
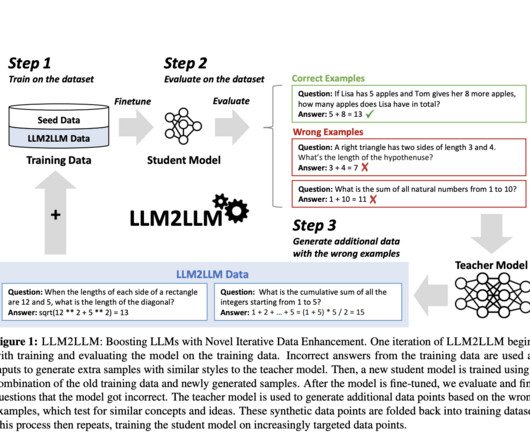
LLM2LLM: UC Berkeley, ICSI and LBNL Researchers’ Innovative Approach to Boosting Large Language Model Performance in Low-Data Regimes with Synthetic Data
Marktechpost
MARCH 26, 2024
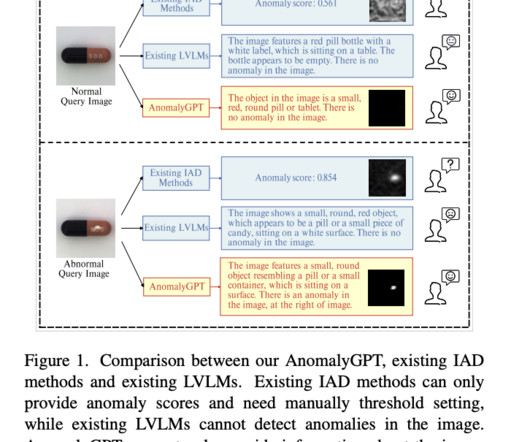
Large language models (LLMs) are at the forefront of technological advancements in natural language processing, marking a significant leap in the ability of machines to understand, interpret, and generate human-like text. Similarly, on the CaseHOLD dataset, there was a 32.6% enhancement, and on SNIPS, a 32.0%
















Let's personalize your content