This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Organisations must be aware of the type of data they provide to the LLMs that power their AI products and, importantly, how this data will be interpreted and communicated back to customers. To mitigate this risk, organisations should establish guardrails to prevent LLMs from absorbing and relaying illegal or dangerous information.
Introduction With the advancements in Artificial Intelligence, developing and deploying large language model (LLM) applications has become increasingly complex and demanding. LangSmith is a new cutting-edge DevOps platform designed to develop, collaborate, test, deploy, and monitor LLM applications.
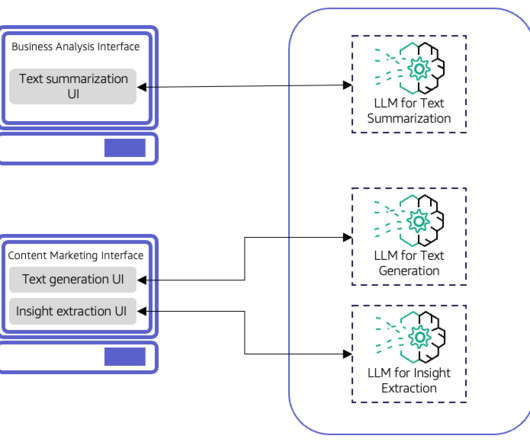
License, is an innovative open-source platform designed to facilitate and accelerate the development of Large Language Model (LLM) applications. Business users can leverage pre-configured application templates and intuitive form-filling processes to build intelligent applications centered around LLM swiftly.
This is where AgentOps comes in; a concept modeled after DevOps and MLOps but tailored for managing the lifecycle of FM-based agents. That said, AgentOps (the tool) offers developers insight into agent workflows with features like session replays, LLM cost tracking, and compliance monitoring. What is AgentOps?
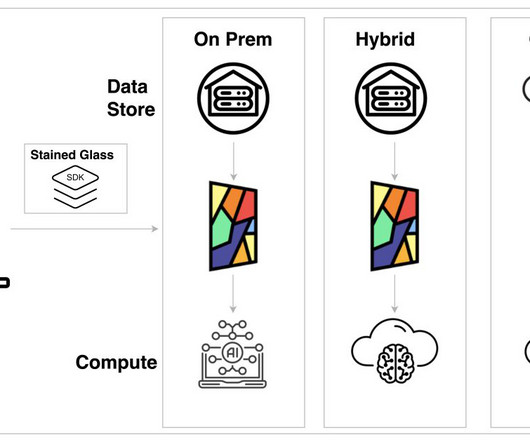
TrueFoundry offers a unified Platform as a Service (PaaS) that empowers enterprise AI/ML teams to build, deploy, and manage large language model (LLM) applications across cloud and on-prem infrastructure. TrueFoundry is uniquely positioned to address the growing complexities of AI deployment.
Organizations are increasingly using multiple large language models (LLMs) when building generative AI applications. Although an individual LLM can be highly capable, it might not optimally address a wide range of use cases or meet diverse performance requirements. In this post, we provide an overview of common multi-LLM applications.
Regardless of a company’s niche, LLMs have enormous promise in areas such as data analysis, code writing, and creative text generation. The development of reliable LLM applications, however, has its challenges. Presently, there is a fragmented scope for LLM growth. Funding round YCombinator backs Keywords AI.
Google Gemini AI Course for Beginners This beginner’s course provides an in-depth introduction to Google’s AI model and the Gemini API, covering AI basics, Large Language Models (LLMs), and obtaining an API key. It’s ideal for those looking to build AI chatbots or explore LLM potentials.
Hawkeyes unique approach leverages the power of LLMs to guide incident analysis without ever sharing customer data with LLMs, ensuring a thoughtful and secure approach. It works alongside IT, DevOps, and SRE teams without requiring major infrastructure changes.
Although much of the focus around analysis of DevOps is on distributed and cloud technologies, the mainframe still maintains a unique and powerful position, and it can use the DORA 4 metrics to further its reputation as the engine of commerce. Using a Git-based SCM pulls these insight together seamlessly. The email is sent to subscribers.
DeepSeek-R1 is an advanced LLM developed by the AI startup DeepSeek. Simplified LLM hosting on SageMaker AI Before orchestrating agentic workflows with CrewAI powered by an LLM, the first step is to host and query an LLM using SageMaker real-time inference endpoints.
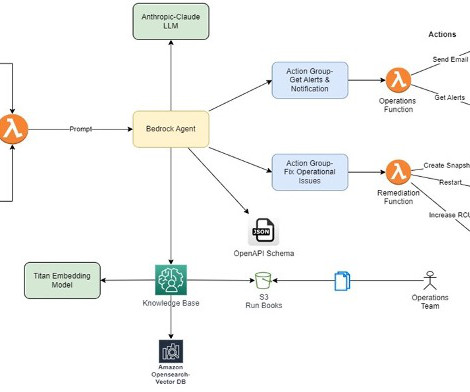
The agent uses Anthropics Claude LLM available on Amazon Bedrock as one of the FMs to analyze incident details and retrieve relevant information from the knowledge base, a curated collection of runbooks and best practices. The following architecture diagram explains the overall flow of this solution. About the Authors Upendra V is a Sr.
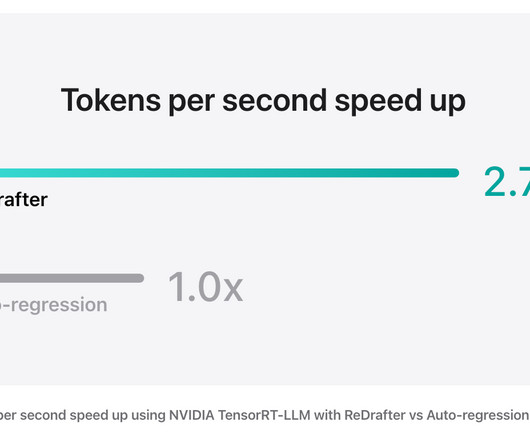
Articles Apple has published a blog post on ReDrafter into NVIDIA's TensorRT-LLM framework, which makes the LLM much more efficient for inference use case. tokens per step, ReDrafter significantly reduces the number of forward passes through the main LLM, leading to faster overall generation.
And there’s no reason why mainframe applications wouldn’t benefit from agile development and smaller, incremental releases within a DevOps-style automated pipeline. Here’s where the magic of an LLM tuned on enterprise COBOL-to-Java conversion can make a difference. Transformation.
The use of multiple external cloud providers complicated DevOps, support, and budgeting. With this LLM, CreditAI was now able to respond better to broader, industry-wide queries than before. Anthropic Claude LLM performs the natural language processing, generating responses that are then returned to the web application.
call stack and data structures), terminal text output, and question to an LLM, which will respond here with something like: Note how the LLM can see your current code and visualization, so it can explain to you whats going on here. written instructions) that direct LLMs to produce easily understandable responses.
New and powerful large language models (LLMs) are changing businesses rapidly, improving efficiency and effectiveness for a variety of enterprise use cases. Speed is of the essence, and adoption of LLM technologies can make or break a business’s competitive advantage.
This is where LLMOps steps in, embodying a set of best practices, tools, and processes to ensure the reliable, secure, and efficient operation of LLMs. Custom LLM Training : Developing a LLM from scratch promises an unparalleled accuracy tailored to the task at hand.
Application modernization is the process of updating legacy applications leveraging modern technologies, enhancing performance and making it adaptable to evolving business speeds by infusing cloud native principles like DevOps, Infrastructure-as-code (IAC) and so on.
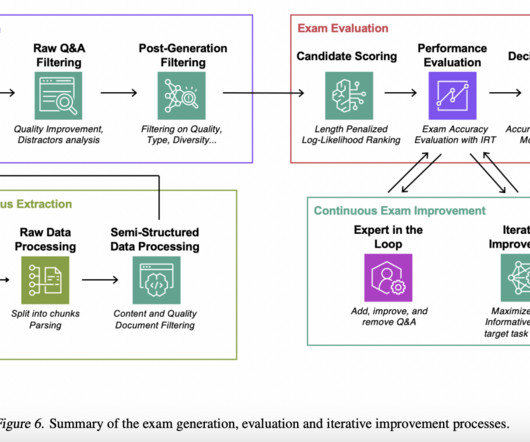
However, evaluating LLMs on a wider range of tasks can be extremely difficult. Public standards do not always accurately reflect an LLM’s general skills, especially when it comes to performing highly specialized client tasks that call for domain-specific knowledge. The team has shared their primary contributions as follows.
Google Gemini AI Course for Beginners This beginner’s course provides an in-depth introduction to Google’s AI model and the Gemini API, covering AI basics, Large Language Models (LLMs), and obtaining an API key. It’s ideal for those looking to build AI chatbots or explore LLM potentials.
To scale ground truth generation and curation, you can apply a risk-based approach in conjunction with a prompt-based strategy using LLMs. Its important to note that LLM-generated ground truth isnt a substitute for use case SME involvement. To convert the source document excerpt into ground truth, we provide a base LLM prompt template.
It can also aid in platform engineering, for example by generating DevOps pipelines and middleware automation scripts. also includes access to the StarCoder LLM, trained on openly licensed data from GitHub. It can improve IT automation by building and executing runbooks and helping users transition to new knowledge bases and software.
a state-of-the-art large language model (LLM). Anthropic’s Claude LLM is trained on a dataset of anonymous data, not data from the Classworks platform, providing complete student privacy. Roy Gunter , DevOps Engineer at Curriculum Advantage, manages cloud infrastructure and automation for Classworks.
These sessions, featuring Amazon Q Business , Amazon Q Developer , Amazon Q in QuickSight , and Amazon Q Connect , span the AI/ML, DevOps and Developer Productivity, Analytics, and Business Applications topics. In this builders’ session, learn how to pre-train an LLM using Slurm on SageMaker HyperPod.
The Hugging Face containers host a large language model (LLM) from the Hugging Face Hub. In this post, we deploy the Mistral 7B Instruct, an LLM available in the Hugging Face Model Hub, to a SageMaker endpoint to perform the summarization tasks. Mateusz Zaremba is a DevOps Architect at AWS Professional Services.
Prior to AWS, he worked as a DevOps architect in the e-commerce industry for over 5 years, following a decade of R&D work in mobile internet technologies. The observed differences in TTFT are solely attributed to network latency because identical FM inference configurations were employed in both the Local Zone and the parent Region.
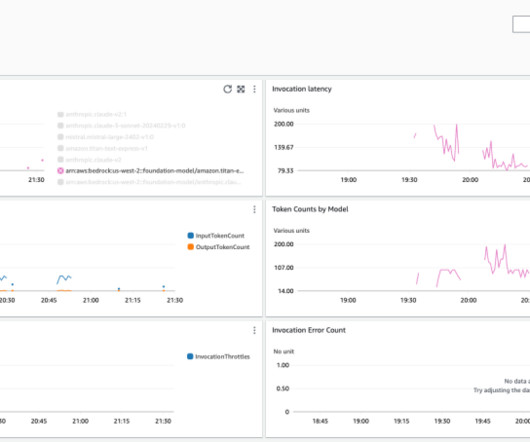
For example, you can write a Logs Insights query to calculate the token usage of the various applications and users calling the large language model (LLM). Attributing LLM usage to specific users or applications. He focuses on monitoring and operationalizing cloud and LLM workloads in CloudWatch for AWS customers.
Improved Training Data : Rich metadata allows for better contextualization of extracted knowledge when creating datasets for LLM training. Cedric Clyburn (@cedricclyburn), Senior Developer Advocate at Red Hat, is an enthusiastic software technologist with a background in Kubernetes, DevOps, and container tools.
As you move from pilot and test phases to deploying generative AI models at scale, you will need to apply DevOps practices to ML workloads. The solution has three main steps: Write Python code to preprocess, train, and test an LLM in Amazon Bedrock. Add @step decorated functions to convert the Python code to a SageMaker pipeline.
Create a complete AI/ML pipeline for fine-tuning an LLM using drag-and-drop functionality. Llama fine-tuning pipeline overview In this post, we will show you how to set up an automated LLM customization (fine-tuning) workflow so that the Llama 3.x But fine-tuning an LLM just once isn’t enough.
Furthermore, we deep dive on the most common generative AI use case of text-to-text applications and LLM operations (LLMOps), a subset of FMOps. LLM-powered evaluation – In this scenario, the prompt testers are replaced by an LLM, ideally one that is more powerful (although perhaps slower and most costly) than the ones being tested.
Anthropic has just announced its new Claude Enterprise Plan, marking a significant development in the large language model (LLM) space and offering businesses a powerful AI collaboration tool designed with security and scalability in mind.
Using this context, modified prompt is constructed required for the LLM model. A request is posted to the Amazon Bedrock Claude-2 model to get the response from the LLM model selected. The data is post-processed from the LLM response and a response is sent to the user.
Furthermore, the cost to train new LLMs can prove prohibitive for many enterprise settings. However, it’s possible to cross-reference a model answer with the original specialized content, thereby avoiding the need to train a new LLM model, using Retrieval-Augmented Generation (RAG). We have provided this demo in the GitHub repo.
It combines principles from DevOps, such as continuous integration, continuous delivery, and continuous monitoring, with the unique challenges of managing machine learning models and datasets. Especially in the current time when large language models (LLMs) are making their way for several industry-based generative AI projects.
Additionally, AWS Q, an agent capable of performing various developer and devops operations, supports native integration with AWS services. Inflection-2 Inflection unveiled the initial results of the training of Inflection-2, its next generation LLM. An area that caught my attention was the enhanced support for RAG and agents.
This latest addition to the SageMaker suite of machine learning (ML) capabilities empowers enterprises to harness the power of large language models (LLMs) and unlock their full potential for a wide range of applications. Cohere Command R is a scalable, frontier LLM designed to handle enterprise-grade workloads with ease.
We have included a sample project to quickly deploy an Amazon Lex bot that consumes a pre-trained open-source LLM. This mechanism allows an LLM to recall previous interactions to keep the conversation’s context and pace. We also use LangChain, a popular framework that simplifies LLM-powered applications.
It’s a next generation model in the Falcon family—a more efficient and accessible large language model (LLM) that is trained on a 5.5 Falcon 2 11B text generation To deploy using the SDK, we start by selecting the Falcon 2 11B model, specified by the model_id with value huggingface-llm-falcon2-11b.
In this post, we discuss how Thomson Reuters Labs created Open Arena, Thomson Reuters’s enterprise-wide large language model (LLM) playground that was developed in collaboration with AWS. The retrieved best match is then passed as an input to the LLM along with the query to generate the best response.
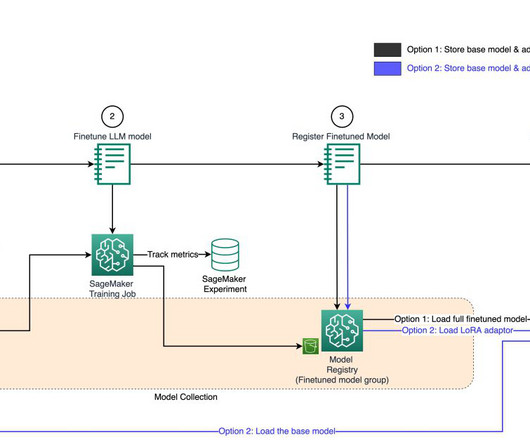
Working with FMs on SageMaker Model Registry In this post, we walk through an end-to-end example of fine-tuning the Llama2 large language model (LLM) using the QLoRA method. Fine-tuning adapts an LLM to a downstream task using a smaller dataset. Training LLMs can be a slow, expensive, and iterative process.
Comet can serve an LLM (Large Language Model) project from pre-training to post-deployment by providing a comprehensive suite of tools and features that help users with every stage of the project and simplifying the process of developing and deploying LLMs.
Overview of RAG The RAG pattern lets you retrieve knowledge from external sources, such as PDF documents, wiki articles, or call transcripts, and then use that knowledge to augment the instruction prompt sent to the LLM. This allows the LLM to reference more relevant information when generating a response.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content