This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
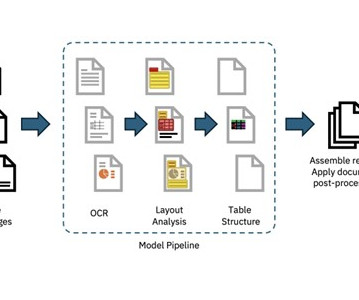
Research papers and engineering documents often contain a wealth of information in the form of mathematical formulas, charts, and graphs. Navigating these unstructured documents to find relevant information can be a tedious and time-consuming task, especially when dealing with large volumes of data. Generate metadata for the page.
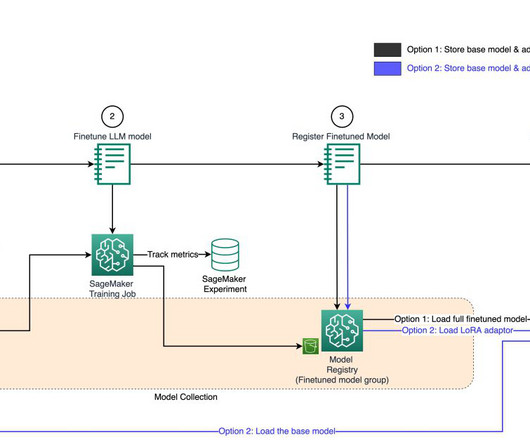
We provide additional information later in this post. The functional architecture with different capabilities is implemented using a number of AWS services, including AWS Organizations , Amazon SageMaker , AWS DevOps services, and a data lake. For more information about the architecture in detail, refer to Part 1 of this series.
These indexes enable efficient searching and retrieval of part data and vehicle information, providing quick and accurate results. The agents also automatically call APIs to perform actions and access knowledge bases to provide additional information. The embeddings are stored in the Amazon OpenSearch Service owner manuals index.
Everything is data—digital messages, emails, customer information, contracts, presentations, sensor data—virtually anything humans interact with can be converted into data, analyzed for insights or transformed into a product. They should also have access to relevant information about how data is collected, stored and used.
Investment professionals face the mounting challenge of processing vast amounts of data to make timely, informed decisions. This challenge is particularly acute in credit markets, where the complexity of information and the need for quick, accurate insights directly impacts investment outcomes.
When extracting the text to a simple format like Markdown, even when the text is identified, a lot of the contextual information is lost, making it difficult to determine the context of a text with high-accuracy for advanced NLPtasks. As the screenshot below shows, the context information derived from the original layout is completely lost.
OpenTelemetry and Prometheus enable the collection and transformation of metrics, which allows DevOps and IT teams to generate and act on performance insights. Benefits of OpenTelemetry The OpenTelemetry protocol (OTLP) simplifies observability by collecting telemetry data, like metrics, logs and traces, without changing code or metadata.
The information pertaining to the request and response is stored in Amazon S3. He is a technology enthusiast and a builder with a core area of interest in AI/ML, data analytics, serverless, and DevOps. Args: input_data (obj): the request data. content_type (str): the request Content-Type. Raju Patil is a Sr.
DevOps engineers often use Kubernetes to manage and scale ML applications, but before an ML model is available, it must be trained and evaluated and, if the quality of the obtained model is satisfactory, uploaded to a model registry. They often work with DevOps engineers to operate those pipelines. curl for transmitting data with URLs.
Lived through the DevOps revolution. Founded neptune.ai , a modular MLOps component for ML metadata store , aka “experiment tracker + model registry”. If you’d like a TLDR, here it is: MLOps is an extension of DevOps. There will be only one type of ML metadata store (model-first), not three. Came to ML from software.
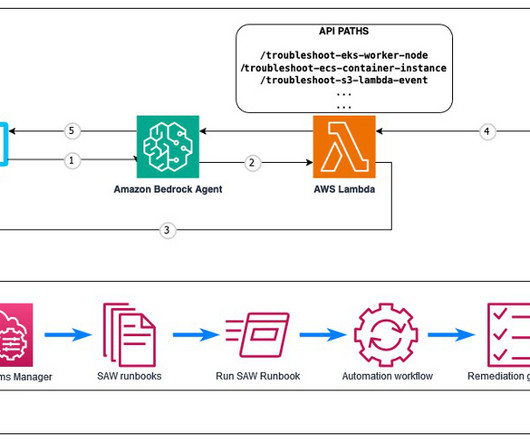
It processes natural language queries to understand the issue context and manages conversation flow to gather required information. If essential information is missing, such as a cluster name or instance ID, the agent engages in a natural conversation to gather the required parameters. The agent uses Anthropics Claude 3.5
It automatically keeps track of model artifacts, hyperparameters, and metadata, helping you to reproduce and audit model versions. As you move from pilot and test phases to deploying generative AI models at scale, you will need to apply DevOps practices to ML workloads.
To ensure the highest quality measurement of your question answering application against ground truth, the evaluation metrics implementation must inform ground truth curation. For more information, see the Amazon Bedrock documentation on LLM prompt design and the FMEval documentation.
Imagine yourself as a pilot operating aircraft through a thunderstorm; you have all the dashboards and automated systems that inform you about any risks. You use this information to make decisions to navigate and land safely. 1 IDC, MLOps – Where ML Meets DevOps, doc #US48544922, March 2022. See DataRobot MLOps in Action.
Deliver new insights Expert systems can be trained on a corpus—metadata used to train a machine learning model—to emulate the human decision-making process and apply this expertise to solve complex problems. Transportation AI informs many transportation systems these days.
Data security is very important for organizations as they need their clients to trust them with their sensitive information. DevSecOps includes all the characteristics of DevOps, such as faster deployment, automated pipelines for build and deployment, extensive testing, etc.,
When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Can you compare images?
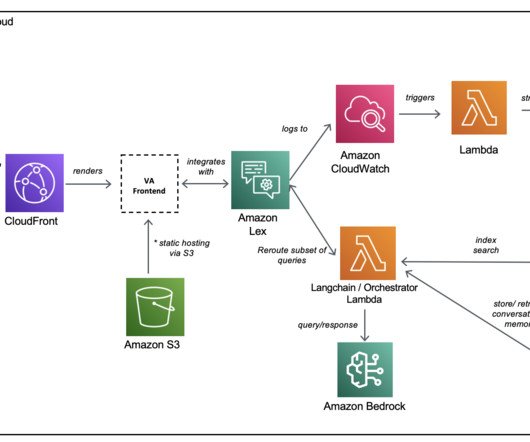
Enterprises today face major challenges when it comes to using their information and knowledge bases for both internal and external business operations. Internally, employees can often spend countless hours hunting down information they need to do their jobs, leading to frustration and reduced productivity.
That is where Provectus , an AWS Premier Consulting Partner with competencies in Machine Learning, Data & Analytics, and DevOps, stepped in. It also persists a manifest file to Amazon S3, including all necessary information to recreate that dataset version.
model.create() creates a model entity, which will be included in the custom metadata registered for this model version and later used in the second pipeline for batch inference and model monitoring. In Studio, you can choose any step to see its key metadata. large", accelerator_type="ml.eia1.medium", large", accelerator_type="ml.eia1.medium",
The most important pieces of information such as price, vendor name, vendor address, and payment terms are often not explicitly labeled and have to be interpreted based on context. You can visualize the indexed metadata using OpenSearch Dashboards. Additional output information is also available on the AWS CloudFormation console.
However, this can mean processing customer data in the form of personally identifiable information (PII) in relation to activities such as purchases, returns, use of flexible payment options, and account management. The result of the solution is that The Very Group has freedom to put logs through without needing to worry.
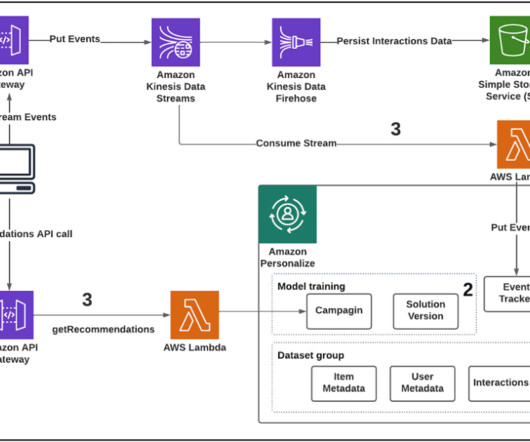
For more information, refer to Architecting near real-time personalized recommendations with Amazon Personalize. Configure CLI with your Amazon account – Configure the AWS CLI with your AWS account information. Get near real-time recommendations – When you have a campaign, you can integrate calls to the campaign in your application.
For more information about best practices, refer to the AWS re:Invent 2019 talk, Build accurate training datasets with Amazon SageMaker Ground Truth. The output of a SageMaker Ground Truth labeling job is a file in JSON-lines format containing the labels and additional metadata. There are many ways to ensure good label quality.
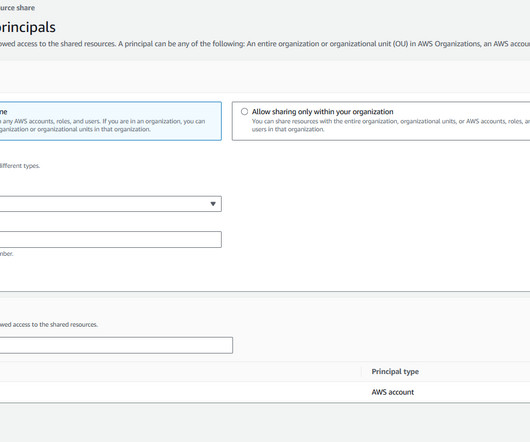
One of the tools available as part of the ML governance is Amazon SageMaker Model Cards , which has the capability to create a single source of truth for model information by centralizing and standardizing documentation throughout the model lifecycle. For more information, refer to Example IAM policies for AWS RAM.
It combines principles from DevOps, such as continuous integration, continuous delivery, and continuous monitoring, with the unique challenges of managing machine learning models and datasets. As the adoption of machine learning in various industries continues to grow, the demand for robust MLOps tools has also increased. What is MLOps?
Carl Froggett, is the Chief Information Officer (CIO) of Deep Instinct , an enterprise founded on a simple premise: that deep learning , an advanced subset of AI, could be applied to cybersecurity to prevent more threats, faster. Generally, these customers are also adopting a “shift left” with DevOps.
Data scientists, ML engineers, IT staff, and DevOps teams must work together to operationalize models from research to deployment and maintenance. The model registry maintains records of model versions, their associated artifacts, lineage, and metadata. For more information, refer to Using environments for deployment.
These files contain metadata, current state details, and other information useful in planning and applying changes to infrastructure. This is critical especially when multiple DevOps team members are working on the configuration. In Terraform, the state files are important as they play a crucial role in monitoring resources.
The functional architecture with different capabilities is implemented using a number of AWS services, including AWS Organizations , SageMaker, AWS DevOps services, and a data lake. The architecture maps the different capabilities of the ML platform to AWS accounts.
It provides the flexibility to log your model metrics, parameters, files, artifacts, plot charts from the different metrics, capture various metadata, search through them and support model reproducibility. Data scientists can quickly compare the performance and hyperparameters for model evaluation through visual charts and tables. .
Source Model packaging is a process that involves packaging model artifacts, dependencies, configuration files, and metadata into a single format for effortless distribution, installation, and reuse. These teams may include but are not limited to data scientists, software developers, machine learning engineers, and DevOps engineers.
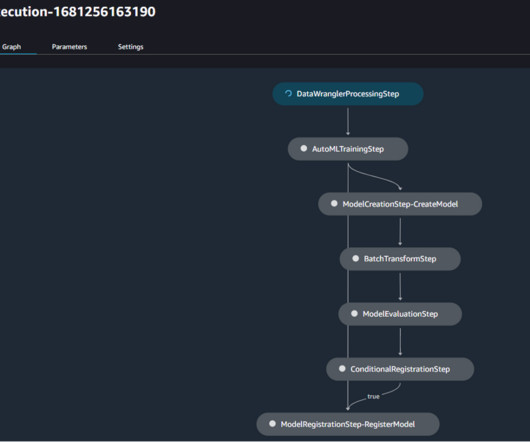
For information about what the parameters mean, refer to LoRA training parameters. In the graph, choose the pipeline step named TrainNewFineTunedModel to access the pipeline run information. The Details tab displays metadata, logs, and the associated training job. This file is provided with opinionated values.
Building a tool for managing experiments can help your data scientists; 1 Keep track of experiments across different projects, 2 Save experiment-related metadata, 3 Reproduce and compare results over time, 4 Share results with teammates, 5 Or push experiment outputs to downstream systems.
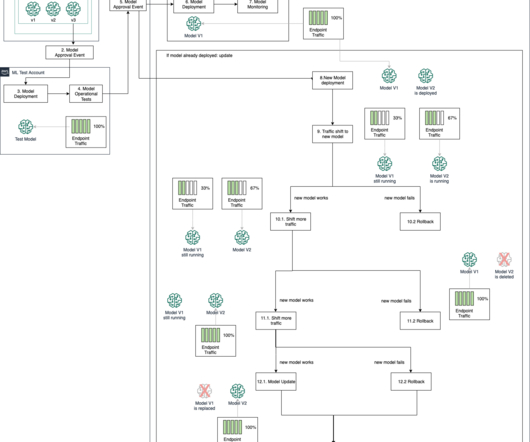
For general information on these patterns, refer to Take advantage of advanced deployment strategies using Amazon SageMaker deployment guardrails and Deployment guardrails. The model artifacts and associated metadata are stored in the SageMaker Model Registry as the last step of the training process.
You are provided with information about entities the Human mentions, if relevant. A session stores metadata and application-specific data known as session attributes. Solutions Architect at Amazon Web Services with specialization in DevOps and Observability. A session persists over time unless manually stopped or timed out.
One of the tools available as part of the ML governance is Amazon SageMaker Model Cards , which has the capability to create a single source of truth for model information by centralizing and standardizing documentation throughout the model lifecycle. For more information, refer to Example IAM policies for AWS RAM.
MLflow can be seen as a tool that fits within the MLOps (synonymous with DevOps) framework. The API helps to log, track, and store information regarding experiments. Local Tracking with Database: You can use a local database to manage experiment metadata for a cleaner setup compared to local files. What is MLflow Tracking?
We’re trying to provide precisely a means to store and capture that extra metadata for you so you don’t have to build that component out so that we can then connect it with other systems you might have. Maybe storing and emitting open lineage information, etc. ML platform team can be for this DevOps team.
quality attributes) and metadata enrichment (e.g., The DevOps and Automation Ops departments are under the infrastructure team. For example, they wouldn’t want personal information to get out to labelers or bad content to get out to users. On top of the teams, they also have departments.
For me, it was a little bit of a longer journey because I kind of had data engineering and cloud engineering and DevOps engineering in between. There’s no component that stores metadata about this feature store? Mikiko Bazeley: In the case of the literal feature store, all it does is store features and metadata. Yes or no?”
SageMaker provides a set of templates for organizations that want to quickly get started with ML workflows and DevOps continuous integration and continuous delivery (CI/CD) pipelines. For more information, refer to MLOps foundation roadmap for enterprises with Amazon SageMaker. For this post, you use a CloudFormation template.
Here, the component will also return statistics and metadata that help you understand if the model suits the target deployment environment. Model deployment You can deploy the packaged and registered model to a staging environment (as traditional software with DevOps) or the production environment. Implementing system governance.
For more information, refer to Amazon EC2 Instance Types. aws ecr create-repository --repository-name ${IMAGE} fi # Push image docker image push ${REGISTRY}${IMAGE}${TAG} The NVIDIA NeMo Framework requires users to provide config files with job and model information. Launch an EKS cluster ECR p4de.24xlarge 24xlarge instances.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content