This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In recent years, LargeLanguageModels (LLMs) have significantly redefined the field of artificial intelligence (AI), enabling machines to understand and generate human-like text with remarkable proficiency. The post The Many Faces of Reinforcement Learning: Shaping LargeLanguageModels appeared first on Unite.AI.
Introduction LargeLanguageModels (LLMs) are foundational machine learningmodels that use deeplearning algorithms to process and understand natural language. These models are trained on massive amounts of text data to learn patterns and entity relationships in the language.
Introduction This article covers the creation of a multilingual chatbot for multilingual areas like India, utilizing largelanguagemodels. The system improves consumer reach and personalization by using LLMs to translate questions between local languages and English. appeared first on Analytics Vidhya.
In this article, we’ll explore the journey of creating LargeLanguageModels (LLMs) for ‘Musician’s Intent Recognition’ […] The post Text to Sound – Train Your LargeLanguageModels appeared first on Analytics Vidhya.
In recent years, significant efforts have been put into scaling LMs into LargeLanguageModels (LLMs). In this article, we'll explore the concept of emergence as a whole before exploring it with respect to LargeLanguageModels. What is the cause of these emergent abilities, and what do they mean?
Introduction In today’s digital world, LargeLanguageModels (LLMs) are revolutionizing how we interact with information and services. LLMs are advanced AI systems designed to understand and generate human-like text based on vast amounts of data.
We are going to explore these and other essential questions from the ground up , without assuming prior technical knowledge in AI and machine learning. The problem of how to mitigate the risks and misuse of these AI models has therefore become a primary concern for all companies offering access to largelanguagemodels as online services.
Largelanguagemodels (LLMs) are foundation models that use artificial intelligence (AI), deeplearning and massive data sets, including websites, articles and books, to generate text, translate between languages and write many types of content. The license may restrict how the LLM can be used.
Generative AI has made great strides in the language domain. More recently, the LargeLanguageModel GPT-4 has hit the scene and made ripples for its reported performance, reaching the 90th percentile of human test takers on the Uniform BAR Exam, which is an exam in the United States that is required to become a certified lawyer.
LargeLanguageModels (LLMs) are currently one of the most discussed topics in mainstream AI. These models are AI algorithms that utilize deeplearning techniques and vast amounts of training data to understand, summarize, predict, and generate a wide range of content, including text, audio, images, videos, and more.
AI News spoke with Damian Bogunowicz, a machine learning engineer at Neural Magic , to shed light on the company’s innovative approach to deeplearningmodel optimisation and inference on CPUs. One of the key challenges in developing and deploying deeplearningmodels lies in their size and computational requirements.
has launched ASI-1 Mini, a native Web3 largelanguagemodel designed to support complex agentic AI workflows. Its release sets the foundation for broader innovation within the AI sectorincluding the imminent launch of the Cortex suite, which will further enhance the use of largelanguagemodels and generalised intelligence.
However, traditional deeplearning methods often struggle to interpret the semantic details in log data, typically in natural language. LLMs, like GPT-4 and Llama 3, have shown promise in handling such tasks due to their advanced language comprehension. The evaluation uses metrics such as Precision, Recall, and F1-score.
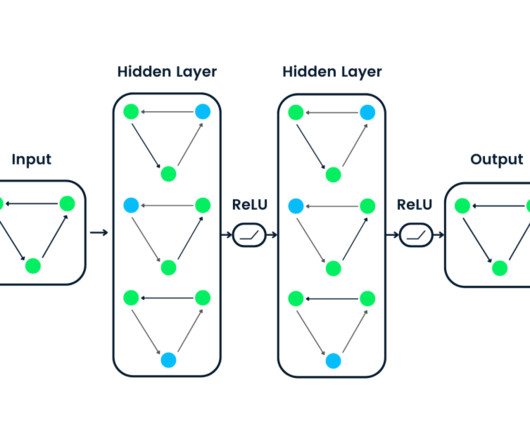
The underpinnings of LLMs like OpenAI's GPT-3 or its successor GPT-4 lie in deeplearning, a subset of AI, which leverages neural networks with three or more layers. These models are trained on vast datasets encompassing a broad spectrum of internet text.
Instead of relying on shrinking transistors, AI employs parallel processing, machine learning , and specialized hardware to enhance performance. Deeplearning and neural networks excel when they can process vast amounts of data simultaneously, unlike traditional computers that process tasks sequentially.
As deeplearningmodels continue to grow, the quantization of machine learningmodels becomes essential, and the need for effective compression techniques has become increasingly relevant. Low-bit quantization is a method that reduces model size while attempting to retain accuracy.
Combining deeplearning-based largelanguagemodels (LLMs) with reasoning synthesis engines, o3 marked a breakthrough where AI transitioned beyond rote memorisation. Its benchmarks are designed not just to measure progress but to inspire new ideas.
Introduction In the field of artificial intelligence, LargeLanguageModels (LLMs) and Generative AI models such as OpenAI’s GPT-4, Anthropic’s Claude 2, Meta’s Llama, Falcon, Google’s Palm, etc., LLMs use deeplearning techniques to perform natural language processing tasks.
Enter generative artificial intelligence (GenAI) , which is a subset of AI technologies that uses largelanguagemodels (LLMs) to learn patterns from large datasets. Our formula for successful integration of GenAI is to start with deeplearningmodels trained specifically on large banking datasets.
The emergence of Mixture of Experts (MoE) architectures has revolutionized the landscape of largelanguagemodels (LLMs) by enhancing their efficiency and scalability. This innovative approach divides a model into multiple specialized sub-networks, or “experts,” each trained to handle specific types of data or tasks.
Graph Neural Networks (GNNs) have emerged as a powerful deeplearning framework for graph machine learning tasks. In parallel, LargeLanguageModels (LLMs) like GPT-4, and LLaMA have taken the world by storm with their incredible natural language understanding and generation capabilities.
Introduction Welcome to the world of LargeLanguageModels (LLM). In the old days, transfer learning was a concept mostly used in deeplearning. This paper explored models using fine-tuning and transfer learning.
The need for specialized AI accelerators has increased as AI applications like machine learning, deeplearning , and neural networks evolve. Huawei vs. NVIDIA: The Battle for AI Supremacy NVIDIA has long been the leader in AI computing, with its GPUs serving as the standard for machine learning and deeplearning tasks.
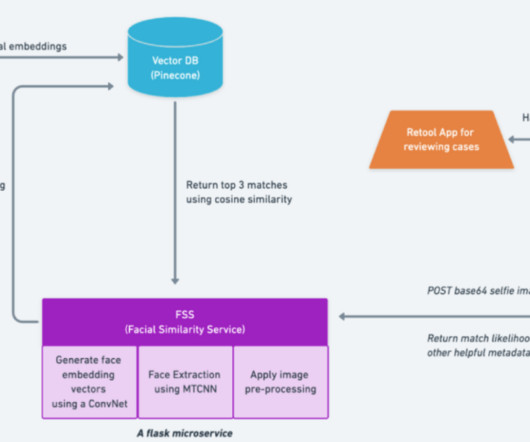
These representations are the vector embeddings generated by the Embedding Models. The vector stores have become an integral part of developing apps with DeepLearningModels, especially the LargeLanguageModels.
Largelanguagemodels (LLMs) like GPT-4, DALL-E have captivated the public imagination and demonstrated immense potential across a variety of applications. The sheer scale of these models, combined with advanced deeplearning techniques, enables them to achieve state-of-the-art performance on language tasks.
Much of what the tech world has achieved in artificial intelligence (AI) today is thanks to recent advances in deeplearning, which allows machines to learn automatically during training.
Introduction LargeLanguageModels have been the backbone of advancement in the AI domain. With the release of various Open source LLMs, the need for ChatBot-specific use cases has grown in demand.
Training and running largelanguagemodels (LLMs) requires vast computational power and equally vast amounts of energy. What makes Lumais approach truly novel is its use of 3D optical matrix-vector multiplication (MVM) a key operation in deeplearning carried out in free space.
Everybody at NVIDIA is incentivized to figure out how to work together because the accelerated computing work that NVIDIA does requires full-stack optimization, said Bryan Catanzaro, vice president of applied deeplearning research at NVIDIA. You have to work together as one team to achieve acceleration.
Introduction LargeLanguageModels (LLMs) are crucial in various applications such as chatbots, search engines, and coding assistants. Batching, a key technique, helps manage […] The post LLMs Get a Speed Boost: New Tech Makes Them BLAZING FAST!
Artificial Intelligence (AI) is evolving at an unprecedented pace, with large-scale models reaching new levels of intelligence and capability. From early neural networks to todays advanced architectures like GPT-4 , LLaMA , and other LargeLanguageModels (LLMs) , AI is transforming our interaction with technology.
The fast progress in AI technologies like machine learning, neural networks , and LargeLanguageModels (LLMs) is bringing us closer to ASI. AGI, still under development, seeks to create machines that can think, learn, and comprehend a variety of functions like human abilities.
What Is Ollama and the Ollama API Functionality Ollama is an open-source framework that enables developers to run largelanguagemodels (LLMs) like Llama 3.2 It offers a lightweight, extensible platform for building and managing languagemodels, providing a simple API for creating, running, and managing models.
Recommended Open-Source AI Platform: IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System (Promoted) The post Meta AI Introduces Brain2Qwerty: A New DeepLearningModel for Decoding Sentences from Brain Activity with EEG or MEG while Participants Typed Briefly Memorized Sentences on a QWERTY Keyboard appeared (..)
Introduction One of the most popular applications of largelanguagemodels (LLMs) is to answer questions about custom datasets. LLMs like ChatGPT and Bard are excellent communicators. They can answer almost anything that they have been trained on. This is also one of the biggest bottlenecks for LLMs.
Our results indicate that, for specialized healthcare tasks like answering clinical questions or summarizing medical research, these smaller models offer both efficiency and high relevance, positioning them as an effective alternative to larger counterparts within a RAG setup.
This principle applies across various model classes, showing that deeplearning isn’t fundamentally different from other approaches. However, deeplearning remains distinctive in specific aspects. Recent research confirms that these phenomena apply to linear models. Check out the Paper.
They avoid the hassles of expensive fine-tuning of LargeLanguageModels (LLMs). Introduction Retrieval Augmented Generation systems, better known as RAG systems, have quickly become popular for building Generative AI assistants on custom enterprise data.
As the demand for largelanguagemodels (LLMs) continues to rise, ensuring fast, efficient, and scalable inference has become more crucial than ever. Accelerating AI Workloads with TensorRT TensorRT accelerates deeplearning workloads by incorporating precision optimizations such as INT8 and FP16.
Google researchers have unveiled TransformerFAM, a novel architecture set to revolutionize long-context processing in largelanguagemodels (LLMs). By integrating a feedback loop mechanism, TransformerFAM promises to enhance the network’s ability to handle infinitely long sequences.
Introduction Artificial intelligence has made tremendous strides in Natural Language Processing (NLP) by developing LargeLanguageModels (LLMs). These models, like GPT-3 and GPT-4, can generate highly coherent and contextually relevant text.
Their extensive experience in deeplearningmodels and large-scale infrastructure management led to the development of a state-of-the-art platform as a service (PaaS), built to eliminate AI deployment bottlenecks and streamline machine learning workflows.
Introduction LargeLanguageModels (LLMs) are advanced natural language processing models that have achieved remarkable success in various benchmarks for mathematical reasoning. LLMs are typically trained on large datasets scraped from […] The post LLMs Exposed: Are They Just Cheating on Math Tests?
NVIDIA today announced Nemotron-4 340B, a family of open models that developers can use to generate synthetic data for training largelanguagemodels (LLMs) for commercial applications across healthcare, finance, manufacturing, retail and every other industry.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content