This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
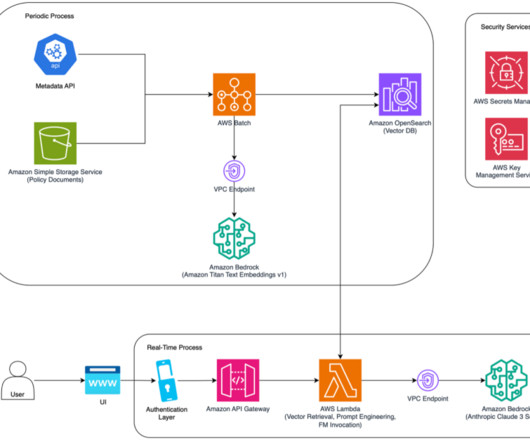
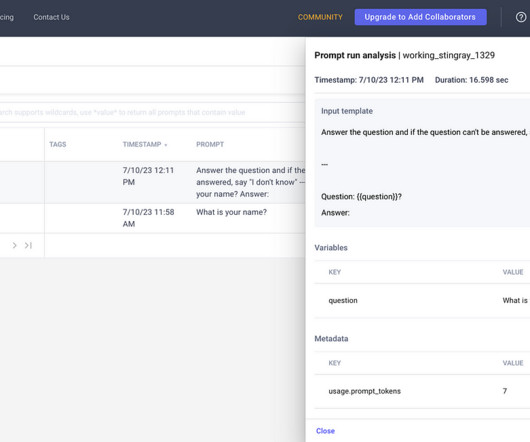
Along with each document slice, we store the metadata associated with it using an internal Metadata API, which provides document characteristics like document type, jurisdiction, version number, and effective dates. Prompt optimization The change summary is different than showing differences in text between the two documents.
Introduction PromptEngineering is arguably the most critical aspect in harnessing the power of Large Language Models (LLMs) like ChatGPT. However; current promptengineering workflows are incredibly tedious and cumbersome. Logging prompts and their outputs to .csv First install the package via pip.
Evolving Trends in PromptEngineering for Large Language Models (LLMs) with Built-in Responsible AI Practices Editor’s note: Jayachandran Ramachandran and Rohit Sroch are speakers for ODSC APAC this August 22–23. You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
By supporting open-source frameworks and tools for code-based, automated and visual datascience capabilities — all in a secure, trusted studio environment — we’re already seeing excitement from companies ready to use both foundation models and machine learning to accomplish key tasks.
Prompt catalog – Crafting effective prompts is important for guiding large language models (LLMs) to generate the desired outputs. Promptengineering is typically an iterative process, and teams experiment with different techniques and prompt structures until they reach their target outcomes.
This post highlights how Twilio enabled natural language-driven data exploration of business intelligence (BI) data with RAG and Amazon Bedrock. Twilio’s use case Twilio wanted to provide an AI assistant to help their data analysts find data in their data lake.
With built-in components and integration with Google Cloud services, Vertex AI simplifies the end-to-end machine learning process, making it easier for datascience teams to build and deploy models at scale. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy datascience projects.
This post walks through examples of building information extraction use cases by combining LLMs with promptengineering and frameworks such as LangChain. PromptengineeringPromptengineering enables you to instruct LLMs to generate suggestions, explanations, or completions of text in an interactive way.
Considering the nature of the time series dataset, Q4 also realized that it would have to continuously perform incremental pre-training as new data came in. This would have required a dedicated cross-disciplinary team with expertise in datascience, machine learning, and domain knowledge.
These teams are as follows: Advanced analytics team (data lake and data mesh) – Dataengineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
You’ll also be introduced to promptengineering, a crucial skill for optimizing AI interactions. You’ll explore data ingestion from multiple sources, preprocessing unstructured data into a normalized format that facilitates uniform chunking across various file types, and metadata extraction.
We use promptengineering to send our summarization instructions to the LLM. Importantly, when performed, summarization should preserve as much article’s metadata as possible, such as the title, authors, date, etc. Data Scientist with 8+ years of experience in DataScience and Machine Learning.
Be sure to check out his talk, “ Prompt Optimization with GPT-4 and Langchain ,” there! The difference between the average person using AI and a PromptEngineer is testing. Most people run a prompt 2–3 times and find something that works well enough.
.” – Zain Hasan, Senior ML Developer Advocate at Weaviate “An under-discussed yet crucial question is how to ensure that LLMs can be trained in a way that respects user privacy and does not rely on exploiting vast amounts of personal data.” solves this problem by extracting metadata during the data preparation process.
The fields of AI and datascience are changing rapidly and ODSC West 2024 is evolving to ensure we keep you at the forefront of the industry with our all-new tracks, AI Agents , What’s Next in AI, and AI in Robotics , and our updated tracks NLP, NLU, and NLG , and Multimodal and Deep Learning , and LLMs and RAG.
Additionally, evaluation can identify potential biases, hallucinations, inconsistencies, or factual errors that may arise from the integration of external sources or from sub-optimal promptengineering. In this case, the model choice needs to be revisited or further promptengineering needs to be done.
Comet’s LLMOps tool provides an intuitive and responsive view of our prompt history. Prompt Playground: With the LLMOps tool comes the new Prompt Playground, which allows PromptEngineers to iterate quickly with different Prompt Templates and understand the impact on different contexts.
Preceded by data analysis and feature engineering, a model is trained and ready to be productionized. We may observe a growing awareness among machine learning and datascience practitioners of the crucial role played by pre- and post-training activities. But what happens next? What is LLMOps?
LangChain loads training data in the form of ‘Documents’, and these contain text from various sources and their respective metadata. The `Document` class provides various document loader methods to load data from sources, including PDF, HTML, JSON, and CSV. The rest are optional like prompt template, metadata, tags, etc.
Users can gain deep insights into the evolution of their prompts and responses. Prompt Playground Adventure: Within the LLMOps toolkit lies the innovative Prompt Playground, a dynamic space where PromptEngineers can embark on expedited explorations. comet_llm.log_prompt( prompt="Hey,What's your name?
Document Loaders Document loaders in LangChain are used to load data from various sources as Document objects. A Document is a piece of text with associated metadata. Document loaders provide a convenient way to fetch data from different sources, such as text files, web pages, or even transcripts of videos.
metadata : (Optional) Additional metadata to associate with the evaluation. Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for datascience, machine learning, and deep learning practitioners. kwargs : Additional keyword arguments.
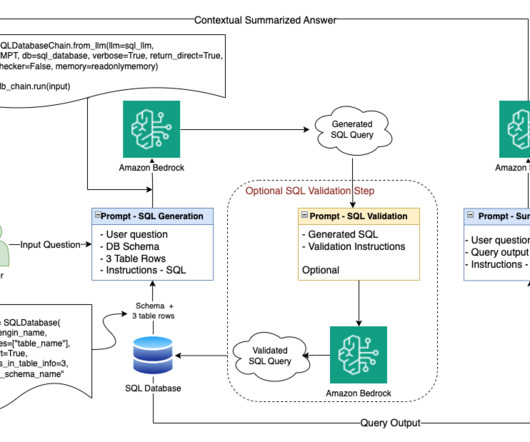
Text to SQL: Using natural language to enhance query authoring SQL is a complex language that requires an understanding of databases, tables, syntaxes, and metadata. The way you craft a prompt can profoundly influence the nature and usefulness of the AI’s response. Bosco Albuquerque is a Sr.
', args_schema=None, return_direct=False, verbose=False, callbacks=None, callback_manager=None, tags=None, metadata=None, handle_tool_error=False, api_wrapper=WikipediaAPIWrapper(wiki_client=<module 'wikipedia' from '/usr/local/lib/python3.10/dist-packages/wikipedia/__init__.py'>, Input should be a search query.',
Even if the text is cleaner, other aspects, like how the loader interfaces with the language model, the handling of metadata, and the overall synergy with the RAG process, are crucial. We’re committed to supporting and inspiring developers and engineers from all walks of life.
This gives you access to metadata like the number of tokens used. Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for datascience, machine learning, and deep learning practitioners.
As you’ve been running the ML data platform team, how do you do that? How do you know whether the platform we are building, the tools we are providing to datascience teams, or data teams are bringing value? If you can be data-driven, that is the best. Depending on your size, you might have a data catalog.
We used Streamlit , a library for quickly building graphical interfaces for datascience projects – it does not allow a high level of customization, but it allows you to quickly present visual results which greatly simplifies communication, especially with less technically-oriented people.
Iris was designed to use machine learning (ML) algorithms to predict the next steps in building a data pipeline. By analyzing millions of metadata elements and data flows, Iris could make intelligent suggestions to users, democratizing data integration and allowing even those without a deep technical background to create complex workflows.
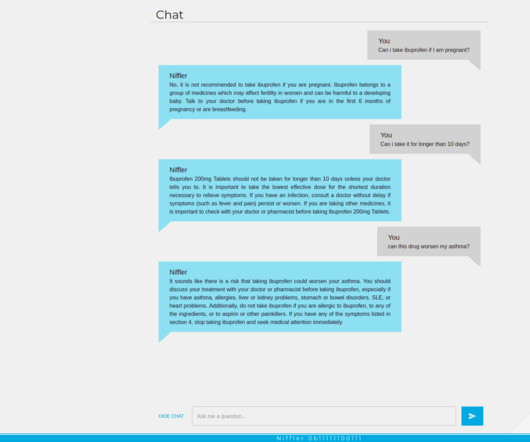
By using a combination of transcript preprocessing, promptengineering, and structured LLM output, we enable the user experience shown in the following screenshot, which demonstrates the conversion of LLM-generated timestamp citations into clickable buttons (shown underlined in red) that navigate to the correct portion of the source video.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content