This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using the Ollama API (this tutorial) To learn how to build a multimodal chatbot with Gradio, Llama 3.2, Jump Right To The Downloads Section What Is Gradio and Why Is It Ideal for Chatbots? Model Management: Easily download, run, and manage various models, including Llama 3.2 and the Ollama API, just keep reading.
This enables the efficient processing of content, including scientific formulas and data visualizations, and the population of Amazon Bedrock Knowledge Bases with appropriate metadata. Generate metadata for the page. Generate metadata for the full document. Upload the content and metadata to Amazon S3.
This archive includes over 24 million image-text pairs from 6 million articles enriched with metadata and expert annotations. Articles and media files are downloaded from the NCBI server, extracting metadata, captions, and figure references from nXML files and the Entrez API.
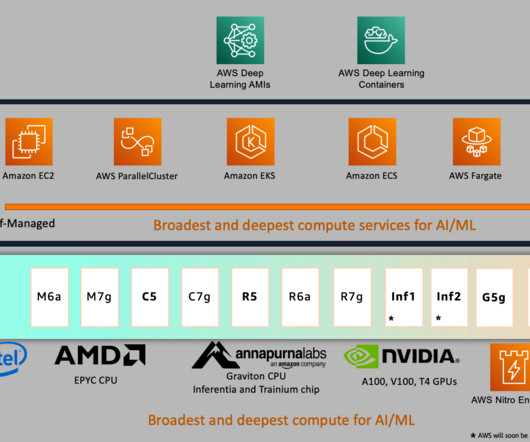
Trainium chips are purpose-built for deeplearning training of 100 billion and larger parameter models. Model training on Trainium is supported by the AWS Neuron SDK, which provides compiler, runtime, and profiling tools that unlock high-performance and cost-effective deeplearning acceleration. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
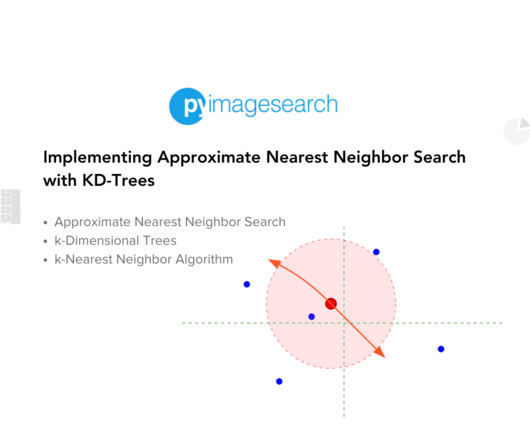
This lesson is the 1st in a 2-part series on Mastering Approximate Nearest Neighbor Search : Implementing Approximate Nearest Neighbor Search with KD-Trees (this tutorial) Approximate Nearest Neighbor with Locality Sensitive Hashing (LSH) To learn how to implement an approximate nearest neighbor search using KD-Tree , just keep reading.
Even today, a vast chunk of machine learning and deeplearning techniques for AI models rely on a centralized model that trains a group of servers that run or train a specific model against training data, and then verifies the learning using validation or training dataset.
Download the model and its components WhisperX is a system that includes multiple models for transcription, forced alignment, and diarization. For smooth SageMaker operation without the need to fetch model artifacts during inference, it’s essential to pre-download all model artifacts. __dict__[WAV2VEC2_MODEL].get_model(dl_kwargs={"model_dir":
Big foundational models like CLIP, Stable Diffusion, and Flamingo have radically improved multimodal deeplearning over the past few years. Multimodal deeplearning, as of 2023, is still primarily concerned with text-image modeling, with only limited attention paid to additional modalities like video (and audio).
In this section, you will see different ways of saving machine learning (ML) as well as deeplearning (DL) models. Saving deeplearning model with TensorFlow Keras TensorFlow is a popular framework for training DL-based models, and Ker as is a wrapper for TensorFlow. Now let’s see how we can save our model.
Carl Froggett, is the Chief Information Officer (CIO) of Deep Instinct , an enterprise founded on a simple premise: that deeplearning , an advanced subset of AI, could be applied to cybersecurity to prevent more threats, faster. What makes our model unique is it does not need data or files from customers to learn and grow.
When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Can you compare images?
Note: Downloading the dataset takes 1.2 If you don’t want to download the whole dataset, you can simply pass in the streaming=True argument to create an iterable dataset where samples are downloaded as you iterate over them. Now, let’s download the dataset from the ? GB of disk space. labels in the dataset).
In October 2022, we launched Amazon EC2 Trn1 Instances , powered by AWS Trainium , which is the second generation machine learning accelerator designed by AWS. Trn1 instances are purpose built for high-performance deeplearning model training while offering up to 50% cost-to-train savings over comparable GPU-based instances.
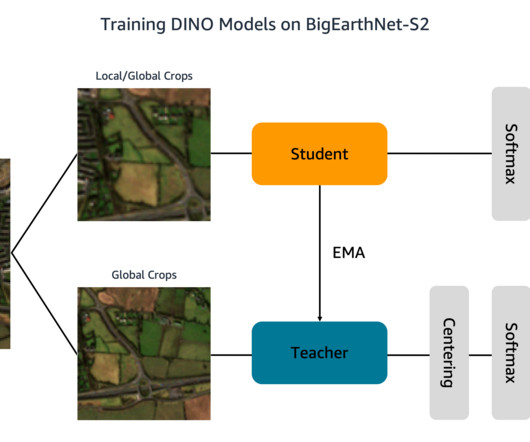
We start by downloading the dataset from the terminal of our SageMaker notebook instance: wget [link] tar -xvf BigEarthNet-S2-v1.0.tar.gz Additionally, each folder contains a JSON file with the image metadata. We store the BigEarthNet-S2 images and metadata file in an S3 bucket. The dataset has a size of about 109 GB.
Download the Amazon SageMaker FAQs When performing the search, look for Answers only, so you can drop the Question column. Since we top_k = 1 , index.query returned the top result along side the metadata which reads Managed Spot Training can be used with all instances supported in Amazon.
This post further walks through a step-by-step implementation of fine-tuning a RoBERTa (Robustly Optimized BERT Pretraining Approach) model for sentiment analysis using AWS DeepLearning AMIs (AWS DLAMI) and AWS DeepLearning Containers (DLCs) on Amazon Elastic Compute Cloud (Amazon EC2 p4d.24xlarge)
Noise: The metadata associated with the content doesn’t have a well-defined ontology. To address all these challenges, YouTube employs a two-stage deeplearning-based recommendation strategy that trains large-scale models (with approximately one billion parameters) on hundreds of billions of examples. That’s not the case.
All of this is delivered by HealthOmics, removing the burden of managing compression, tiering, metadata, and file organization from customers. SageMaker notably supports popular deeplearning frameworks, including PyTorch, which is integral to the solutions provided here.
This lesson is the 3rd in our series on OAK 102 : Training the YOLOv8 Object Detector for OAK-D Hand Gesture Recognition with YOLOv8 on OAK-D in Near Real-Time People Counter on OAK (this tutorial) To learn how to implement and run people counting on OAK, just keep reading. Looking for the source code to this post? mp4 │ └── example_02.mp4
In this phase, you submit a text search query or image search query through the deeplearning model (CLIP) to encode as embeddings. The dataset is a collection of 147,702 product listings with multilingual metadata and 398,212 unique catalogue images. We use the first metadata file in this demo. contains image metadata.
Stable Diffusion XL by Stability AI is a high-quality text-to-image deeplearning model that allows you to generate professional-looking images in various styles. Download the code to your SageMaker Studio environment Run the following commands from the terminal. as the base model. Each pipeline takes a single dataset as input.
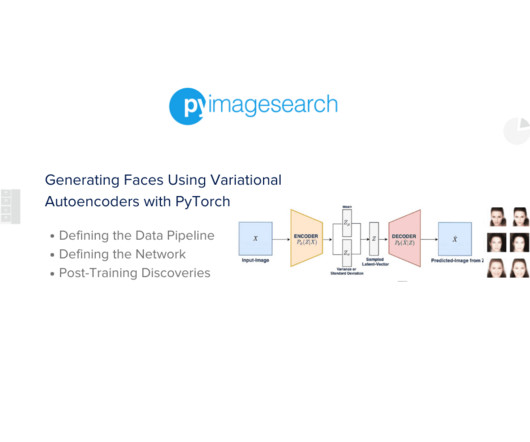
Jump Right To The Downloads Section A Deep Dive into Variational Autoencoder with PyTorch Introduction Deeplearning has achieved remarkable success in supervised tasks, especially in image recognition. Start by accessing this tutorial’s “Downloads” section to retrieve the source code and example images.
Recent developments in deeplearning have led to increasingly large models such as GPT-3, BLOOM, and OPT, some of which are already in excess of 100 billion parameters. Many enterprise customers choose to deploy their deeplearning workloads using Kubernetes—the de facto standard for container orchestration in the cloud.
A feature store typically comprises a feature repository, a feature serving layer, and a metadata store. The metadata store manages the metadata associated with each feature, such as its origin and transformations. The feature repository is essentially a database storing pre-computed and versioned features.
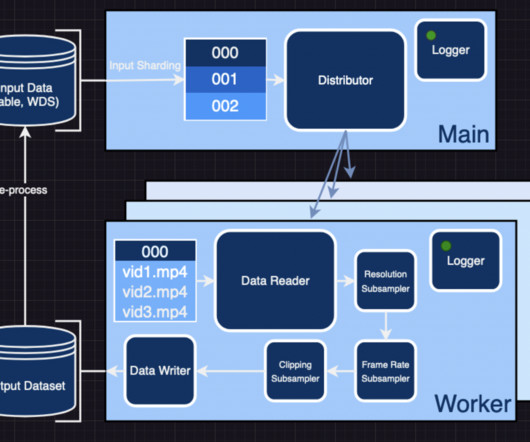
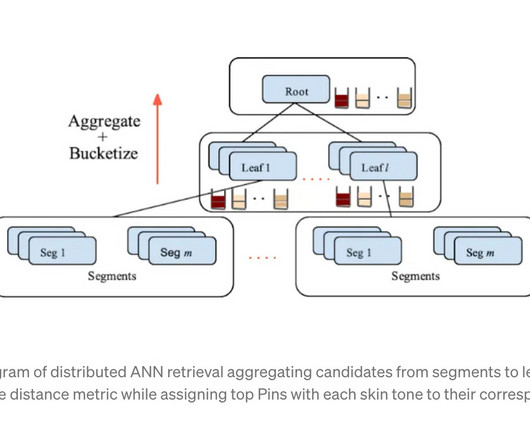
We downloaded the data from AWS Data Exchange and processed it in AWS Glue to generate KG files. This mapping can be done by manually mapping frequent OOC queries to catalog content or can be automated using machine learning (ML). The following diagram illustrates the complete architecture implemented as part of this series.
This includes various products related to different aspects of AI, including but not limited to tools and platforms for deeplearning, computer vision, natural language processing, machine learning, cloud computing, and edge AI. The platform is easy to learn and use, even if you aren’t a specialized professional.
Learn how to use Kangas with the HuggingFace Hub by watching this quick video. Once downloaded in your .cache Image from Author Through the get_schema() , as shown in the above image, we can get information about how is set the data and metadata of our DataGrid and also the data types of each of them. Here is the answer to that.
TensorRT is an SDK developed by NVIDIA that provides a high-performance deeplearning inference library. It’s optimized for NVIDIA GPUs and provides a way to accelerate deeplearning inference in production environments. Input and output – These fields are required because NVIDIA Triton needs metadata about the model.
This lesson is the 2nd of a 4-part series on Autoencoders : Introduction to Autoencoders Implementing a Convolutional Autoencoder with PyTorch (this tutorial) Lesson 3 Lesson 4 To learn to train convolutional autoencoders in PyTorch with post-training embedding analysis on the Fashion-MNIST dataset, just keep reading. The config.py
Each model deployed with Triton requires a configuration file ( config.pbtxt ) that specifies model metadata, such as input and output tensors, model name, and platform. For a list of NVIDIA Triton DeepLearning Containers (DLCs) supported by SageMaker inference, refer to Available DeepLearning Containers Images.
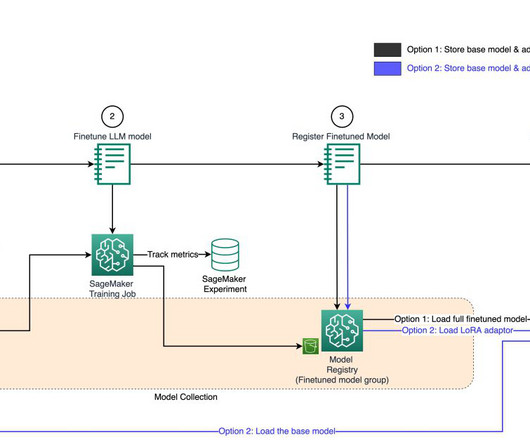
Each works through a different way to handle LoRA fine-tuned models as illustrated in the following diagram: First, we download the pre-trained Llama2 model with 7 billion parameters using SageMaker Studio Notebooks. They can also use SageMaker Experiments to download the created charts and share the model evaluation with their stakeholders.
skills and industry) and course metadata (e.g., Collaborative Filtering Typically there are three collaborative filtering algorithms: user-item-based utility, matrix factorization technique, and deep neural network-based approach. course difficulty, category, and skills). LinkedIn Engineering ). That’s not the case.
This is the 2nd lesson in our 4-part series on OAK-101 : Introduction to OpenCV AI Kit (OAK) OAK-D: Understanding and Running Neural Network Inference with DepthAI API (today’s tutorial) OAK 101: Part 3 OAK 101: Part 4 To learn how DepthAI API works and run neural network inference on OAK-D, just keep reading.
Open-source models are (in general) always fine-tunable because the model artifacts are available for downloading and the users are able to extend and use them at will. The journey of providers FM providers need to train FMs, such as deeplearning models. Proprietary models might sometimes offer the option of fine-tuning.
Also, it allows you to break-down the engagement and intermediate labeling strategies well if you have a very good tooling to capture variety of activities(time spent, language, and other types of metadata) that are hard to capture otherwise in real world. The models within PrimeQA supports End-to-end Question Answering.
Users have to built their own layer on top of Airflow to track experiment metadata, input and outputs of pipeline steps, code, data, configuration, etc. Thirdly, without dedicated attention, GPUs will often sit idle while data is being downloaded and loaded into memory. Airflow does not guarantee a strong traceability of assets.
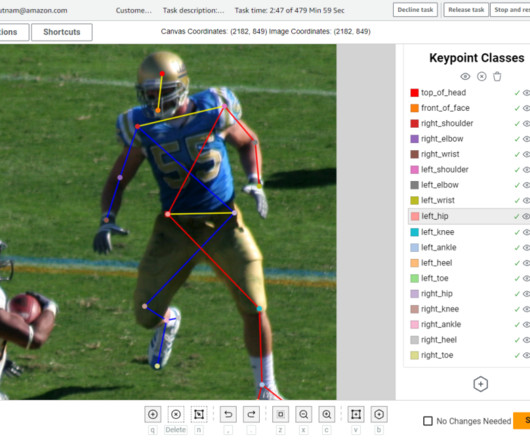
The annotations or labels created by the labeling workforce are then exported to an Amazon Simple Storage Service (Amazon S3) bucket, where they can be used for downstream processes like training deeplearning computer vision models. This script downloads a set of 10 images, which we use in our example labeling job.
While various machine learning and deeplearning algorithms have been developed to carry out this task, I found YOLOv8, released in January 2023, to be the most accurate and fast model. The internet is overflooded with videos, making it tedious to search for them if there is no mechanism to classify and organize such data.
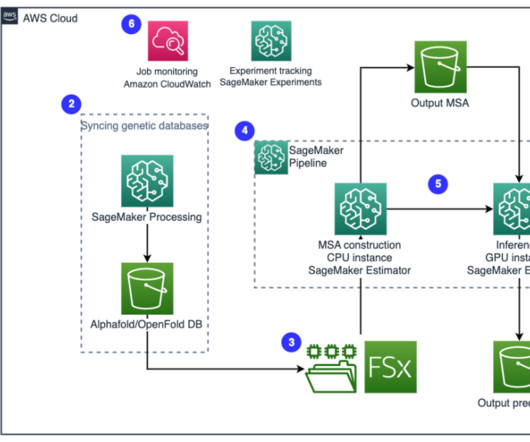
Recent advances in deeplearning methods for protein research have shown promise in using neural networks to predict protein folding with remarkable accuracy. Job output such as MSA files, predicted pdb structure files, and other metadata files are saved in a specified S3 location. amazonaws.com/sagemaker-studio-alphafold:v2.3.0'
Each item has rich metadata (e.g., And it goes on to personalize title images, trailers, metadata, synopsis, etc. Machine learning (ML) approaches can be used to learn utility functions by training it on historical data of which home pages have been created for members (i.e., genre, actors, director, year, popularity).
Jump Right To The Downloads Section Configuring Your Development Environment To follow this guide, you need to have numpy , Pillow , torch , torchvision , matplotlib , pandas , scipy , and imageio libraries installed on your system. Start by accessing this tutorial’s “Downloads” section to retrieve the source code and example images.
FSx for Lustre uses distributed file storage (stripping) and physically separates file metadata from file content to achieve high-performance read/writes. Gili Nachum is a senior AI/ML Specialist Solutions Architect who works as part of the EMEA Amazon Machine Learning team. In his spare time, Gili enjoy playing table tennis.
Recent years have shown amazing growth in deeplearning neural networks (DNNs). In Steps 1–5, we download and prepare the data, create the xgb3 estimator (the distributed XGBoost estimator is set to use three instances), run the training jobs, and observe the results. International Conference on Machine Learning.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content