This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This is where AgentOps comes in; a concept modeled after DevOps and MLOps but tailored for managing the lifecycle of FM-based agents. That said, AgentOps (the tool) offers developers insight into agent workflows with features like session replays, LLM cost tracking, and compliance monitoring. What is AgentOps?
The use of multiple external cloud providers complicated DevOps, support, and budgeting. With this LLM, CreditAI was now able to respond better to broader, industry-wide queries than before. This includes file type verification, size validation, and metadata extraction before routing to Amazon Textract.
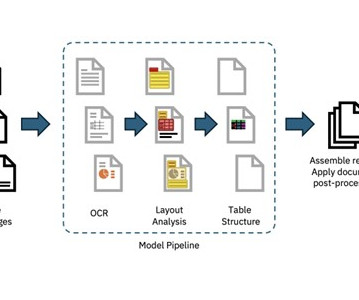
Each text, including the rotated text on the left of the page, is identified and extracted as a stand-alone text element with coordinates and other metadata that makes it possible to render a document very close to the original PDF but from a structured JSONformat.
It automatically keeps track of model artifacts, hyperparameters, and metadata, helping you to reproduce and audit model versions. As you move from pilot and test phases to deploying generative AI models at scale, you will need to apply DevOps practices to ML workloads. We use Python to do this.
To scale ground truth generation and curation, you can apply a risk-based approach in conjunction with a prompt-based strategy using LLMs. Its important to note that LLM-generated ground truth isnt a substitute for use case SME involvement. To convert the source document excerpt into ground truth, we provide a base LLM prompt template.
When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Can you compare images?
Furthermore, we deep dive on the most common generative AI use case of text-to-text applications and LLM operations (LLMOps), a subset of FMOps. LLM-powered evaluation – In this scenario, the prompt testers are replaced by an LLM, ideally one that is more powerful (although perhaps slower and most costly) than the ones being tested.
Using this context, modified prompt is constructed required for the LLM model. A request is posted to the Amazon Bedrock Claude-2 model to get the response from the LLM model selected. The data is post-processed from the LLM response and a response is sent to the user.
It combines principles from DevOps, such as continuous integration, continuous delivery, and continuous monitoring, with the unique challenges of managing machine learning models and datasets. Especially in the current time when large language models (LLMs) are making their way for several industry-based generative AI projects.
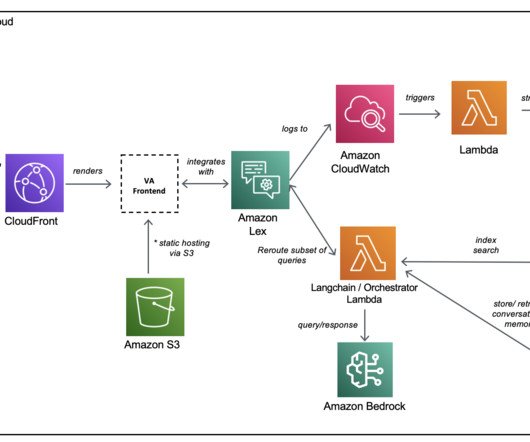
We have included a sample project to quickly deploy an Amazon Lex bot that consumes a pre-trained open-source LLM. This mechanism allows an LLM to recall previous interactions to keep the conversation’s context and pace. We also use LangChain, a popular framework that simplifies LLM-powered applications.
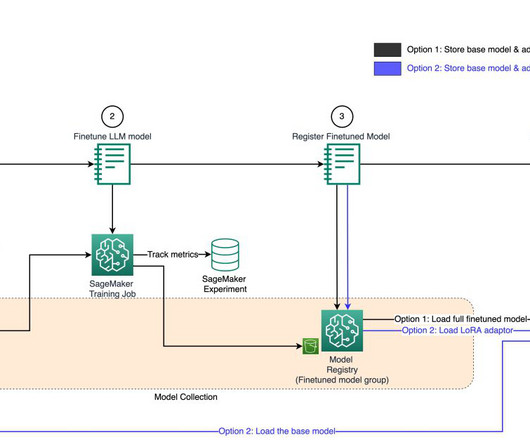
Working with FMs on SageMaker Model Registry In this post, we walk through an end-to-end example of fine-tuning the Llama2 large language model (LLM) using the QLoRA method. Fine-tuning adapts an LLM to a downstream task using a smaller dataset. Training LLMs can be a slow, expensive, and iterative process.
The NVIDIA NeMo Framework provides a comprehensive set of tools, scripts, and recipes to support each stage of the LLM journey, from data preparation to training and deployment. His work spans multilingual text-to-speech, time series classification, ed-tech, and practical applications of deep learning.
However, harnessing this potential while ensuring the responsible and effective use of these models hinges on the critical process of LLM evaluation. An evaluation is a task used to measure the quality and responsibility of output of an LLM or generative AI service. Who needs to perform LLM evaluation?
DIANNA is a groundbreaking malware analysis tool powered by generative AI to tackle real-world issues, using Amazon Bedrock as its large language model (LLM) infrastructure. At the heart of this process are DIANNAs advanced translation engines, which transform complex binary code into natural language that LLMs can understand and analyze.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content