This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The field of datascience has evolved dramatically over the past several years, driven by technological breakthroughs, industry demands, and shifting priorities within the community. DataEngineerings SteadyGrowth 20182021: Dataengineering was often mentioned but overshadowed by modeling advancements.
Programming for DataScience with Python This course series teaches essential programming skills for data analysis, including SQL fundamentals for querying databases and Unix shell basics. Students also learn Python programming, from fundamentals to data manipulation with NumPy and Pandas, along with version control using Git.
Data Scientists and ML Engineers typically write lots and lots of code. From writing code for doing exploratory analysis, experimentation code for modeling, ETLs for creating training datasets, Airflow (or similar) code to generate DAGs, REST APIs, streaming jobs, monitoring jobs, etc.
The rapid evolution of AI is transforming nearly every industry/domain, and softwareengineering is no exception. But how so with softwareengineering you may ask? These technologies are helping engineers accelerate development, improve software quality, and streamline processes, just to name a few.
They’ll also work with softwareengineers to ensure that the data infrastructure is scalable and reliable. These professionals will work with their colleagues to ensure that data is accessible, with proper access. So let’s go through each step one by one, and help you build a roadmap toward becoming a dataengineer.
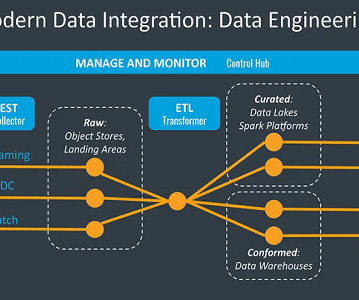
Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Big Data Technologies: Hadoop, Spark, etc.
Data Warehouses and Relational Databases It is essential to distinguish data lakes from data warehouses and relational databases, as each serves different purposes and has distinct characteristics. Schema Enforcement: Data warehouses use a “schema-on-write” approach. You can connect with her on Linkedin.
The embeddings are captured in Amazon Simple Storage Service (Amazon S3) via Amazon Kinesis Data Firehose , and we run a combination of AWS Glue extract, transform, and load (ETL) jobs and Jupyter notebooks to perform the embedding analysis. Set the parameters for the ETL job as follows and run the job: Set --job_type to BASELINE.
Over the past few years DataScience has MIGRATED from individual computers to service cloud platforms. I just finished learning Azure’s service cloud platform using Coursera and the Microsoft Learning Path for DataScience. It will take a couple of months but it is worth it!
About the authors Samantha Stuart is a Data Scientist with AWS Professional Services, and has delivered for customers across generative AI, MLOps, and ETL engagements. He has touched on most aspects of these projects, from infrastructure and DevOps to software development and AI/ML.
Stefan is a softwareengineer, data scientist, and has been doing work as an ML engineer. He also ran the data platform in his previous company and is also co-creator of open-source framework, Hamilton. As you’ve been running the ML data platform team, how do you do that?
As such, it is crucial to have a system in place for tracking and managing changes to data over time. This is where data versioning comes in. In both cases, the main goal of the data version control system is to track and manage changes to data over time.
About the Authors Christopher Diaz is a Lead R&D Engineer at CCC Intelligent Solutions. Christopher earned his Bachelor of Science in Computer Science from Northeastern Illinois University. Emmy Award winner Sam Kinard is a Senior Manager of SoftwareEngineering at CCC Intelligent Solutions.
These connections are used by AWS Glue crawlers, jobs, and development endpoints to access various types of data stores. You can use these connections for both source and target data, and even reuse the same connection across multiple crawlers or extract, transform, and load (ETL) jobs. You can find Pranav on LinkedIn.
Let’s combine these suggestions to improve upon our original prompt: Human: Your job is to act as an expert on ETL pipelines. Specifically, your job is to create a JSON representation of an ETL pipeline which will solve the user request provided to you.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content