This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Having spent years in management consulting at Deloitte and corporate development at Tata Group, I encountered the same challenges over and over manual, repetitive research, datascarcity in private markets, and the sheer grunt work that slows down analysts and decision-makers.
GenAI can help by automatically clustering similar data points and inferring labels from unlabeled data, obtaining valuable insights from previously unusable sources. NaturalLanguageProcessing (NLP) is an example of where traditional methods can struggle with complex text data.
Introduction The field of naturallanguageprocessing (NLP) and language models has experienced a remarkable transformation in recent years, propelled by the advent of powerful large language models (LLMs) like GPT-4, PaLM, and Llama. The implications of SaulLM-7B's success extend far beyond academic benchmarks.
This approach has driven significant advancements in areas like naturallanguageprocessing, computer vision, and predictive analytics. However, as the availability of real-world data reaches its limits , synthetic data is emerging as a critical resource for AI development.
Encoder models like BERT and RoBERTa have long been cornerstones of naturallanguageprocessing (NLP), powering tasks such as text classification, retrieval, and toxicity detection. DataScarcity: Pre-training on small datasets (e.g., Wikipedia + BookCorpus) restricts knowledge diversity.
Large language models (LLMs) are at the forefront of technological advancements in naturallanguageprocessing, marking a significant leap in the ability of machines to understand, interpret, and generate human-like text. Similarly, on the CaseHOLD dataset, there was a 32.6% enhancement, and on SNIPS, a 32.0%
While deep learning methods have made significant strides in this domain, they often rely on large and diverse datasets to enhance feature learning, a strategy commonly employed in naturallanguageprocessing and 2D vision. Check out the Paper and Github.
With the significant advancement in the fields of Artificial Intelligence (AI) and NaturalLanguageProcessing (NLP), Large Language Models (LLMs) like GPT have gained attention for producing fluent text without explicitly built grammar or semantic modules.
Machine translation, an integral branch of NaturalLanguageProcessing, is continually evolving to bridge language gaps across the globe. One persistent challenge is the translation of low-resource languages, which often need more substantial data for training robust models.
Multilingual naturallanguageprocessing (NLP) is a rapidly advancing field that aims to develop language models capable of understanding & generating text in multiple languages. These models facilitate effective communication and information access across diverse linguistic backgrounds.
GANs are a proven technique for creating realistic, high-quality synthetic data. Distilabel is a scalable, efficient, and flexible solution suitable for various AI applications, including image classification, naturallanguageprocessing, and medical imaging.
The rapid advancement of large language models has ushered in a new era of naturallanguageprocessing capabilities. However, a significant challenge persists: most of these models are primarily trained on a limited set of widely spoken languages, leaving a vast linguistic diversity unexplored.
Subsequently, a team of researchers from South Korea has developed a method called LP-MusicCaps (Large language-based Pseudo music caption dataset), creating a music captioning dataset by applying LLMs carefully to tagging datasets. This resulted in the generation of approximately 2.2M captions paired with 0.5M audio clips.
These technologies have revolutionized computer vision, robotics, and naturallanguageprocessing and played a pivotal role in the autonomous driving revolution. Over the past decade, advancements in deep learning and artificial intelligence have driven significant strides in self-driving vehicle technology.
Synthetic data , artificially generated to mimic real data, plays a crucial role in various applications, including machine learning , data analysis , testing, and privacy protection. However, generating synthetic data for NLP is non-trivial, demanding high linguistic knowledge, creativity, and diversity.
On various NaturalLanguageProcessing (NLP) tasks, Large Language Models (LLMs) such as GPT-3.5 They optimize the LVLM using synthesized anomalous visual-textual data and incorporating IAD expertise. Direct training using IAD data, however, needs to be improved. Datascarcity is the first.
The ability to translate spoken words into another language in real time is known as simultaneous speech translation, and it paves the way for instantaneous communication across language barriers. There has been a lot of buzz about machine-assisted autonomous interpretation in naturallanguageprocessing (NLP).
A key finding is that for a fixed compute budget, training with up to four epochs of repeated data shows negligible differences in loss compared to training with unique data. The paper also explores alternative strategies to mitigate datascarcity.
Large language models (LLMs) have revolutionized naturallanguageprocessing (NLP), particularly for English and other data-rich languages. However, this rapid advancement has created a significant development gap for underrepresented languages, with Cantonese being a prime example.
By leveraging auxiliary information such as semantic attributes, ZSL enhances scalability, reduces data dependency, and improves generalisation. This innovative approach is transforming applications in computer vision, NaturalLanguageProcessing, healthcare, and more.
Summary: Small Language Models (SLMs) are transforming the AI landscape by providing efficient, cost-effective solutions for NaturalLanguageProcessing tasks. What Are Small Language Models (SLMs)? Frequently Asked Questions What is a Small Language Model (SLM)?
Large Language Models (LLMs) have revolutionized naturallanguageprocessing in recent years. These approaches have shown exceptional performance across various tasks, including language generation, understanding, and domain-specific applications.
Deep Learning algorithms have become integral to modern technology, from image recognition to NaturalLanguageProcessing. For instance, a model trained on MTL can predict multiple medical conditions from patient data, such as diagnosing diseases and estimating prognosis simultaneously. What is Tokenization in NLP?
Although fine-tuning with a large amount of high-quality original data remains the ideal approach, our findings highlight the promising potential of synthetic data generation as a viable solution when dealing with datascarcity. Yiyue holds a Ph.D.
It helps in overcoming some of the drawbacks and bottlenecks of Machine Learning: Datascarcity: Transfer Learning technology doesn’t require reliance on larger data sets. This technology allows models to be fine-tuned using a limited amount of data. Thus it is computationally lesser expensive.
Highlighted work from our institute appearing at this year’s EMNLP conference Empirical Methods in NaturalLanguageProcessing ( EMNLP ) is a leading conference in naturallanguageprocessing and artificial intelligence. Hearst, Daniel S.
Illustration of a few-shot segmentation process. Segment Anything Model (SAM) Inspired by the success of prompting techniques utilized in the field of naturallanguageprocessing, researchers from Meta AI proposed the Segment Anything Model (SAM), which aims to perform image segmentation based on segmentation prompts.
Deep Dive: Convolutional Neural Network Algorithms for Specific Challenges CNNs, while powerful, face distinct challenges in their application, particularly in scenarios like datascarcity, overfitting, and unstructured data environments.
By marrying the disciplines of computer vision, naturallanguageprocessing, mechanics, and physics, we are bound to see a frameshift change in the way we interact with, and are assisted by robot technology. It’s capable of scalable, photorealistic data generation that includes accurate annotations for training.
By marrying the disciplines of computer vision, naturallanguageprocessing, mechanics, and physics, we are bound to see a frameshift change in the way we interact with, and are assisted by robot technology. It’s capable of scalable, photorealistic data generation that includes accurate annotations for training.
Instead of relying on organic events, we generate this data through computer simulations or generative models. Synthetic data can augment existing datasets, create new datasets, or simulate unique scenarios. Specifically, it solves two key problems: datascarcity and privacy concerns.
It addresses issues in traditional end-to-end models, like datascarcity and lack of melody control, by separating lyric-to-template and template-to-melody processes. This approach enables high-quality, controllable melody generation with minimal lyric-melody paired data.
Democratisation of Data : Non-technical users can engage with advanced analytics tools, fostering a culture of data-driven decision-making across all levels of an organisation. This technology helps overcome challenges related to datascarcity and bias by generating realistic data that mimics real-world scenarios.
Disease Diagnosis Generative AI enhances disease diagnosis by enhancing the accuracy and efficiency of interpreting data. Healthcare NLP (NaturalLanguageProcessing) technologies extract insights from physician records, patient histories and diagnostic reports facilitating precise diagnosis. This improves access to care.
Illustration of a few-shot segmentation process. Segment Anything Model (SAM) Inspired by the success of prompting techniques utilized in the field of naturallanguageprocessing, researchers from Meta AI proposed the Segment Anything Model (SAM), which aims to perform image segmentation based on segmentation prompts.
Disease Diagnosis Generative AI enhances disease diagnosis by enhancing the accuracy and efficiency of interpreting data. Healthcare NLP (NaturalLanguageProcessing) technologies extract insights from physician records, patient histories and diagnostic reports facilitating precise diagnosis. This improves access to care.
Unlike naturallanguageprocessing or vision-based AI, this area uniquely combines structured logic with the creative elements of human-like reasoning, holding the promise of transformative advancements. This has created a critical need for new approaches to bridge these gaps.
Overcoming datascarcity with translation and synthetic data generation When fine-tuning a custom version of the Mistral 7B LLM for the Italian language, Fastweb faced a major obstacle: high-quality Italian datasets were extremely limited or unavailable.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






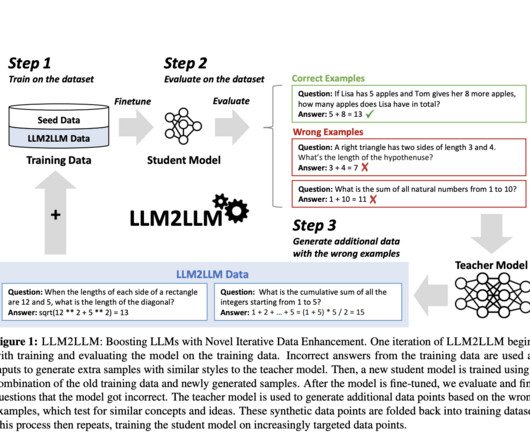
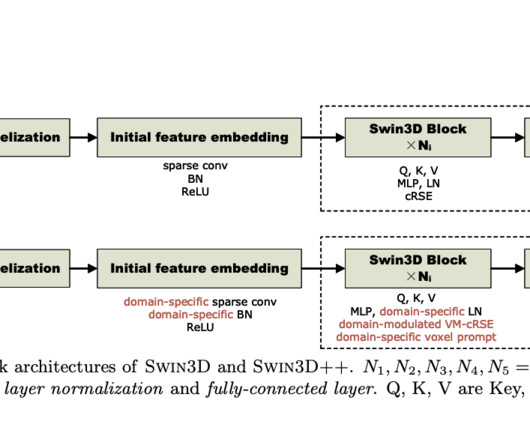

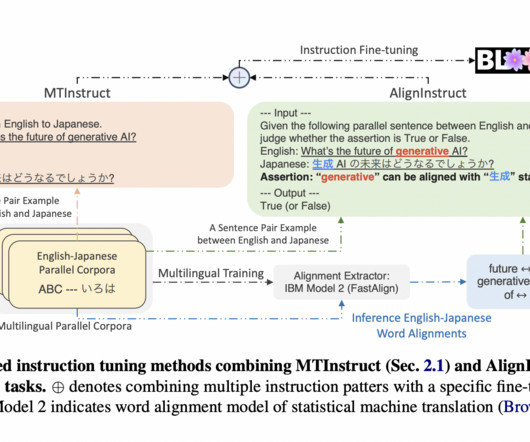
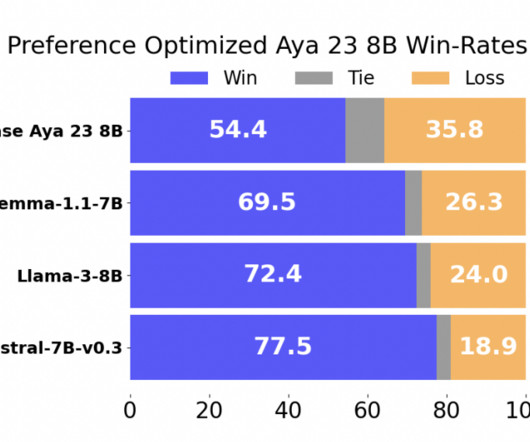



























Let's personalize your content