This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These agents perform tasks ranging from customer support to softwareengineering, navigating intricate workflows that combine reasoning, tool use, and memory. This is where AgentOps comes in; a concept modeled after DevOps and MLOps but tailored for managing the lifecycle of FM-based agents. What is AgentOps?
In softwareengineering, there is a direct correlation between team performance and building robust, stable applications. Mainframe teams using BMC’s Git-based DevOps platform, AMI DevX ,can collect this data as easily as distributed teams can. Using a Git-based SCM pulls these insight together seamlessly.
DeepSeek-R1 is an advanced LLM developed by the AI startup DeepSeek. Simplified LLM hosting on SageMaker AI Before orchestrating agentic workflows with CrewAI powered by an LLM, the first step is to host and query an LLM using SageMaker real-time inference endpoints.
The use of multiple external cloud providers complicated DevOps, support, and budgeting. With this LLM, CreditAI was now able to respond better to broader, industry-wide queries than before. Anthropic Claude LLM performs the natural language processing, generating responses that are then returned to the web application.
After closely observing the softwareengineering landscape for 23 years and engaging in recent conversations with colleagues, I can’t help but feel that a specialized Large Language Model (LLM) is poised to power the following programming language revolution.
The rapid evolution of AI is transforming nearly every industry/domain, and softwareengineering is no exception. But how so with softwareengineering you may ask? These technologies are helping engineers accelerate development, improve software quality, and streamline processes, just to name a few.
To scale ground truth generation and curation, you can apply a risk-based approach in conjunction with a prompt-based strategy using LLMs. Its important to note that LLM-generated ground truth isnt a substitute for use case SME involvement. To convert the source document excerpt into ground truth, we provide a base LLM prompt template.
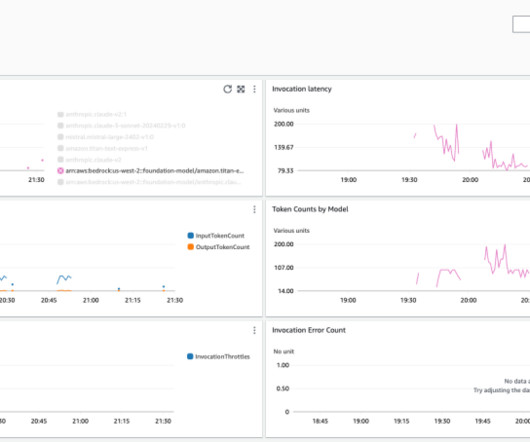
For example, you can write a Logs Insights query to calculate the token usage of the various applications and users calling the large language model (LLM). Attributing LLM usage to specific users or applications. He focuses on monitoring and operationalizing cloud and LLM workloads in CloudWatch for AWS customers.
Create a complete AI/ML pipeline for fine-tuning an LLM using drag-and-drop functionality. Llama fine-tuning pipeline overview In this post, we will show you how to set up an automated LLM customization (fine-tuning) workflow so that the Llama 3.x But fine-tuning an LLM just once isn’t enough.
It combines principles from DevOps, such as continuous integration, continuous delivery, and continuous monitoring, with the unique challenges of managing machine learning models and datasets. Especially in the current time when large language models (LLMs) are making their way for several industry-based generative AI projects.
Furthermore, the cost to train new LLMs can prove prohibitive for many enterprise settings. However, it’s possible to cross-reference a model answer with the original specialized content, thereby avoiding the need to train a new LLM model, using Retrieval-Augmented Generation (RAG). We have provided this demo in the GitHub repo.
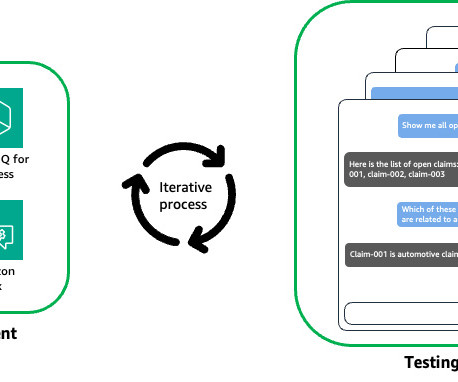
Although existing large language model (LLM) benchmarks like MT-bench evaluate model capabilities, they lack the ability to validate the application layers. The framework implements an LLM agent (evaluator) that will orchestrate conversations with your own agent (target) and evaluate the responses during the conversation.
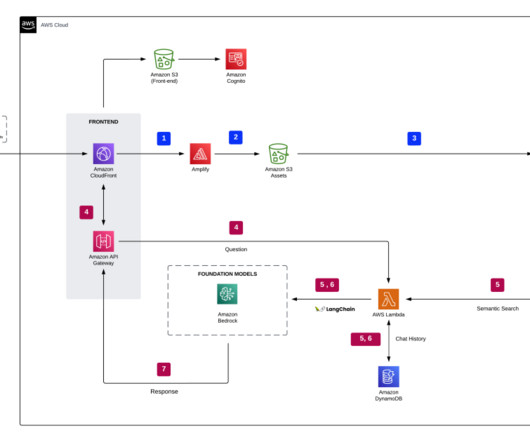
Overview of RAG The RAG pattern lets you retrieve knowledge from external sources, such as PDF documents, wiki articles, or call transcripts, and then use that knowledge to augment the instruction prompt sent to the LLM. This allows the LLM to reference more relevant information when generating a response.
My interpretation to MLOps is similar to my interpretation of DevOps. As a softwareengineer your role is to write code for a certain cause. DevOps cover all of the rest, like deployment, scheduling of automatic tests on code change, scaling machines to demanding load, cloud permissions, db configuration and much more.
This article by Samhita Alla, a softwareengineer and tech evangelist at Union.ai, provides a simplified walkthrough of the applications of Flyte in MLOps. LLM training configurations. Guardrails: – Does pydantic-style validation of LLM outputs. Check out the documentation to get started.
NVIDIA NIM m icroservices now integrate with Amazon SageMaker , allowing you to deploy industry-leading large language models (LLMs) and optimize model performance and cost. NIM also plans to have LLM support by supporting Triton Inference Server, TensorRT-LLM, and vLLM backends.
Game changer ChatGPT in SoftwareEngineering: A Glimpse Into the Future | HackerNoon Generative AI for DevOps: A Practical View - DZone ChatGPT for DevOps: Best Practices, Use Cases, and Warnings. The article has good points with any LLM Use prompt to guide. ChatGPT codes like an expert beginner.
One of the hardest things about MLOps today is that a lot of data scientists aren’t native softwareengineers, but it may be possible to lower the bar to softwareengineering. Learning softwareengineering best practices and understanding how ML systems get built and productionized. Stephen : Awesome.
With a vision to build a large language model (LLM) trained on Italian data, Fastweb embarked on a journey to make this powerful AI capability available to third parties. The computational cost of training an LLM The computational cost of training LLMs scales approximately with the number of parameters and the amount of training data.
Ravi Sharma is a Senior SoftwareEngineer at Zalando’s Pricing Platform, bringing experience across diverse domains such as football betting, radio astronomy, healthcare, and ecommerce. His work encompasses the development of business-relevant and scalable forecasting models, stretching from prototyping to deployment.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content