This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By leveraging GenAI, we can streamline and automate data-cleaning processes: Clean data to use AI? Clean data through GenAI! Three ways to use GenAI for better data Improving data quality can make it easier to apply machinelearning and AI to analytics projects and answer business questions.
In the rapidly evolving landscape of artificial intelligence, the quality and quantity of data play a pivotal role in determining the success of machinelearning models. While real-world data provides a rich foundation for training, it often faces limitations such as scarcity, bias, and privacy concerns.
While deep learning methods have made significant strides in this domain, they often rely on large and diverse datasets to enhance feature learning, a strategy commonly employed in naturallanguageprocessing and 2D vision. Check out the Paper and Github.
Synthetic data , artificially generated to mimic real data, plays a crucial role in various applications, including machinelearning , data analysis , testing, and privacy protection. However, generating synthetic data for NLP is non-trivial, demanding high linguistic knowledge, creativity, and diversity.
Over the past decade, advancements in deep learning and artificial intelligence have driven significant strides in self-driving vehicle technology. These technologies have revolutionized computer vision, robotics, and naturallanguageprocessing and played a pivotal role in the autonomous driving revolution.
Machine translation, an integral branch of NaturalLanguageProcessing, is continually evolving to bridge language gaps across the globe. One persistent challenge is the translation of low-resource languages, which often need more substantial data for training robust models.
Privacy Auditing with One (1) Training Run By Thomas Steinke , Milad Nasr , and Matthew Jagielski from Google This research paper introduces a novel method for auditing differentially private (DP) machinelearning systems using just a single training run. The paper also explores alternative strategies to mitigate datascarcity.
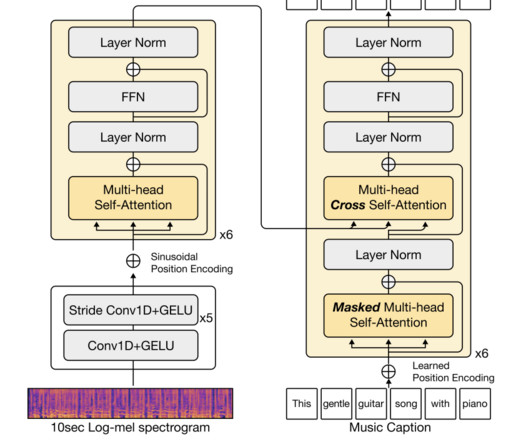
Subsequently, a team of researchers from South Korea has developed a method called LP-MusicCaps (Large language-based Pseudo music caption dataset), creating a music captioning dataset by applying LLMs carefully to tagging datasets. This resulted in the generation of approximately 2.2M captions paired with 0.5M audio clips.
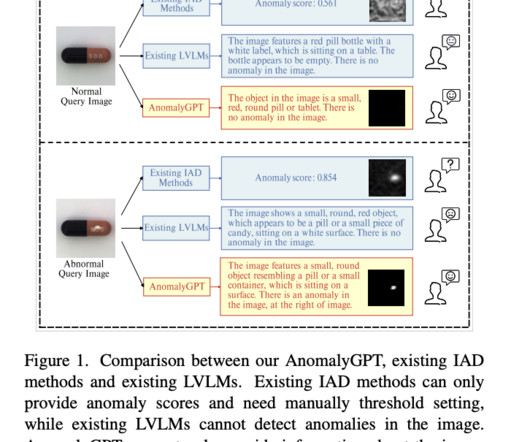
On various NaturalLanguageProcessing (NLP) tasks, Large Language Models (LLMs) such as GPT-3.5 With just a few normal samples, AnomalyGPT can also learn in context, allowing for quick adjustment to new objects. They optimize the LVLM using synthesized anomalous visual-textual data and incorporating IAD expertise.
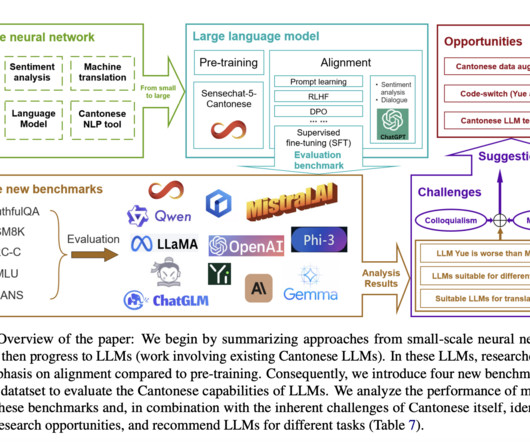
Large language models (LLMs) have revolutionized naturallanguageprocessing (NLP), particularly for English and other data-rich languages. However, this rapid advancement has created a significant development gap for underrepresented languages, with Cantonese being a prime example.
By leveraging auxiliary information such as semantic attributes, ZSL enhances scalability, reduces data dependency, and improves generalisation. This innovative approach is transforming applications in computer vision, NaturalLanguageProcessing, healthcare, and more.
Although fine-tuning with a large amount of high-quality original data remains the ideal approach, our findings highlight the promising potential of synthetic data generation as a viable solution when dealing with datascarcity. Yiyue holds a Ph.D. Outside of work, she enjoys sports, hiking, and traveling.
What if we say that you have the option of using a pre-trained model that works as a framework for data training? Yes, Transfer Learning is the answer to it. What is Transfer Learning? Transfer Learning is a technique in MachineLearning where a model is pre-trained on a large and general task.
Multi-Task Learning Deep Learning is a towering pillar in the vast landscape of artificial intelligence, revolutionising various domains with remarkable capabilities. Deep Learning algorithms have become integral to modern technology, from image recognition to NaturalLanguageProcessing.
Summary: Small Language Models (SLMs) are transforming the AI landscape by providing efficient, cost-effective solutions for NaturalLanguageProcessing tasks. With innovations in model compression and transfer learning, SLMs are being applied across diverse sectors. What Are Small Language Models (SLMs)?
Supervised learning Supervised learning is a widely used approach in machinelearning, where algorithms are trained using a large number of input examples paired with their corresponding expected outputs. Illustration of a few-shot segmentation process. Different segmentation types. Source: own study.
Access to synthetic data is valuable for developing effective artificial intelligence (AI) and machinelearning (ML) models. Real-world data often poses significant challenges, including privacy, availability, and bias. To address these challenges, we introduce synthetic data as an ML model training solution.
Highlighted work from our institute appearing at this year’s EMNLP conference Empirical Methods in NaturalLanguageProcessing ( EMNLP ) is a leading conference in naturallanguageprocessing and artificial intelligence. Hearst, Daniel S.
Deep Dive: Convolutional Neural Network Algorithms for Specific Challenges CNNs, while powerful, face distinct challenges in their application, particularly in scenarios like datascarcity, overfitting, and unstructured data environments.
By marrying the disciplines of computer vision, naturallanguageprocessing, mechanics, and physics, we are bound to see a frameshift change in the way we interact with, and are assisted by robot technology. It’s capable of scalable, photorealistic data generation that includes accurate annotations for training.
By marrying the disciplines of computer vision, naturallanguageprocessing, mechanics, and physics, we are bound to see a frameshift change in the way we interact with, and are assisted by robot technology. It’s capable of scalable, photorealistic data generation that includes accurate annotations for training.
They advocate for the importance of transparency, informed consent protections, and the use of health information exchanges to avoid data monopolies and to ensure equitable benefits of Gen AI across different healthcare providers and patients. However as AI technology progressed its potential within the field also grew.
Supervised learning Supervised learning is a widely used approach in machinelearning, where algorithms are trained using a large number of input examples paired with their corresponding expected outputs. Illustration of a few-shot segmentation process. Different segmentation types. Source: own study.
They advocate for the importance of transparency, informed consent protections, and the use of health information exchanges to avoid data monopolies and to ensure equitable benefits of Gen AI across different healthcare providers and patients. However as AI technology progressed its potential within the field also grew.
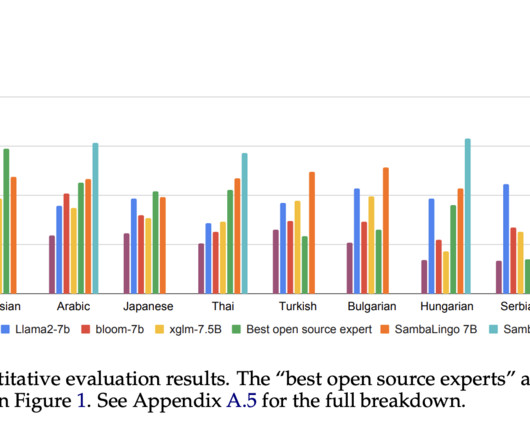
The rapid advancement of large language models has ushered in a new era of naturallanguageprocessing capabilities. However, a significant challenge persists: most of these models are primarily trained on a limited set of widely spoken languages, leaving a vast linguistic diversity unexplored. Million AI Audience?
Large Language Models (LLMs) have revolutionized naturallanguageprocessing in recent years. These approaches have shown exceptional performance across various tasks, including language generation, understanding, and domain-specific applications.
Summary: The future of Data Science is shaped by emerging trends such as advanced AI and MachineLearning, augmented analytics, and automated processes. As industries increasingly rely on data-driven insights, ethical considerations regarding data privacy and bias mitigation will become paramount.
It’s used to generate cohesive and creative song lyrics, contributing to the songwriting process. It focuses on generating hip-hop rap lyrics, utilizing NLP and machinelearning techniques to produce rhythmically and thematically coherent verses. Lyric Generation ( DeepRapper ): DeepRapper is an AI-based lyric generation tool.
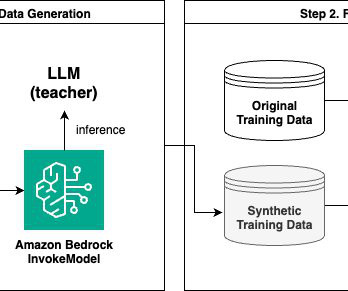
With a vision to build a large language model (LLM) trained on Italian data, Fastweb embarked on a journey to make this powerful AI capability available to third parties. To tackle this datascarcity challenge, Fastweb had to build a comprehensive training dataset from scratch to enable effective model fine-tuning.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content