This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This enables the efficient processing of content, including scientific formulas and data visualizations, and the population of Amazon Bedrock Knowledge Bases with appropriate metadata. Generate metadata for the page. Generate metadata for the full document. Upload the content and metadata to Amazon S3.
The Annotated type is used to provide additional metadata about the return value, specifically that it should be included in the response body. With over 4 years at AWS and 2 years of previous experience as a DevOps engineer, Marwen works closely with customers to implement AWS best practices and troubleshoot complex technical challenges.
It automatically keeps track of model artifacts, hyperparameters, and metadata, helping you to reproduce and audit model versions. As you move from pilot and test phases to deploying generative AI models at scale, you will need to apply DevOps practices to ML workloads. We use Python to do this.
When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Can you compare images?
In the following sections, we discuss how to satisfy the prerequisites, download the code, and use the Jupyter notebook in the GitHub repository to deploy the automated solution using an Amazon SageMaker Studio environment. Download the code to your SageMaker Studio environment Run the following commands from the terminal.
This is done on the features that security vendors might sign, starting from hardcoded strings, IP/domain names of C&C servers, registry keys, file paths, metadata, or even mutexes, certificates, offsets, as well as file extensions that are correlated to the encrypted files by ransomware.
Since it’s open source, you can download it for free and host as many instances as you want without incurring license fees. The metadata store is where MLflow keeps the experiment and model metadata. After all, it exposes the UI, collects the metadata, and provides access to the model artifacts.
As per the definition and the required ML expertise, MLOps is required mostly for providers and fine-tuners, while consumers can use application productionization principles, such as DevOps and AppDev to create the generative AI applications. Proprietary models might sometimes offer the option of fine-tuning.
Data scientists, ML engineers, IT staff, and DevOps teams must work together to operationalize models from research to deployment and maintenance. The model registry maintains records of model versions, their associated artifacts, lineage, and metadata. Download the template.yml file to your computer. Choose Upload a template.
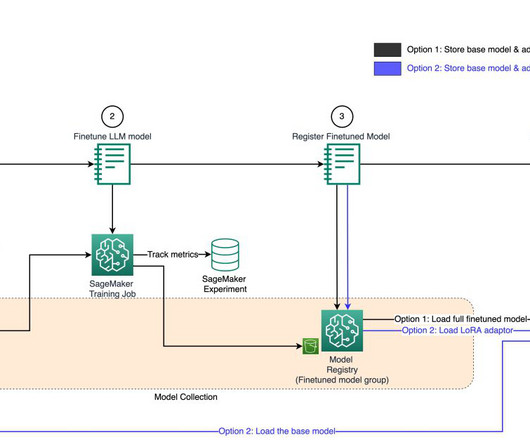
Each works through a different way to handle LoRA fine-tuned models as illustrated in the following diagram: First, we download the pre-trained Llama2 model with 7 billion parameters using SageMaker Studio Notebooks. They can also use SageMaker Experiments to download the created charts and share the model evaluation with their stakeholders.
This data version is frequently recorded into your metadata management solution to ensure that your model training is versioned and repeatable. It restricts the amount of data you download. In addition to supporting batch and streaming data processing, Delta Lake also offers scalable metadata management.
Building a tool for managing experiments can help your data scientists; 1 Keep track of experiments across different projects, 2 Save experiment-related metadata, 3 Reproduce and compare results over time, 4 Share results with teammates, 5 Or push experiment outputs to downstream systems.
SageMaker provides a set of templates for organizations that want to quickly get started with ML workflows and DevOps continuous integration and continuous delivery (CI/CD) pipelines. This includes the name and description of the project, information about the project template and SourceModelPackageGroupName , and metadata about the project.
When the job is finished, you can remove the Helm chart: helm uninstall download-gpt3-pile You can see the downloaded the data in the /fsx-shared folder by running in one of the pods as kubectl exec -it nlp-worker-0 bash. Training Now that our data preparation is complete, we’re ready to train our model with the created dataset.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content