This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The platform automatically analyzes metadata to locate and label structured data without moving or altering it, adding semantic meaning and aligning definitions to ensure clarity and transparency. Can you explain the core concept and what motivated you to tackle this specific challenge in AI and data analytics?
SELECT count (*) FROM FLIGHT.FLIGHTS_DATA — — — 99879 Look into the scheme definition of the table. Here are some of the key tables: FLIGHT_DECTREE_MODEL: this table contains metadata about the model. For each code example, when applicable, I explained intuitively what it does, and its inputs and outputs.
The embeddings, along with metadata about the source documents, are indexed for quick retrieval. It provides constructs to help developers build generative AI applications using pattern-based definitions for your infrastructure. Technical Info: Provide part specifications, features, and explain component functions.
A significant challenge in AI applications today is explainability. How does the knowledge graph architecture of the AI Context Engine enhance the accuracy and explainability of LLMs compared to SQL databases alone? With the rise of generative AI, our customers wanted AI solutions that could interact with their data conversationally.
The concepts will be explained. This marketplace provides a search mechanism, utilizing metadata and a knowledge graph to enable asset discovery. Metadata plays a key role here in discovering the data assets. As it is clear from the definition above, unlike data fabric, data mesh is about analytical data.
There was no mechanism to pass and store the metadata of the multiple experiments done on the model. Because we wanted to track the metrics of an ongoing training job and compare them with previous training jobs, we just had to parse this StdOut by defining the metric definitions through regex to fetch the metrics from StdOut for every epoch.
The absence of centralized workflow definitions means that message processing occurs naturally based on publication timing and agent availability, creating a fluid and adaptable system that can evolve with changing requirements. Understanding how to implement this type of pattern will be explained later in this post.
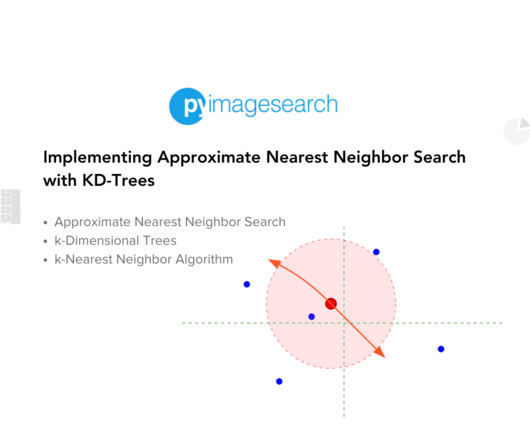
product specifications, movie metadata, documents, etc.) With reaching billions, no hardware can process these operations in a definite amount of time. All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. Imagine a database with billions of samples ( ) (e.g.,
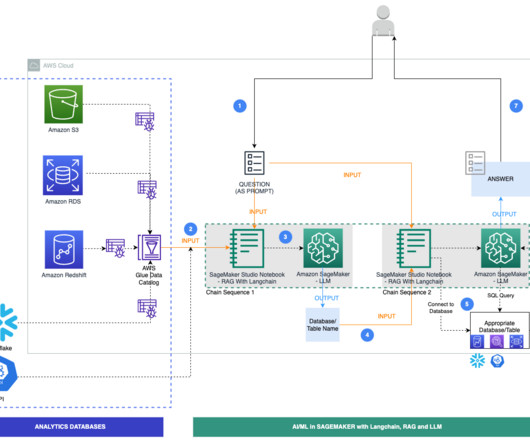
An AWS Glue crawler is scheduled to run at frequent intervals to extract metadata from databases and create table definitions in the AWS Glue Data Catalog. As part of Chain Sequence 1, the prompt and Data Catalog metadata are passed to an LLM, hosted on a SageMaker endpoint, to identify the relevant database and table using LangChain.
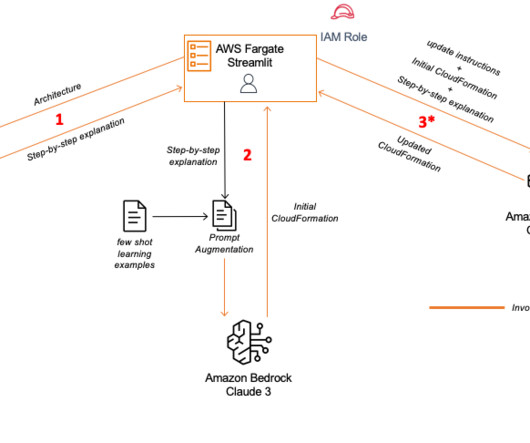
Exposing Anthropic’s Claude 3 Sonnet to multiple CloudFormation templates will allow it to analyze and learn from the structure, resource definitions, parameter configurations, and other essential elements consistently implemented across your organization’s templates. Second, we want to add metadata to the CloudFormation template.
Machine Learning Operations (MLOps): Overview, Definition, and Architecture” By Dominik Kreuzberger, Niklas Kühl, Sebastian Hirschl Great stuff. If you haven’t read it yet, definitely do so. Founded neptune.ai , a modular MLOps component for ML metadata store , aka “experiment tracker + model registry”. Ok, let me explain.
It registers the trained model if it qualifies as a successful model candidate and stores the training artifacts and associated metadata. This walkthrough describes a use case of an MLOps engineer who wants to deploy the pipeline for a recently developed ML model using a simple definition/configuration file that is intuitive.
Use Amazon SageMaker Ground Truth to label data : This guide explains how to use SageMaker Ground Truth for data labeling tasks, including setting up workteams and workforces. You can call the SageMaker ListWorkteams or DescribeWorkteam APIs to view workteams’ metadata, including the WorkerAccessConfiguration.
Building a tool for managing experiments can help your data scientists; 1 Keep track of experiments across different projects, 2 Save experiment-related metadata, 3 Reproduce and compare results over time, 4 Share results with teammates, 5 Or push experiment outputs to downstream systems.
Explainability Provides explanations for its predictions through generated text, offering insights into its decision-making process. The definition of our end-to-end orchestration is detailed in the GitHub repo. The following diagram illustrates the architecture and workflow of the proposed solution.
We’ll walk through the data preparation process, explain the configuration of the time series forecasting model, detail the inference process, and highlight key aspects of the project. All other columns in the dataset are optional and can be used to include additional time-series related information or metadata about each item.
Data should be created using standardized data models, definitions, and quality requirements. A consistent data source, consistent integration, consistent metadata/catalog, consistent orchestration… This is the essence of the data fabric. Data fabric needs metadata management maturity. The domain of the data.
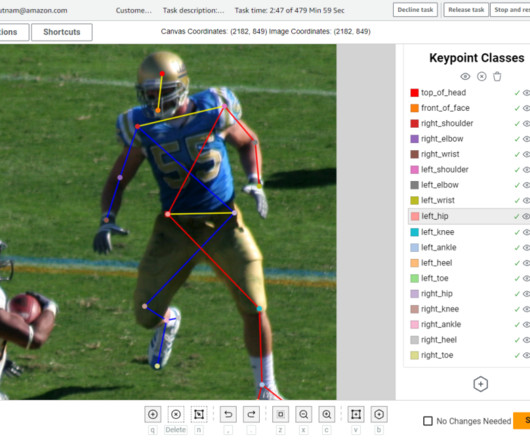
This architecture is comprised of several key components, each of which we explain in more detail in the following sections. The lines between keypoints will be automatically drawn for the user based on a skeleton rig definition that the UI uses. The following is a diagram of the overall architecture.
Tensorflow’s Feature proto definition. Tensorflow’s “Features” proto definition Because our raw data is contained as either BytesList, FloatList, or Int64List and wrapped in a “oneof” Feature proto, that simplifies the map (and thus justifies the design choice). I’m not going to explain it. It’s a key-value data structure.
There are a number of theories that try to explain this effect: When tensor updates are big in size, traffic between workers and the parameter server can get congested. We use HyperbandStrategyConfig to configure StrategyConfig , which is later used by the tuning job definition. in AUC on the validation set.
The result was a significant accuracy boost, with only a minimal amount of time required from subject matter experts (SMEs) to explain how to interpret document language and where to look for key pieces of information. We also discovered that the retrieval system struggled with legal definitions.
The result was a significant accuracy boost, with only a minimal amount of time required from subject matter experts (SMEs) to explain how to interpret document language and where to look for key pieces of information. We also discovered that the retrieval system struggled with legal definitions.
It explains various architectures such as hierarchical, network, and relational models, highlighting their functionalities and importance in efficient data storage, retrieval, and management. DDL Interpreter: It processes Data Definition Language (DDL) statements, which define database system structure.
A what-if analysis helps you investigate and explain how different scenarios might affect the baseline forecast created by Forecast. Forecast can accept three types of datasets: target time series (TTS), related time series (RTS), and item metadata (IM). For What-if forecast definition method , select Use transformation functions.
Michal, to warm you up for all this question-answering, how would you explain to us managing computer vision projects in one minute? Stephen: Definitely sounds a whole like the typical project management dilemma. Stephen: We definitely love war stories in this podcast. Therefore, the list was quite broad, I’d say.
In the context of time series, model monitoring is particularly important as time series data can be highly dynamic because change is definite over time in ways that can impact the accuracy of the model. The function returns the “data” DataFrame with the new column “error percentage” added. We pay our contributors, and we don’t sell ads.
Definition and Purpose Faithfulness in the context of language models, especially in question-answering systems, measures how accurately and reliably the model’s generated answer adheres to the given context or source material. This metric is crucial for applications where the accuracy and relevance of LLM-generated responses are paramount.
In the case of our CI/CD-MLOPs system, we stored the model versions and metadata in the data storage services offered by AWS i.e ML model explainability: Make sure the ML model is interpretable and understandable by the developers as well as other stakeholders and that the value addition provided can be easily quantified. S3 buckets.
link] Constructing a system for NLI that explains its decisions by pointing to the most relevant parts of the input. Five logical rules are listed, based on the definition of entailment. Explainable Prediction of Medical Codes from Clinical Text James Mullenbach, Sarah Wiegreffe, Jon Duke, Jimeng Sun, Jacob Eisenstein.
We can well explain this in a cancer detection example. Using new_from_file only loads image metadata. Pipeline definition Pre-processing pipeline concept Below you can find the definition of our pipeline expressed using Apache Beam. Otherwise, the entire bag is considered negative.
Mikiko Bazeley: You definitely got the details correct. I definitely don’t think I’m an influencer. It will store the features (including definitions and values) and then serve them. There’s no component that stores metadata about this feature store? And so what we do is version the definitions.
Retrieval-Augmented Generation explained I assume I have managed to get your attention by now. Search methods In a vector database, you will typically encounter the following search methods: Full text Used for metadata filtering. What is RAG? You know you can use RAG to anchor a generative model in your company data.
class definition class Student: def __init__(self, fname, lname, age, section): self.firstname = fname self.lastname = lname self.age = age self.section = section # creating a new object stu1 = Student("Sara", "Ansh", 22, "A2") 13. Explain how can you make a Python Script executable on Unix? StopIteration 35.
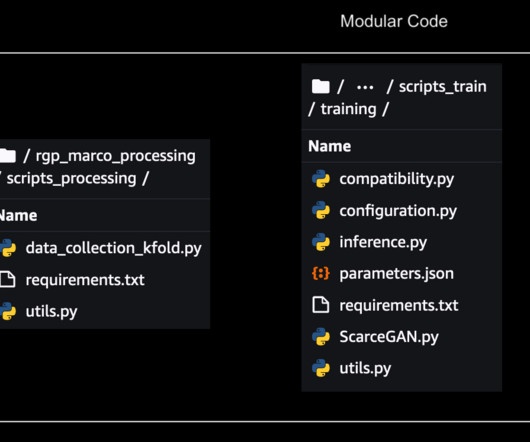
script sets up the autoencoder model hyperparameters and creates an output directory for storing training progress metadata, model weights, and post-training analysis plots. pyimagesearch : is our custom module containing the project’s utility functions, network definition, and configuration variables. The config.py SGD, Adam, etc.).
To make that possible, your data scientists would need to store enough details about the environment the model was created in and the related metadata so that the model could be recreated with the same or similar outcomes. ML metadata and artifact repository. Experimentation component. Model registry.
SageMaker hosting services are used to deploy models, while SageMaker Model Monitor and SageMaker Clarify are used to monitor models for drift, bias, custom metric calculators, and explainability. Proper AWS Identity and Access Management (IAM) role definition for the experimentation workspace was hard to define. Data service.
Proactive agents - AI iterates on linter errors (provided by the Language Server) and pulls in relevant context using go-to-definitions, go-to-references, etc to propose fixes or ask for more context from you. Unite files and metadata together into persistent, versioned, columnar datasets. Filter, join, and group by metadata.
Explainability and Interpretability: Enhancing the explainability and interpretability of LLM decision-making processes can help identify potential instances of alignment faking. Improved Training Methods: Developing more robust and transparent training algorithms. Training models on more diverse and representative datasets.
Common patterns for filtering data include: Filtering on metadata such as the document name or URL. output_first_template = '''Given the classification task definition and the class labels, generate an input that corresponds to each of the class labels. The next step is to filter low quality or desirable documents.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























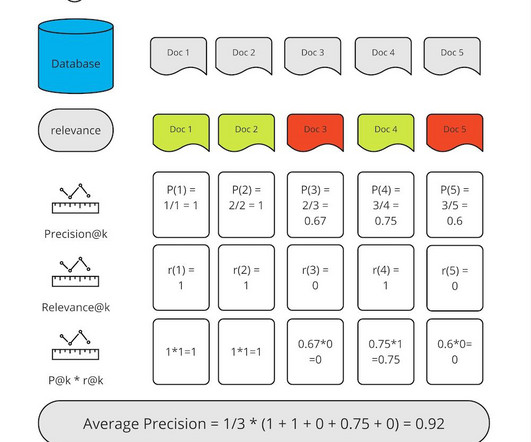





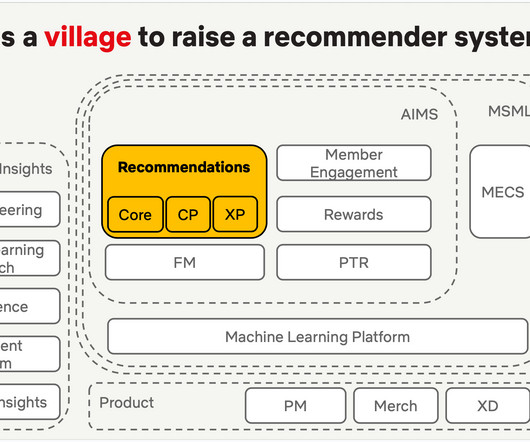







Let's personalize your content