This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
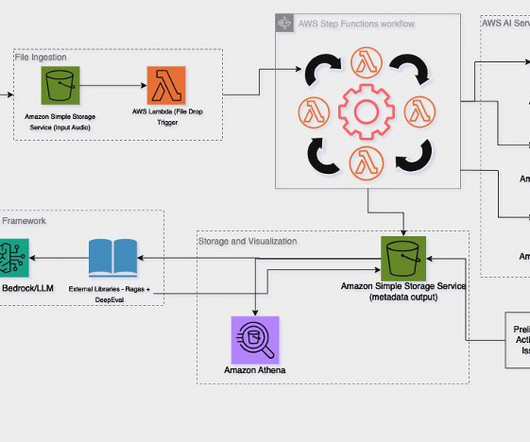
One effective way to improve context relevance is through metadata filtering, which allows you to refine search results by pre-filtering the vector store based on custom metadata attributes. By combining the capabilities of LLM function calling and Pydantic data models, you can dynamically extract metadata from user queries.
This enables the efficient processing of content, including scientific formulas and data visualizations, and the population of Amazon Bedrock Knowledge Bases with appropriate metadata. Generate metadata for the page. Generate metadata for the full document. Upload the content and metadata to Amazon S3.
Recently, we’ve been witnessing the rapid development and evolution of generative AI applications, with observability and evaluation emerging as critical aspects for developers, datascientists, and stakeholders.
To refine the search results, you can filter based on document metadata to improve retrieval accuracy, which in turn leads to more relevant FM generations aligned with your interests. With this feature, you can now supply a custom metadata file (each up to 10 KB) for each document in the knowledge base. Virginia) and US West (Oregon).
However, information about one dataset can be in another dataset, called metadata. Without using metadata, your retrieval process can cause the retrieval of unrelated results, thereby decreasing FM accuracy and increasing cost in the FM prompt token. This change allows you to use metadata fields during the retrieval process.
But trust isn’t important only for executives; before executive trust can be established, datascientists and citizen datascientists who create and work with ML models must have faith in the data they’re using. This can lead to more accurate predictions and better decision-making.
With metadata filtering now available in Knowledge Bases for Amazon Bedrock, you can define and use metadata fields to filter the source data used for retrieving relevant context during RAG. This helps improve the relevance and quality of retrieved context while reducing potential hallucinations or noise from irrelevant data.
Illumex enables organizations to deploy genAI analytics agents by translating scattered, cryptic data into meaningful, context-rich business language with built-in governance. By creating business terms, suggesting metrics, and identifying potential conflicts, Illumex ensures data governance at the highest standards.
Introduction The purpose of a data warehouse is to combine multiple sources to generate different insights that help companies make better decisions and forecasting. It consists of historical and commutative data from single or multiple sources. Most datascientists, big data analysts, and business […].
We’ve compiled six key reasons why financial organizations are turning to lineage platforms like MANTA to get control of their data. Download the Gartner® Market Guide for Active Metadata Management 1. MANTA customers have used data lineage to complete their migration projects 40% faster with 30% fewer resources.
For instance, according to International Data Corporation (IDC), the world’s data volume is expected to increase tenfold by 2025, with unstructured data accounting for a significant portion. The custom metadata helps organizations and enterprises categorize information in their preferred way.
A lakehouse should make it easy to combine new data from a variety of different sources, with mission critical data about customers and transactions that reside in existing repositories. Also, a lakehouse can introduce definitional metadata to ensure clarity and consistency, which enables more trustworthy, governed data.
Most datascientists are familiar with the concept of time series data and work with it often. The time series database (TSDB) , however, is still an underutilized tool in the data science community. Editor’s note: Jeff Tao is a speaker for ODSC West 2023 this Fall.
It stores information such as job ID, status, creation time, and other metadata. The following is a screenshot of the DynamoDB table where you can track the job status and other types of metadata related to the job. The DynamoDB table is crucial for tracking and managing the batch inference jobs throughout their lifecycle.
Connecting AI models to a myriad of data sources across cloud and on-premises environments AI models rely on vast amounts of data for training. Once trained and deployed, models also need reliable access to historical and real-time data to generate content, make recommendations, detect errors, send proactive alerts, etc.
At IBM, we believe it is time to place the power of AI in the hands of all kinds of “AI builders” — from datascientists to developers to everyday users who have never written a single line of code. Watsonx, IBM’s next-generation AI platform, is designed to do just that. Watsonx.ai Watsonx.ai
The LightAutoML framework is deployed across various applications, and the results demonstrated superior performance, comparable to the level of datascientists, even while building high-quality machine learning models. The LightAutoML framework attempts to make the following contributions.
Data engineers contribute to the data lineage process by providing the necessary information and metadata about the data transformations they perform. Amazon DataZone plays a crucial role in maintaining data lineage information, enabling traceability and impact analysis of data transformations across the organization.
Employees and managers see different levels of company policy information, with managers getting additional access to confidential data like performance review and compensation details. The role information is also used to configure metadata filtering in the knowledge bases to generate relevant responses.
The evaluation framework, call metadata generation, and Amazon Q in QuickSight were new components introduced from the original PCA solution. Ragas and a human-in-the-loop UI (as described in the customer blogpost with Tealium) were used to evaluate the metadata generation and individual call Q&A portions.
DataScientist at AWS, bringing a breadth of data science, ML engineering, MLOps, and AI/ML architecting to help businesses create scalable solutions on AWS. He is a technology enthusiast and a builder with a core area of interest in AI/ML, data analytics, serverless, and DevOps. About the Authors Joe King is a Sr.
Datascientist experience Datascientists are the second persona interacting with SageMaker HyperPod clusters. Datascientists are responsible for the training, fine-tuning, and deployment of models on accelerated compute instances. metadata: name: job-name namespace: hyperpod-ns-researchers labels: kueue.x-k8s.io/queue-name:
The steering committee or governance council can establish data governance policies around privacy, retention, access and security while defining data management standards to streamline processes and certify consistency and compliance as new data is introduced.
An enterprise data catalog does all that a library inventory system does – namely streamlining data discovery and access across data sources – and a lot more. For example, data catalogs have evolved to deliver governance capabilities like managing data quality and data privacy and compliance.
Some popular end-to-end MLOps platforms in 2023 Amazon SageMaker Amazon SageMaker provides a unified interface for data preprocessing, model training, and experimentation, allowing datascientists to collaborate and share code easily. It provides a high-level API that makes it easy to define and execute data science workflows.
From Solo Notebooks to Collaborative Powerhouse: VS Code Extensions for Data Science and ML Teams Photo by Parabol | The Agile Meeting Toolbox on Unsplash In this article, we will explore the essential VS Code extensions that enhance productivity and collaboration for datascientists and machine learning (ML) engineers.
It involves breaking down the document into its constituent parts, such as text, tables, images, and metadata, and identifying the relationships between these elements. Metadata customization for.csv files Knowledge Bases for Amazon Bedrock now offers an enhanced.csv file processing feature that separates content and metadata.
This blog explores their strategies, including custom chunking techniques, hybrid retrieval methods, and robust development frameworks designed for seamless collaboration between datascientists and machine learning engineers. Metadata tagging and filtering mechanisms safeguard proprietary data.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities. Later this year, it will leverage watsonx.ai
It automatically keeps track of model artifacts, hyperparameters, and metadata, helping you to reproduce and audit model versions. After being tested locally or as a training job, a datascientist or practitioner who is an expert on SageMaker can convert the function to a SageMaker pipeline step by adding a @step decorator.
To measure and maintain high-quality data, organizations use data quality rules, also known as data validation rules, to ensure datasets meet criteria as defined by the organization. Additional time is saved that would have otherwise been wasted on acting on incomplete or inaccurate data.
This involves unifying and sharing a single copy of data and metadata across IBM® watsonx.data ™, IBM® Db2 ®, IBM® Db2® Warehouse and IBM® Netezza ®, using native integrations and supporting open formats, all without the need for migration or recataloging. . Netezza
Because of the platform’s versatility in handling different document kinds and layouts, datascientists may effectively preprocess data at scale without being constrained by issues with format or cleaning. The main features of the platform which are meant to make data workflows more efficient are as follows.
In addition, the Amazon Bedrock Knowledge Bases team worked closely with us to address several critical elements, including expanding embedding limits, managing the metadata limit (250 characters), testing different chunking methods, and syncing throughput to the knowledge base.
With 2,400+ expertly curated datasets that span healthcare, medical terminology, life sciences, and societal sectors, this massive data library promises to revolutionize the capabilities of datascientists across the industry. The data is regularly updated, and is available in a variety of formats with enriched metadata.
Introduction to AI and Machine Learning on Google Cloud This course introduces Google Cloud’s AI and ML offerings for predictive and generative projects, covering technologies, products, and tools across the data-to-AI lifecycle.
Enterprises seeking to harness the power of AI must establish a data pipeline that involves extracting data from diverse sources, transforming it into a consistent format and storing it efficiently. The company found that datascientists were having to remove features from algorithms just so they would run to completion.
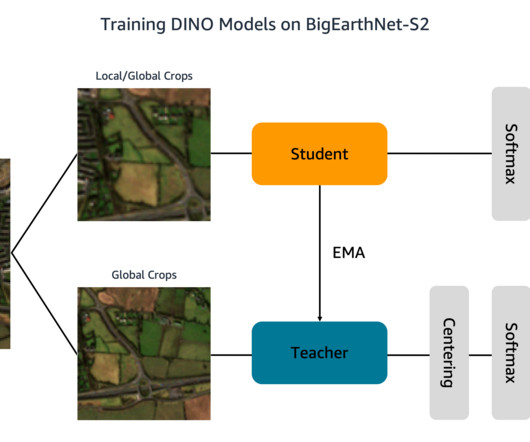
Additionally, each folder contains a JSON file with the image metadata. A detailed description of the data is provided in the BigEarthNet Guide. To perform statistical analyses of the data and load images during DINO training, we process the individual metadata files into a common geopandas Parquet file. during training.
Amazon DataZone allows you to create and manage data zones , which are virtual data lakes that store and process your data, without the need for extensive coding or infrastructure management. Solution overview In this section, we provide an overview of three personas: the data admin, data publisher, and datascientist.
FMEval is an open source LLM evaluation library, designed to provide datascientists and machine learning (ML) engineers with a code-first experience to evaluate LLMs for various aspects, including accuracy, toxicity, fairness, robustness, and efficiency. This allows you to keep track of your ML experiments.
Traditionally, developing appropriate data science code and interpreting the results to solve a use-case is manually done by datascientists. For example, generating code to prepare data as well as train and deploy a model. Datascientists still need to review and evaluate these results.
As a result, it’s easier to find problems with data quality, inconsistencies, and outliers in the dataset. Metadata analysis is the first step in establishing the association, and subsequent steps involve refining the relationships between individual database variables.
Datascientists from ML teams across different business units federate into their team’s development environment to build the model pipeline. Datascientists search and pull features from the central feature store catalog, build models through experiments, and select the best model for promotion.
This is part of the Full Stack DataScientist blog series. Building end-to-end data science solutions means developing data collection, feature engineering, model building and model serving processes. It’s overwhelming at first, so let’s just focus on the main part development as the ‘Data Engineer’ — DAGS.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content