC 2 predicts that by 2024, 60% of enterprises would have operationalized their ML workflows by using MLOps. The same is true for your ML workflows – you need the ability to navigate change and make strong business decisions. 1 IDC, MLOps – Where ML Meets DevOps, doc #US48544922, March 2022. Request a Demo.
The Annotated type is used to provide additional metadata about the return value, specifically that it should be included in the response body. He enjoys learning about AWS AI/ML services and helping customers meet their business outcomes by building solutions for them.
It combines principles from DevOps, such as continuous integration, continuous delivery, and continuous monitoring, with the unique challenges of managing machine learning models and datasets. As the adoption of machine learning in various industries continues to grow, the demand for robust MLOps tools has also increased. What is MLOps?
DevSecOps includes all the characteristics of DevOps, such as faster deployment, automated pipelines for build and deployment, extensive testing, etc., Source Purpose of Using DevSecOps in Traditional and ML Applications The DevSecOps practices are different in traditional and ML applications as each comes with different challenges.
Most cybersecurity tools leverage machine learning (ML) models that present several shortcomings to security teams when it comes to preventing threats. ML solutions also require heavy human intervention and are trained on small data sets, exposing them to human bias and error. Like other AI and ML models, our model trains on data.
Why model-driven AI falls short of delivering value Teams that just focus model performance using model-centric and data-centric ML risk missing the big picture business context. DataRobot AI Platform release we’ve broken down the barriers that exist across the ML lifecycle. What Do AI Teams Need to Realize Value from AI?
The engineering team was able to build and test the solution within a week, without needing to understand machine learning (ML) or the working of AI, using Amazon Comprehend video guidance , API reference documentation , and example code. It enforces the policy of not having PII stored in logs, thereby reducing risk and improving compliance.
ML operationalization summary As defined in the post MLOps foundation roadmap for enterprises with Amazon SageMaker , ML and operations (MLOps) is the combination of people, processes, and technology to productionize machine learning (ML) solutions efficiently.
It is architected to automate the entire machine learning (ML) process, from data labeling to model training and deployment at the edge. The quality of our labels will affect the quality of our ML model. The output of a SageMaker Ground Truth labeling job is a file in JSON-lines format containing the labels and additional metadata.
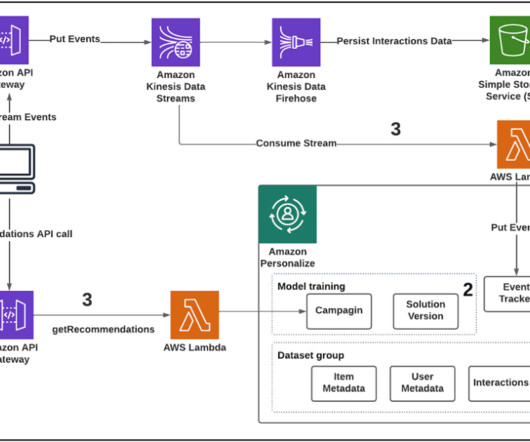
At a basic level, Machine Learning (ML) technology learns from data to make predictions. Businesses use their data with an ML-powered personalization service to elevate their customer experience. Amazon Personalize enables developers to quickly implement a customized personalization engine, without requiring ML expertise.
Machine learning (ML) models do not operate in isolation. To deliver value, they must integrate into existing production systems and infrastructure, which necessitates considering the entire ML lifecycle during design and development. GitHub serves as a centralized location to store, version, and manage your ML code base.
The last attribute, Churn , is the attribute that we want the ML model to predict. model.create() creates a model entity, which will be included in the custom metadata registered for this model version and later used in the second pipeline for batch inference and model monitoring. large", accelerator_type="ml.eia1.medium",
This allows machine learning (ML) practitioners to rapidly launch an Amazon Elastic Compute Cloud (Amazon EC2) instance with a ready-to-use deep learning environment, without having to spend time manually installing and configuring the required packages. You also need the ML job scripts ready with a command to invoke them.
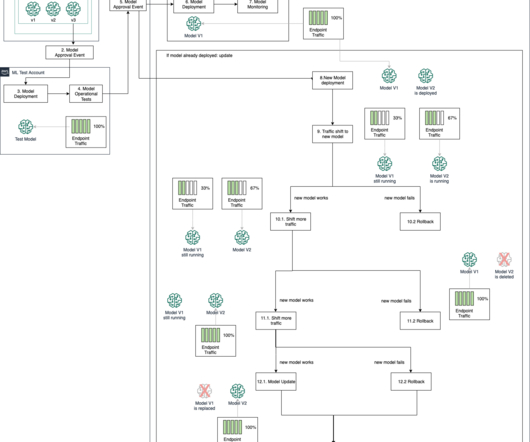
As Artificial Intelligence (AI) and Machine Learning (ML) technologies have become mainstream, many enterprises have been successful in building critical business applications powered by ML models at scale in production. They provide a fact sheet of the model that is important for model governance.
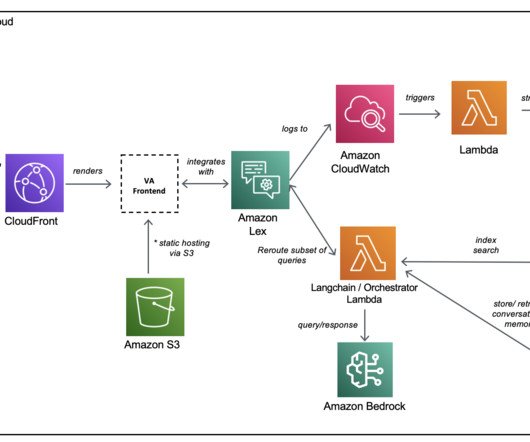
As it fields more queries, the system continuously improves its language processing through machine learning (ML) algorithms. Metadata about the request/response pairings are logged to Amazon CloudWatch. Shikhar Kwatra is an AI/ML specialist solutions architect at Amazon Web Services, working with a leading Global System Integrator.
The examples focus on questions on chunk-wise business knowledge while ignoring irrelevant metadata that might be contained in a chunk. He has touched on most aspects of these projects, from infrastructure and DevOps to software development and AI/ML. You can customize the prompt examples to fit your ground truth use case.
You can visualize the indexed metadata using OpenSearch Dashboards. Intelligent index and search With the OpenSearchPushInvoke Lambda function, the extracted expense metadata is pushed to an OpenSearch Service index and is available for search. His interests and experience include containers, serverless technology, and DevOps.
This article was originally an episode of the ML Platform Podcast , a show where Piotr Niedźwiedź and Aurimas Griciūnas, together with ML platform professionals, discuss design choices, best practices, example tool stacks, and real-world learnings from some of the best ML platform professionals. How do I develop my body of work?
This article was originally an episode of the ML Platform Podcast , a show where Piotr Niedźwiedź and Aurimas Griciūnas, together with ML platform professionals, discuss design choices, best practices, example tool stacks, and real-world learnings from some of the best ML platform professionals. Stefan: Yeah.
The metadata store is where MLflow keeps the experiment and model metadata. In my experience, even solo data scientists prefer setting up a tracking server rather than directly interfacing with metadata and artifact stores. After all, it exposes the UI, collects the metadata, and provides access to the model artifacts.
After you build, train, and evaluate your machine learning (ML) model to ensure it’s solving the intended business problem proposed, you want to deploy that model to enable decision-making in business operations. SageMaker Training jobs are then used to train an ML model on the data produced by the processing job.
Experiments plus callback integration Amazon SageMaker Experiments lets you organize, track, compare and evaluate machine learning (ML) experiments and model versions from any integrated development environment (IDE), including local Jupyter Notebooks, using the SageMaker Python SDK or boto3.
The workflow to create the training container consists of the following services: SageMaker uses Docker containers throughout the ML lifecycle. When the training process is complete, the output model that resides in the /opt/ml/model directory is automatically uploaded to the S3 bucket specified in the training job configuration.
Data versioning solutions are essential for your workflow if you are concerned about repeatability, traceability, and the history of ML models. This data version is frequently recorded into your metadata management solution to ensure that your model training is versioned and repeatable. Using Delta makes upserts straightforward.
As an MLOps engineer on your team, you are often tasked with improving the workflow of your data scientists by adding capabilities to your ML platform or by building standalone tools for them to use. Giving your data scientists a platform to track the progress of their ML projects. Experiment tracking is one such capability.
MLflow is an open-source platform designed to manage the entire machine learning lifecycle, making it easier for ML Engineers, Data Scientists, Software Developers, and everyone involved in the process. MLflow can be seen as a tool that fits within the MLOps (synonymous with DevOps) framework. To learn more, book a demo.
This enables you to begin machine learning (ML) quickly. A SageMaker real-time inference endpoint enables fast, scalable deployment of ML models for predicting events. A session stores metadata and application-specific data known as session attributes. A session persists over time unless manually stopped or timed out.
As Artificial Intelligence (AI) and Machine Learning (ML) technologies have become mainstream, many enterprises have been successful in building critical business applications powered by ML models at scale in production. They provide a fact sheet of the model that is important for model governance.
And because it takes more than technologies and processes to succeed with MLOps, he will also share details on: 1 Brainly’s ML use cases, 2 MLOps culture, 3 Team structure, 4 And technologies Brainly uses to deliver AI services to its clients, Enjoy the article! quality attributes) and metadata enrichment (e.g.,
One of the most prevalent complaints we hear from ML engineers in the community is how costly and error-prone it is to manually go through the ML workflow of building and deploying models. Building end-to-end machine learning pipelines lets ML engineers build once, rerun, and reuse many times. If all goes well, of course ?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content