This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
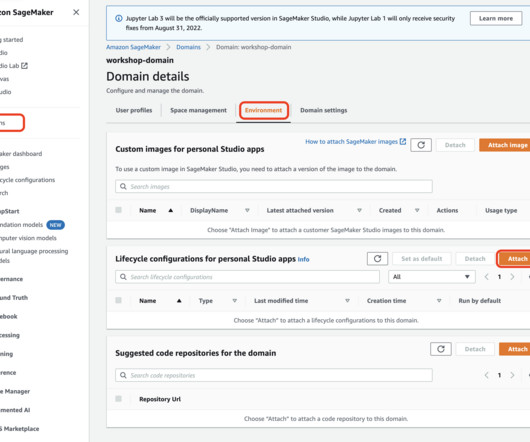
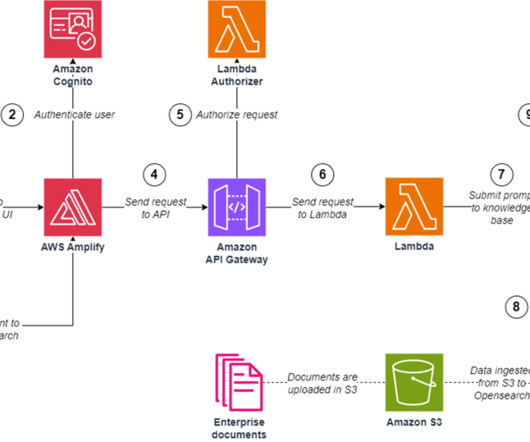
This post presents and compares options and recommended practices on how to manage Python packages and virtual environments in Amazon SageMaker Studio notebooks. You can manage app images via the SageMaker console, the AWS SDK for Python (Boto3), and the AWS Command Line Interface (AWS CLI). Define a Dockerfile.
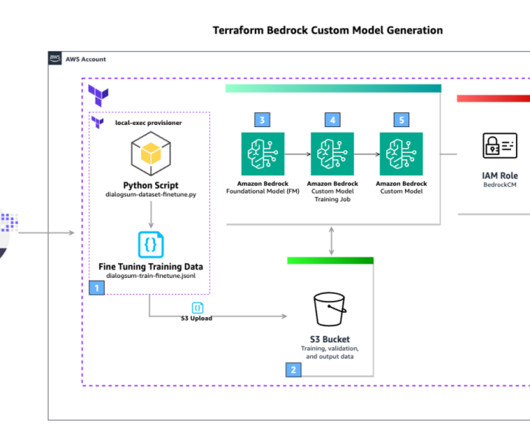
Solution overview We use Terraform to download a public dataset from the Hugging Face Hub , convert it to JSONL format, and upload it to an Amazon Simple Storage Service (Amazon S3) bucket with a versioned prefix. Configure your local Python virtual environment. Download the DialogSum public dataset and convert it to JSONL.
DevOps From a DevOps perspective, the frontend uses Amplify to build and deploy, and the backend is uses AWS Serverless Application Model (AWS SAM) to build, package, and deploy the serverless applications. You can download and install Docker from Docker’s official website. Generate avatar videos: python create_pose_videos.py
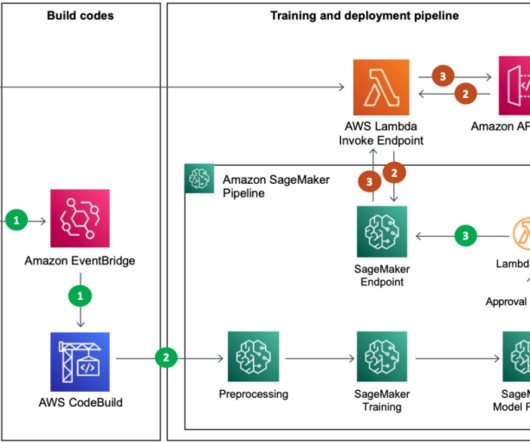
In this post, we show you how to convert Python code that fine-tunes a generative AI model in Amazon Bedrock from local files to a reusable workflow using Amazon SageMaker Pipelines decorators. The SageMaker Pipelines decorator feature helps convert local ML code written as a Python program into one or more pipeline steps.
The Code Generator supports over 30 languages, from JavaScript to Python, Swift to Ruby, and everything in between. Once the code has been generated, copy it to your clipboard or download the results. DevOps The DevOps tools CodePal simplify code deployment and streamline coding tasks. Download results.
Furthermore, DevOps were burdened with manually provisioning GPU instances in response to demand patterns. Additional dependencies needed to run the Python models are detailed in a requirements.txt file, and need to be conda-packed to build a Conda environment ( python_env.tar.gz). Download the model weights.
xlarge', 'InferenceAmiVersion': 'al2-ami-sagemaker-inference-gpu-2', 'RoutingConfig': {'RoutingStrategy': 'LEAST_OUTSTANDING_REQUESTS'}, 'ModelDataDownloadTimeoutInSeconds': 3600, # Specify the model download timeout in seconds. When not working, he enjoys road cycling, hiking, playing volleyball, and photography.
sudo service docker start Run the following command to download and run the Docker image for TGI server as well as Llama 3.2-3B Prior to AWS, he worked as a DevOps architect in the e-commerce industry for over 5 years, following a decade of R&D work in mobile internet technologies. This comes preinstalled with the AMI we selected.
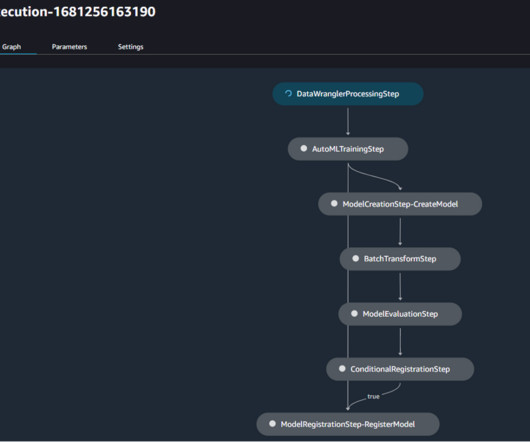
Download the pipeline definition as a JSON file to your local environment by choosing Export at the bottom of the visual editor. To do this, you will use an Execute code step type that allows you to run the Python code that performs model evaluation using the factual knowledge evaluation from the fmeval library.
TL;DR This series explain how to implement intermediate MLOps with simple python code, without introducing MLOps frameworks (MLflow, DVC …). My interpretation to MLOps is similar to my interpretation of DevOps. Python has different flavors, and some freedom about the location of scripts and components. Why is this a requirement?
In the following sections, we discuss how to satisfy the prerequisites, download the code, and use the Jupyter notebook in the GitHub repository to deploy the automated solution using an Amazon SageMaker Studio environment. Download the code to your SageMaker Studio environment Run the following commands from the terminal.
Prerequisites To follow along and set up this solution, you must have the following: An AWS account A device with access to your AWS account with the following: Python 3.12 From the api folder, go to the lambda-auth folder and download the dependencies with the following command: pip install -r requirements.txt -t. installed Node.js
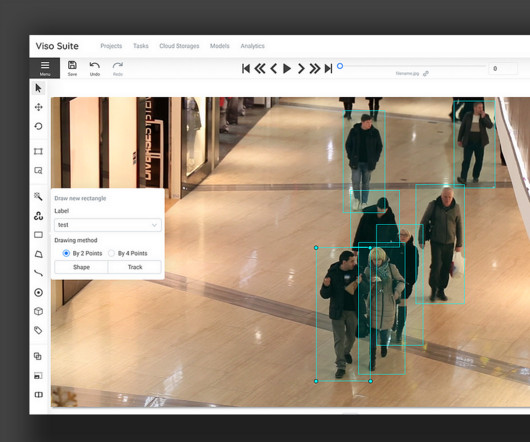
CVAT stands for Computer Vision Annotation Tool ; it is a free, open-source digital image animation tool written in Python and JavaScript. You can try it online on cvat.org without downloading any dependencies or packages for free. Annotation import and export In CVAT, you can upload annotations or dump annotations (download).
Therefore, organizations have adopted technology best practices, including microservice architecture, MLOps, DevOps, and more, to improve delivery time, reduce defects, and increase employee productivity. Set up Data Wrangler Download the bank.zip dataset from the University of California Irving Machine Learning Repository.
Right now, most deep learning frameworks are built for Python, but this neglects the large number of Java developers and developers who have existing Java code bases they want to integrate the increasingly powerful capabilities of deep learning into. For this reason, many DJL users also use it for inference only. With v0.21.0
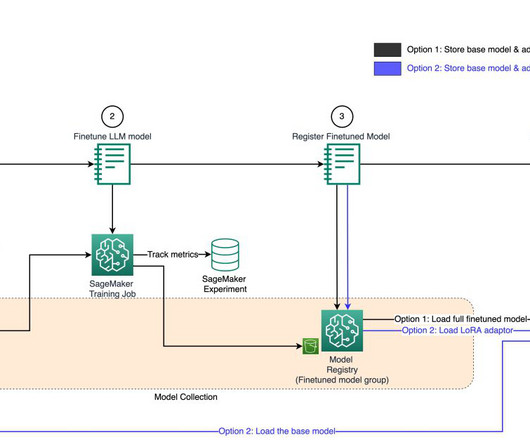
Each works through a different way to handle LoRA fine-tuned models as illustrated in the following diagram: First, we download the pre-trained Llama2 model with 7 billion parameters using SageMaker Studio Notebooks. Python 3.10 In the following code example, download and repack the latest version of the base model first. !aws
Data scientists, ML engineers, IT staff, and DevOps teams must work together to operationalize models from research to deployment and maintenance. site-packages/ python zip -r layer.zip python Publish the layer to AWS: aws lambda publish-layer-version --layer-name python39-github-arm64 --description "Python3.9 Choose Review.
However, if you specify the framework for your estimator here, you can pass in the version of the framework and Python version to use, and it will automatically fetch the version-appropriate container image from Amazon ECR. Make sure to enter the same PyTorch framework, Python version, and other details that you used to train the model.
To make this happen we will use AWS Free Tie r and Docker containers and orchestration and Django app as a typical project Link on this project github: [link] Before go farther please install Docker first: [link] All code running under Python 3.6 We will search for Python, Nginx, PostgreSQL. Containers are not virtual machines.
To start our ML project predicting the probability of readmission for diabetes patients, you need to download the Diabetes 130-US hospitals dataset. For instance, instead of a vague query about AWS services, try: “Can you provide sample code using the SageMaker Python SDK library to train an XGBoost model in SageMaker?”
With this single entry point that triggers a collection of Terraform scripts, one per service or resource entity, we can fully automate the lifecycle of all or parts of the components of the architecture, allowing us to implement granular control both on the DevOps as well as the MLOps side. Refinitiv Data Library for Python.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., The entire model can be downloaded to your source code’s runtime with a single line of code. and programmatically via the Kolena Python client. and Pandas or Apache Spark DataFrames.
That’s why we’re pleased to introduce Prodigy , a downloadable tool for radically efficient machine teaching. Most of those insights have been used to make spaCy better: AI DevOps was hard, so we made sure models could be installed via pip. You can also download the annotated data set we’ve created with Prodigy for this example.
Download and save the publicly available UCI Mammography Mass dataset to the S3 bucket you created earlier in the dev account. Saswata Dash is a DevOps Consultant with AWS Professional Services. Set up an S3 bucket to maintain the Terraform state in the prod account. resource('s3') s3_client.Bucket(default_bucket).upload_file("pipelines/train/scripts/raw_preprocess.py","mammography-severity-model/scripts/raw_preprocess.py")
It restricts the amount of data you download. Versioned data and Docker enable data scientists and DevOps teams to deploy models confidently. Hg is a platform-independent tool created in Python. This is a relatively simple solution in terms of data handling. The points point to the LFS and are made of a lighter material.
Robustness You need an elastic data model to support: Varying team sizes and structures (a single data scientist only, or maybe a team of one data scientist, 4 machine learning engineers, 2 DevOps engineers, etc.). And, of course, you may also want to promote or download your models from this view.
SageMaker provides a set of templates for organizations that want to quickly get started with ML workflows and DevOps continuous integration and continuous delivery (CI/CD) pipelines. You can also add your own Python scripts and transformations to customize workflows. Python code file. Choose the file browser icon view the path.
When the job is finished, you can remove the Helm chart: helm uninstall download-gpt3-pile You can see the downloaded the data in the /fsx-shared folder by running in one of the pods as kubectl exec -it nlp-worker-0 bash. Training Now that our data preparation is complete, we’re ready to train our model with the created dataset.
So they download all of the text on the internet, and they train language models to predict all of that text. Why do we have MLOps as opposed to DevOps? And you can rely on whether that’s MLOps or DevOps or whatever it is, building reliable computational flows. They have Python, a Python library, and a JavaScript library.
is a flexible, IDE-independent Python-based framework that enables flexible integration in each developers workflow. It includes default configurations for compute cluster setup, data downloading, and model hyperparameters autotuning, which can be adjusted to train on new datasets and models. NeMo Framework 2.0 architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
The code artifacts are in Python. For the purpose of this notebook, we downloaded the MP4 file for the recording and stored it in an Amazon Simple Storage Service (Amazon S3) bucket. Use case overview In this post, we discuss three example use cases in detail. We used a Jupyter notebook to run the code snippets.
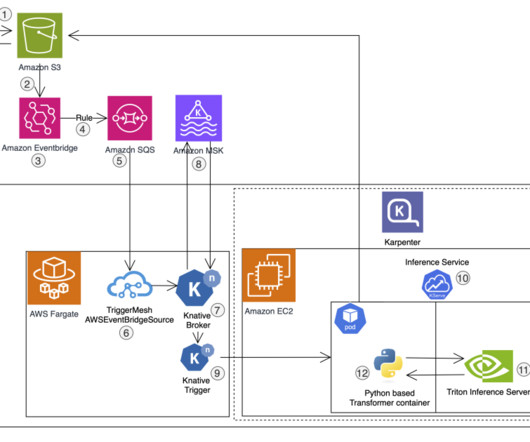
With our new model, we first tried performing inference in Python with Flask and PyTorch, as well as with BentoML. The transformer gets a CloudEvent with the reference of the image Amazon S3 path, downloads it, and performs model inference over HTTP. Our previous model was running on TorchServe. We use Amazon EKS for everything else.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content