This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For example, in the bank marketing use case, the management account would be responsible for setting up the organizational structure for the bank’s data and analytics teams, provisioning separate accounts for data governance, data lakes, and datascience teams, and maintaining compliance with relevant financial regulations.
DevSecOps includes all the characteristics of DevOps, such as faster deployment, automated pipelines for build and deployment, extensive testing, etc., Data security must begin by understanding whether the collected data is compliant with data protection regulations such as GDPR or HIPAA.
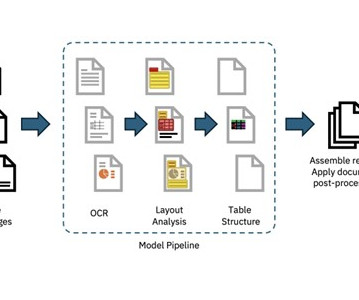
Each text, including the rotated text on the left of the page, is identified and extracted as a stand-alone text element with coordinates and other metadata that makes it possible to render a document very close to the original PDF but from a structured JSONformat.
Lived through the DevOps revolution. Founded neptune.ai , a modular MLOps component for ML metadata store , aka “experiment tracker + model registry”. If you’d like a TLDR, here it is: MLOps is an extension of DevOps. There will be only one type of ML metadata store (model-first), not three. Came to ML from software.
Data Scientist at AWS, bringing a breadth of datascience, ML engineering, MLOps, and AI/ML architecting to help businesses create scalable solutions on AWS. He is a technology enthusiast and a builder with a core area of interest in AI/ML, data analytics, serverless, and DevOps. About the Authors Joe King is a Sr.
These and many other questions are now on top of the agenda of every datascience team. To quantify how well your models are doing, DataRobot provides you with a comprehensive set of datascience metrics — from the standards (Log Loss, RMSE) to the more specific (SMAPE, Tweedie Deviance). Learn More About DataRobot MLOps.
It automatically keeps track of model artifacts, hyperparameters, and metadata, helping you to reproduce and audit model versions. As you move from pilot and test phases to deploying generative AI models at scale, you will need to apply DevOps practices to ML workloads.
With built-in components and integration with Google Cloud services, Vertex AI simplifies the end-to-end machine learning process, making it easier for datascience teams to build and deploy models at scale. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy datascience projects.
It combines principles from DevOps, such as continuous integration, continuous delivery, and continuous monitoring, with the unique challenges of managing machine learning models and datasets. It provides a collaborative environment for datascience teams, enabling automation of ML workflows and continuous monitoring of models in production.
The functional architecture with different capabilities is implemented using a number of AWS services, including AWS Organizations , SageMaker, AWS DevOps services, and a data lake. The architecture maps the different capabilities of the ML platform to AWS accounts.
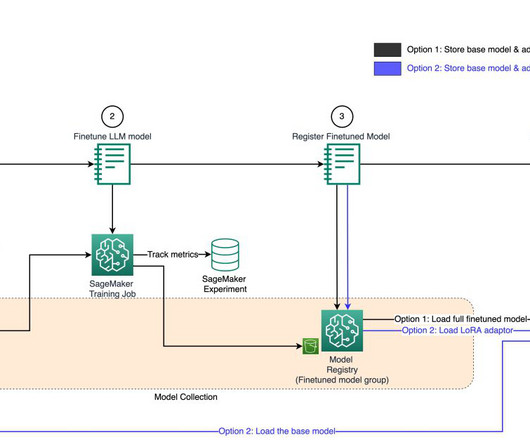
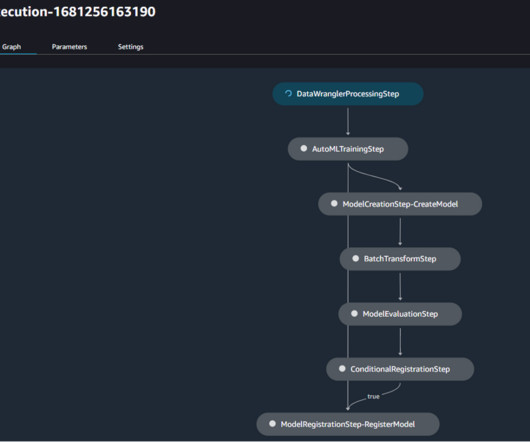
model.create() creates a model entity, which will be included in the custom metadata registered for this model version and later used in the second pipeline for batch inference and model monitoring. In Studio, you can choose any step to see its key metadata. large", accelerator_type="ml.eia1.medium", large", accelerator_type="ml.eia1.medium",
This, and the extendability of MLflow, sees datascience teams gravitating towards adopting it as their end-to-end machine learning solution. Estimating the costs of hosting MLflow for a datascience team can be difficult. The metadata store is where MLflow keeps the experiment and model metadata.
These teams are as follows: Advanced analytics team (data lake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
The examples focus on questions on chunk-wise business knowledge while ignoring irrelevant metadata that might be contained in a chunk. He has touched on most aspects of these projects, from infrastructure and DevOps to software development and AI/ML. You can customize the prompt examples to fit your ground truth use case.
These files contain metadata, current state details, and other information useful in planning and applying changes to infrastructure. It helps to observe datascience principles in working with these files. This is critical especially when multiple DevOps team members are working on the configuration.
Model cards are intended to be a single source of truth for business and technical metadata about the model that can reliably be used for auditing and documentation purposes. Depending on your governance requirements, DataScience & Dev accounts can be merged into a single AWS account.
This data version is frequently recorded into your metadata management solution to ensure that your model training is versioned and repeatable. It’s time to examine the best data version control tools on the market so you can keep track of each component of your code. You may check for version control on an exabyte scale.
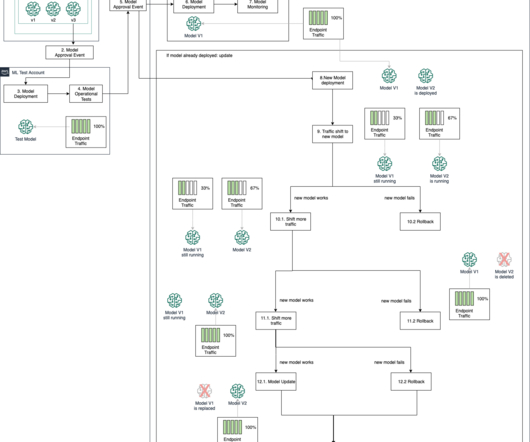
Data scientists, ML engineers, IT staff, and DevOps teams must work together to operationalize models from research to deployment and maintenance. We create an automated model build pipeline that includes steps for data preparation, model training, model evaluation, and registration of the trained model in the SageMaker Model Registry.
In this example, a model is developed in SageMaker using SageMaker Processing jobs to run data processing code that is used to prepare data for an ML algorithm. SageMaker Training jobs are then used to train an ML model on the data produced by the processing job.
Building a tool for managing experiments can help your data scientists; 1 Keep track of experiments across different projects, 2 Save experiment-related metadata, 3 Reproduce and compare results over time, 4 Share results with teammates, 5 Or push experiment outputs to downstream systems.
It provides the flexibility to log your model metrics, parameters, files, artifacts, plot charts from the different metrics, capture various metadata, search through them and support model reproducibility. Data scientists can quickly compare the performance and hyperparameters for model evaluation through visual charts and tables.
MLflow can be seen as a tool that fits within the MLOps (synonymous with DevOps) framework. The reason is that most of the traditional datascience practices involve manual workflows, leading to issues during deployment. This involves running an MLflow server with specified database and file storage locations.
Model cards are intended to be a single source of truth for business and technical metadata about the model that can reliably be used for auditing and documentation purposes. Depending on your governance requirements, DataScience & Dev accounts can be merged into a single AWS account.
So I was able to get from growth hacking to data analytics, then data analytics to datascience, and then datascience to MLOps. I switched from analytics to datascience, then to machine learning, then to data engineering, then to MLOps. How do I get this model in production?
As you’ve been running the ML data platform team, how do you do that? How do you know whether the platform we are building, the tools we are providing to datascience teams, or data teams are bringing value? If you can be data-driven, that is the best. Depending on your size, you might have a data catalog.
Here, the component will also return statistics and metadata that help you understand if the model suits the target deployment environment. Model deployment You can deploy the packaged and registered model to a staging environment (as traditional software with DevOps) or the production environment. Kale v0.7.0. Happy pipelining!
Amazon SageMaker is a fully managed service to prepare data and build, train, and deploy machine learning (ML) models for any use case with fully managed infrastructure, tools, and workflows. When the template is available in SageMaker, the DataScience Lead uses the template to create a SageMaker project.
To make that possible, your data scientists would need to store enough details about the environment the model was created in and the related metadata so that the model could be recreated with the same or similar outcomes. Your ML platform must have versioning in-built because code and data mostly make up the ML system.
TR’s AI Platform microservices are built with Amazon SageMaker as the core engine, AWS serverless components for workflows, and AWS DevOps services for CI/CD practices. Increase transparency and collaboration by creating a centralized view of all models across TR alongside metadata and health metrics. Model deployment.
Fine-tuning process and human validation The fine-tuning and validation process consisted of the following steps: Gathering a malware dataset To cover the breadth of malware techniques, families, and threat types, we collected a large dataset of malware samples, each with technical metadata.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content